本文档面向 SRE / 平台工程师,介绍如何将 HAMi 平台版 部署到 Kubernetes 集群,并完成与 HAMi、Prometheus、NVIDIA GPU Operator、Gateway API 等基础组件的对接。
⚠️ 安装 ≠ 激活
完成本节的 Helm 安装后,HAMi 平台版的组件会运行,但 HAMi Enterprise 底层的 GPU 虚拟化与调度功能需要激活证书后才能正常使用。
安装过程本身不依赖证书,您可以先完成部署,再通过后续步骤申请并导入证书。简而言之:先装软件,后拿证书;不激活则 vGPU 切分与调度功能不可用,验证也会失败。
架构与定位
HAMi 平台版(密瓜智能异构算力调度、虚拟化系统)是部署在 Kubernetes 集群之上的应用平台,提供异构算力的统一调度、租户配额、监控可视化与开发者工作空间。其核心特征:
- 控制平面联邦:连接到云端 HAMi 企业平台控制平面,单租户管理多个集群
- 统一管理界面:内置管理、监控、用户控制台
- 开放可对接:依赖标准 K8s 生态(Prometheus、Helm、Gateway API、HAMi device plugin)
适用场景:多租户 GPU 共享、显存超卖、异构加速卡(NVIDIA / Ascend / Hygon DCU 等)统一调度,以及开发者工作空间、联邦集群管理。
前置条件清单
请在 每个待接入的 Kubernetes 集群 上完成以下检查:
| 类型 | 要求 | 验证命令 |
|---|---|---|
| Kubernetes | ≥ 1.24 | kubectl version --short |
| 容器运行时 | containerd 或 Docker | kubectl get nodes -o wide |
| Helm | ≥ 3.14 | helm version --short |
| GPU 驱动 | NVIDIA driver ≥ 470(推荐 ≥ 550) | nvidia-smi |
| Prometheus | ≥ 2.37(如需对接监控) | kubectl get pods -A | grep prom |
| GPU Operator | 已安装且 devicePlugin.enabled = false,推荐版本:v25.3.2) | helm list -A | grep gpu-operator |
| 集群存储 | 默认 StorageClass 已配置或自行维护 PVC | kubectl get sc |
关键约束:HAMi 自带 device-plugin,与 NVIDIA GPU Operator 内置 device-plugin 冲突。若已安装 GPU Operator,务必通过
--set devicePlugin.enabled=false禁用其内置 plugin。
安装 HAMi Enterprise
HAMi 平台版依赖 HAMi Enterprise 作为底层 GPU 虚拟化与调度层。请先完成 HAMi Enterprise 的部署与激活。
两种安装路径,按场景选:
- 在线 OCI 安装(评估、PoC、可通外部网络的集群)
- All-in-One 离线一体包(金融/政府/运营商等隔离网络场景)
无论如何安装,最后都需要申请证书并激活。
路径 A:在线 OCI chart 安装
如果希望使用国内镜像仓库,请联系 Dynamia.ai 的售前/技术支持获取相关信息。
推荐使用版本追踪系统维护集群中所有 Helm release 的 values 文件。 通过使用 -f example-values.yaml 覆盖 chart 中默认 values 中与之相对应的 key。
选择好 kubeconfig context 后,开始操作:
如果没有安装过 nvidia/gpu-operator,先安装。
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo update
helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
--set devicePlugin.enabled=false \
--set dcgmExporter.serviceMonitor.enabled=true \
--version=v25.3.2
如果集群里没有 Prometheus 等监控栈,还需要安装,这里展示 prometheus-community/kube-prometheus-stack 的安装方法。
helm install prometheus \
oci://ghcr.io/prometheus-community/charts/kube-prometheus-stack \
--version 72.3.0 \
--namespace monitoring \
--create-namespace \
--set alertmanager.enabled=false \
--set grafana.enabled=false
安装 dynamia-ai/hami-enterprise(hami-commercial):
helm install hami \
oci://ghcr.io/dynamia-ai/hami-commercial/hami \
--version 2.9.0-rc1 \
--namespace hami-system \
--create-namespace
hami-enterprise(hami-commercial) 常见 Chart 自定义选项如下表,完整 values 配置请见:HAMi Helm Values Reference。
| 参数 | 说明 | 默认值 |
|---|---|---|
dra.enabled | 是否部署启用 DRA | false |
scheduler.leaderElect | 是否启用hami-scheduler的多节点选举 | true |
scheduler.replicas | 调整 hami-scheduler的实例数量 | 1 |
scheduler.kubeScheduler.image.registry | hami-scheduler所使用的kube-scheduler镜像仓库。 | "registry.cn-hangzhou.aliyuncs.com" |
scheduler.kubeScheduler.image.repository | hami-scheduler所使用的kube-scheduler镜像名称。 | "scheduler.kubeScheduler.image.repository" |
scheduler.kubeScheduler.image.tag | hami-scheduler所使用的kube-scheduler镜像版本。如果不填,chart 会推算一个合适的版本。 | "" |
(可选)安装 envoyproxy/envoy-gateway 用于暴露服务:
helm install eg \
oci://docker.io/envoyproxy/gateway-helm \
--version v1.6.2 \
--namespace envoy-gateway-system \
--create-namespace \
--set global.images.envoyGateway.image=docker.io/envoyproxy/gateway:v1.6.2 \
--set global.image.ratelimit.image=docker.io/envoyproxy/ratelimit:99d85510 \
--set config.envoyGateway.gateway.controllerName=gateway.envoyproxy.io/gatewayclass-controller \
--set config.envoyGateway.provider.type=Kubernetes
安装 dynamia-ai/hami-ai-platform(kantaloupe):
helm install kantaloupe \
oci://ghcr.io/dynamia-ai/kantaloupe/kantaloupe-chart \
--version 0.15.1 \
--namespace kantaloupe-system \
--create-namespace \
--set fullnameOverride=kantaloupe
hami-ai-platform(kantaloupe) 由于需要配置“功能特性”,“服务暴露”,“采集监控指标”等事项,配置自由度较高,请按需配置。
hami-ai-platform(kantaloupe) 常见 Chart 自定义选项如下表,完整 values 配置请见:HAMi AI Platform Helm Values Reference。
| 参数 | 说明 | 默认值 |
|---|---|---|
gateway.enabled | 是否创建 Gateway API 资源并集成 envoy-gateway | true |
gateway.service.type | Gateway Service 类型,可选 LoadBalancer、NodePort | LoadBalancer |
gateway.service.nodePort | 当 type 为 NodePort 时使用的 HTTP 节点端口 | 30080 |
gateway.tls.enabled | 是否启用 HTTPS/TLS 终止 | false |
gateway.tls.secretName | TLS 证书所在的 Secret 名称 | cloudflare-origin-tls |
gateway.endpoint | 控制平面使用的外部网关基础 URL(如 https://dashboard.example.com)。设置后 controller-manager 会直接使用该地址,不再从 Gateway 状态自动发现。 | "" |
gateway.hostnames | Gateway 监听的主机名列表 | [] |
auth.enabled | 是否启用平台认证(JWT 登录、RBAC、审计) | false |
auth.bootstrapAdminUsername | 初始平台管理员用户名 | "" |
auth.existingAuthSecret | 包含 jwt-secret 和 bootstrap-admin-password 的现有 Secret 名称(生产环境推荐) | "" |
monitoring.enabled | 是否创建 ServiceMonitor、PrometheusRule 等监控资源 | true |
monitoring.namespace | 监控资源(ServiceMonitor 等)所在的命名空间 | monitoring |
hamiNamespace | 已安装的 HAMi Enterprise 所在的命名空间 | hami-system |
controllerManager.replicaCount | controller-manager 副本数 | 1 |
installCRDs | 是否在安装时创建/更新 CRD 资源 | true |
fullnameOverride | 覆盖所有资源名称前缀 | kantaloupe |
常见的配置 values 示例:
- 云厂商环境,可以使用 LoadBalancer 暴露服务
gateway:
enabled: true
endpoint: your.domain
service:
type: LoadBalancer
tls:
enabled: true
secretName: your-tls-secret
httpRedirect: true
hostnames:
- your.domain
- 脱网环境,使用 envoy-gateway NodePort 暴露服务
gateway:
enabled: true
service:
type: NodePort
nodePort: 30080
tls:
enabled: false
- 不使用额外配置
gateway:
enabled: false
路径 B:All-in-One 离线一体包
请联系 Dynamia.ai 的售前/技术支持获取下载地址。
下载 hami-ai-platform-v<VERSION>-airgap-<ARCH>.tar.gz 和 hami-ai-platform-v<VERSION>-airgap-<ARCH>.tar.gz.sha256。
hami-ai-platform 离线包包括 dynamia-ai/hami-enterprise、nvidia/gpu-operator 和 prometheus-community/kube-prometheus-stack,envoyproxy/envoy-gateway,dynamia-ai/hami-ai-platform(kantaloupe) 可以按需安装。
# 下载
curl -L -O <URL>
# 或:wget <URL>
# 解压外层 tar.gz
# macOS
tar -xzf hami-ai-platform-vX.Y.Z-airgap-amd64.tar.gz
# Linux(GNU tar)
tar -xaf hami-ai-platform-vX.Y.Z-airgap-amd64.tar.gz
校验一致性
# Linux / macOS
shasum -a 256 -c hami-ai-platform-vX.Y.Z-airgap-amd64.tar.gz.sha256
# 或手动比对
shasum -a 256 hami-ai-platform-vX.Y.Z-airgap-amd64.tar.gz
cat hami-ai-platform-vX.Y.Z-airgap-amd64.tar.gz.sha256
后续安装过程请见解压出来的 DEPLOY.md 文件。
启用 GPU 节点
HAMi device plugin 仅在带 gpu=on 标签的节点上启动:
kubectl label nodes <node-name> gpu=on
验证:
kubectl -n hami-system get pods应能看到hami-device-plugin-*、hami-scheduler-*处于 Running 状态。
监控对接
确保 Prometheus 能采集 HAMi 与 DCGM-Exporter 指标。
ServiceMonitor 资源的
metadata.labels必须与 Prometheus 的spec.serviceMonitorSelector字段匹配,否则 Prometheus 不会发现这些 Monitor。
验证指标采集
| Exporter | 查询指标 | 预期 |
|---|---|---|
| dcgm-exporter | DCGM_FI_DEV_GPU_UTIL | 返回非空值 |
| hami-exporter | HostCoreUtilization | 返回非空值 |
| hami-device-plugin-exporter | GPUDeviceCoreAllocated | 返回非空值 |
激活
请完成上述安装任务,确保所有组件的 Pod 都正常启动后再开始激活流程。
执行以下脚本收集许可证信息(需要 kubectl、jq):
# 在线安装
curl -fsSL https://dynamia.ai/scripts/collect-hami-license-info.sh | bash
# 离线安装(包内已包含)
bash collect-hami-license-info.sh
执行后可以看到以下 JSON 内容:
{
"kube_system_uid": "bd8bce4f-f440-48e0-bf74-4ea2b6419c8b",
"collection_time": "2026-05-28T03:00:39Z",
"hami_install_location_namespace": "hami-system",
"total_licenses": 1,
"licenses": [
{
"uuid": "GPU-6762ec8e-2ce2-9ae4-df13-3e2e5cf17e53",
"reminder": 10,
"expire": "2026-06-21T10:04:41.468Z",
"node_name": "172.28.135.11"
}
]
}
把上述信息发送给 Dynamia.ai 的售前/技术支持获取证书。
安装后验证
# 1. Pod 状态
kubectl -n hami-system get pods
# 2. Device Plugin 注册的 GPU 资源
kubectl describe node <gpu-node> | grep -A 5 'Capacity:'
# 期望看到:nvidia.com/gpu: <N> 以及 nvidia.com/gpumem: <MB>
# 3. 提交一个测试 Pod 验证调度
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: hami-smoke
spec:
restartPolicy: Never
containers:
- name: cuda
image: nvidia/cuda:12.4.0-base-ubuntu22.04
command: ["nvidia-smi"]
resources:
limits:
nvidia.com/gpu: 1
nvidia.com/gpumem: 2000
EOF
kubectl logs hami-smoke
期望:nvidia-smi 输出可见 GPU 信息,且显存被限制为 2000 MiB。
HAMi 平台版验证
# 1. Pod 状态
kubectl -n kantaloupe-system get pods
# 2. 服务可达
kubectl -n kantaloupe-system get svc
HAMi AI Platform 服务暴露后,打开站点,确认前后端正常工作。
创建工作负载
在控制台 工作负载 页面,创建应用(如 gpu-burn):
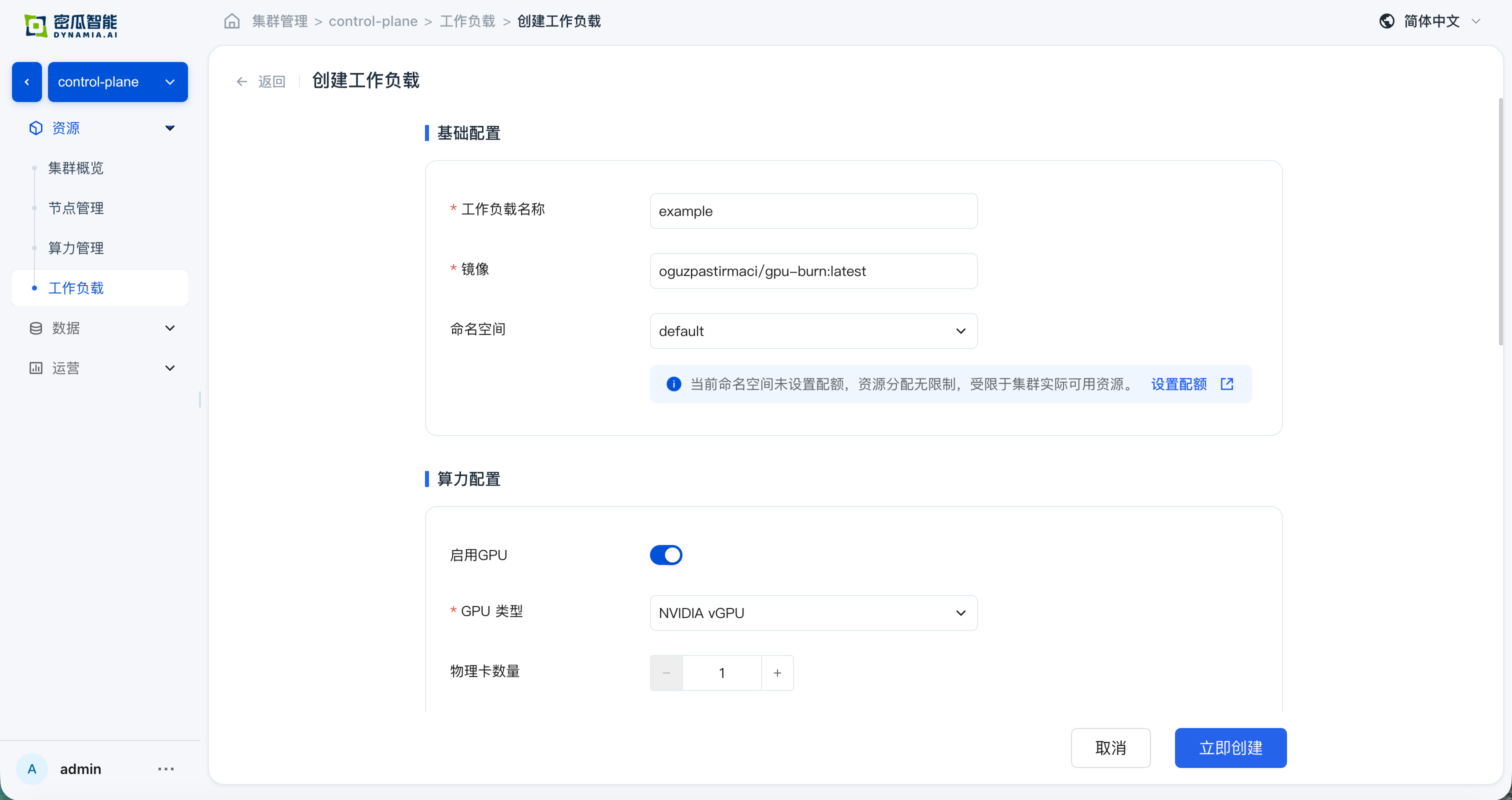
创建完成后,确认以下验证项均通过:
-
创建成功,控制台无报错
-
负载列表:应用状态、检索、列表指标与监控面板(GPU SM / GPU MEM / CPU / Memory)正常,时间切换与图表符合预期
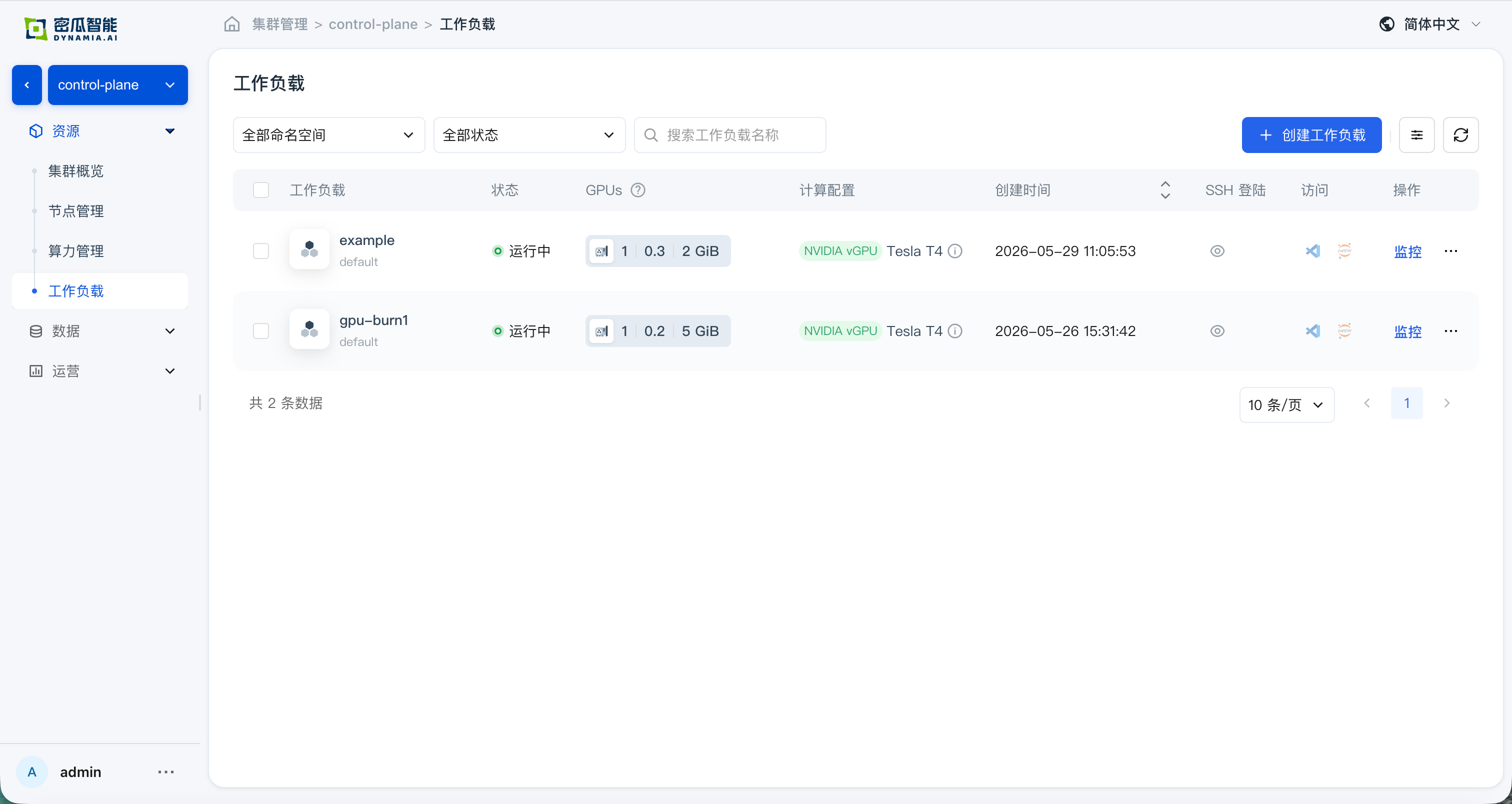
zh: 负载列表 -
应用详情:基础信息、资源总览、与监控数据正常;从详情页跳转 GPU / 节点页面,资源总览与监控数据正常
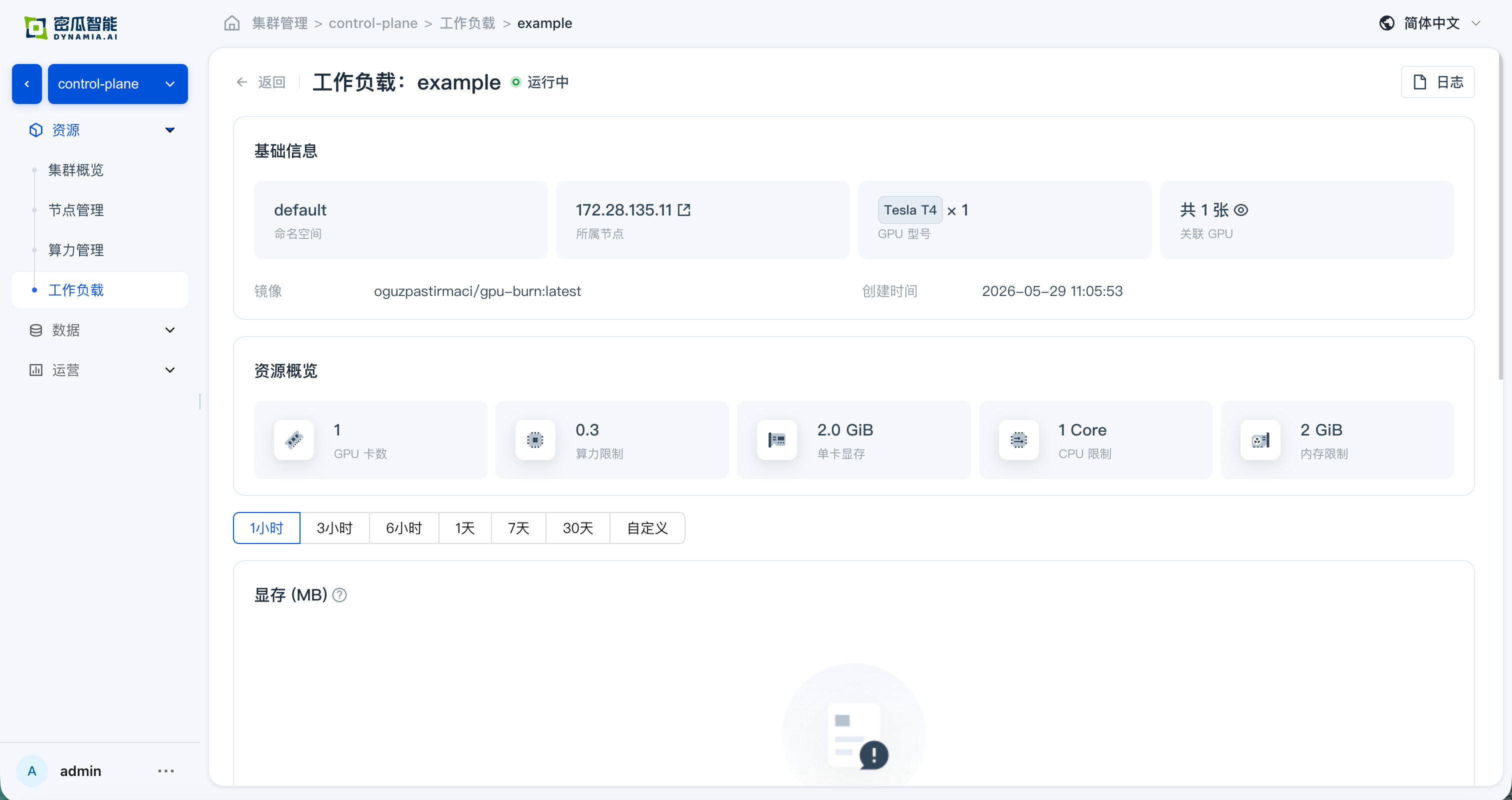
zh: 应用详情 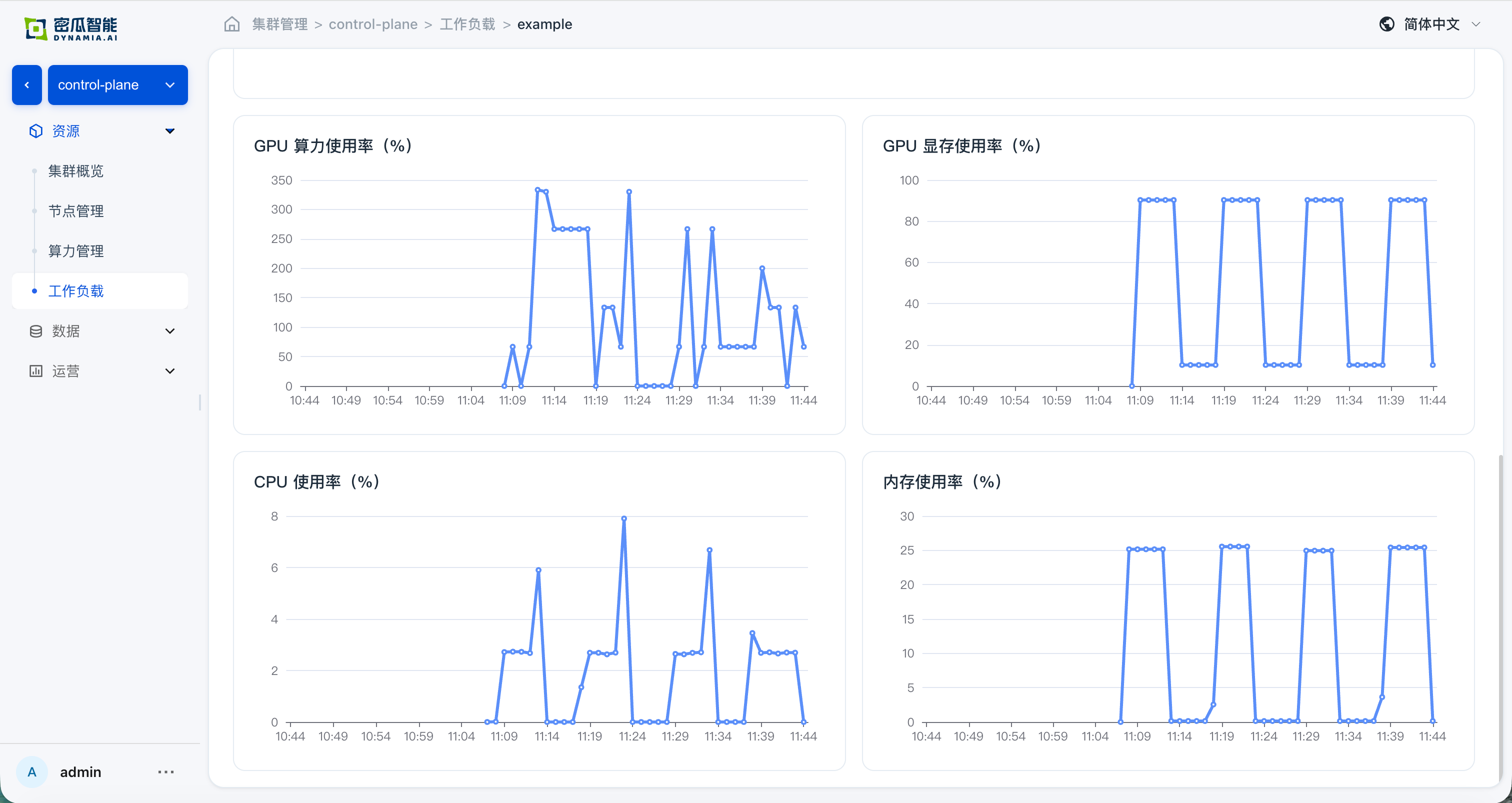
zh: 应用详情
常见问题与故障排查
| 现象 | 可能原因 | 处理 |
|---|---|---|
| 镜像拉不下来 | Node 没有外部网络或者与 ghcr.io 连接不畅 | 联系 Dynamia.ai 的售前/技术支持获取国内镜像仓库地址或 All-in-One 离线一体包 |
device-plugin Pod Pending 或者不存在 | 节点未打 gpu=on 标签 | kubectl label nodes <node> gpu=on |
device-plugin Pod CrashLoopBackOff | 与 NVIDIA 默认 device-plugin 冲突 | 禁用 GPU Operator 的 devicePlugin(--set devicePlugin.enabled=false) |
| Prometheus 查不到 HAMi 指标 | serviceMonitorNamespaceSelector 与 ServiceMonitor label 不匹配 | 对齐 prometheus/prometheus-kube-prometheus-prometheus 的 .spec.serviceMonitorSelector 和 hami-enterprise 的 serviceMonitor labels |
nvidia-smi 报错 | GPU 驱动未就绪 | 检查 gpu-operator namespace 下 driver Pod 状态 |
HAMi 平台版 Pod ImagePullBackOff | values.yaml 镜像地址错误 | 检查 image.registry / image.repository 配置 |
获取支持
- 邮箱:info@dynamia.ai
- 售前 / 技术支持:400-026-7800
- 已签订商业合同的客户请通过专属支持渠道提交 Issue