Nvidia 收购 Run:ai 后开源的 KAI-Scheduler vs HAMi:GPU 共享的技术路线分析与协同展望
最近,随着 Nvidia 收购 Run:ai 并将其核心调度组件 KAI-Scheduler 开源,AI 和 Kubernetes 社区都投入了相当大的关注。其中,KAI-Scheduler 带来的 GPU Sharing 功能,更是让不少专注于 GPU 资源虚拟化的朋友们眼前一亮。
这自然引发了一些技术层面的探讨:KAI-Scheduler 的 GPU Sharing 实现方式与 HAMi 的技术路径有何异同?这两种不同的方法,各自适用于哪些场景,又将如何共同推动社区在 GPU 共享/虚拟化领域的发展?
带着这些问题,我们深入研究了 KAI-Scheduler GPU Sharing 的架构与技术实现,特别是其创新的 Reservation Pod 机制。同时,我们近期与 Run:ai 团队的积极交流,包括在 KubeCon EU 2025 现场与 Run:ai CTO Ronen Dar 及其同事就 KAI-Scheduler、HAMi、开源合作等话题进行的深入探讨与交流。今天,我们进行一次技术专题,对比 KAI-Scheduler 和 HAMi 的实现方式,并展望未来合作的可能性。
本文速览 痛点分析:
-
为何 K8s 原生共享 GPU 如此困难?
-
机制解析:KAI 如何用 Reservation Pod 巧妙实现共享?
-
方案剖析:KAI 共享方案的亮点与局限。
-
路径对比:对比 HAMi,硬隔离的价值何在?
-
合作展望:社区积极对话,未来合作空间几何?
痛点分析
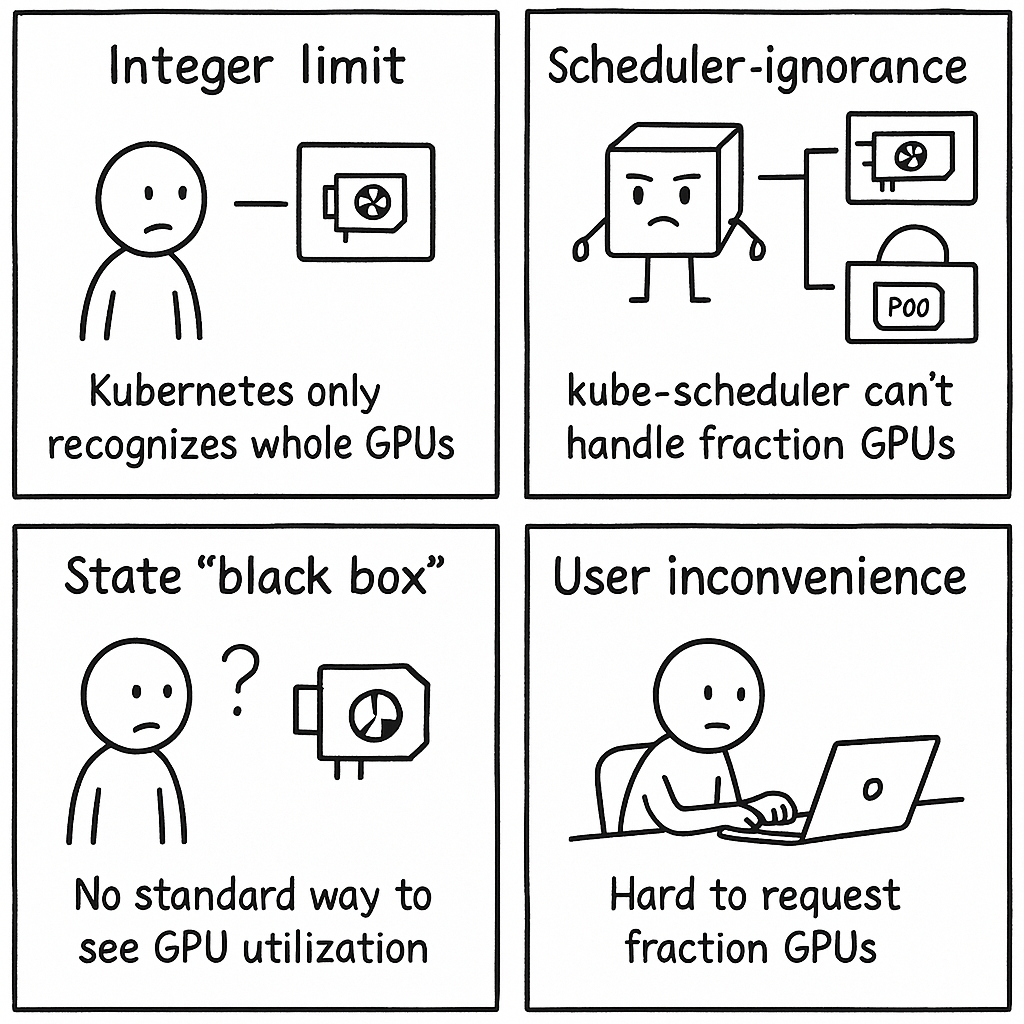
一、原生 K8s 的“痛点”:GPU 为何难共享?
在深入 KAI 之前,我们先回顾下为什么在 Kubernetes 中实现 GPU 共享本身就是个挑战:
-
整数限制:Kubernetes 原生资源模型 (nvidia.com/gpu) 只认整数 GPU,无法表达“我要 0.2 个 GPU”这样的需求。
-
调度无知:标准的 kube-scheduler 看不懂分数 GPU 的概念,可能会把一个本应共享的 GPU 分配给一个请求整卡的 Pod,造成冲突。
-
状态“黑盒”: 如何让 Kubernetes 集群知道某个 GPU 已经被部分占用了?缺乏标准表示方法。
-
用户不便:开发者需要一种简单直观的方式来申请和使用分数 GPU 资源。
机制解析
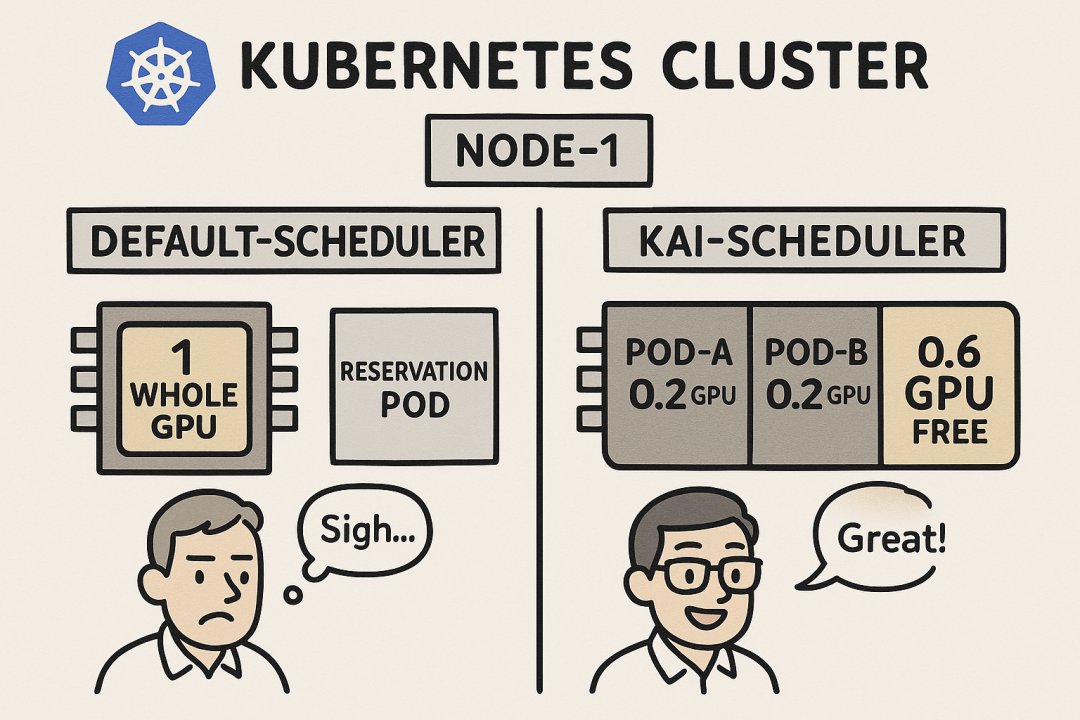
二、KAI 的巧思:用 Reservation Pod“瞒天过海”
面对这些挑战,KAI-Scheduler 提出了一种非常巧妙的解决方案:Reservation Pod。
核心思想可以理解为一种“逻辑欺骗”:
-
当一个 Pod 请求分数 GPU 时,KAI-Scheduler 不会直接尝试告诉 K8s "这个 Pod 要 0.x 个 GPU"。
-
相反,它会创建一个特殊的、低资源消耗的 Reservation Pod。这个 Pod 会正儿八经地向 Kubernetes 申请 整个 GPU (nvidia.com/gpu: "1")!
-
这样一来,Kubernetes 就认为这个 GPU 已经被完全分配掉了,kube-scheduler 自然不会再把其他 Pod 调度到这个 GPU 上。
-
而实际的分数管理和分配逻辑,则完全由 KAI-Scheduler 在内部维护。
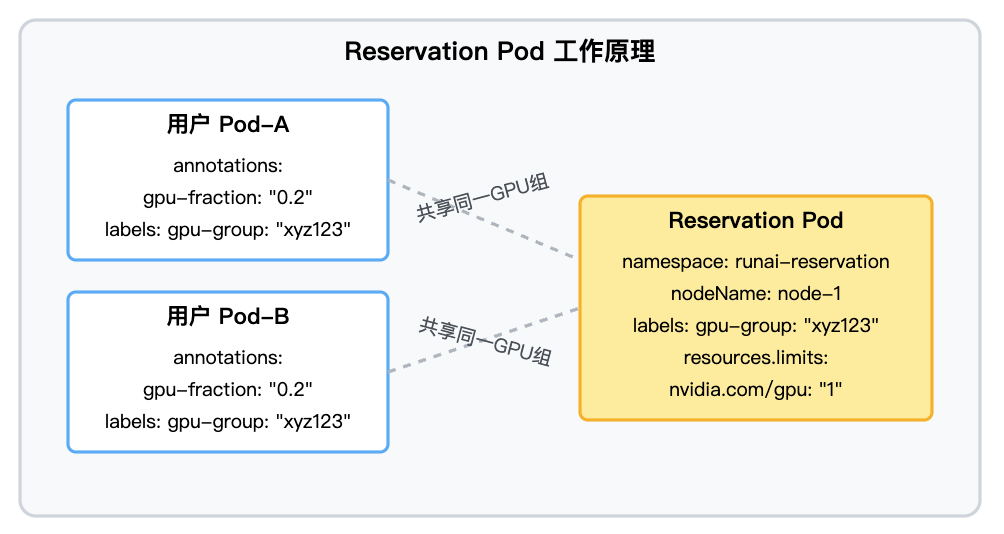
这个 Reservation Pod 主要承担以下职责:
-
GPU 预留: 对 K8s“宣告主权”,占住整个 GPU 资源。
-
资源可见性: 使 GPU 的“已被部分使用”状态在 K8s 体系内间接可见(虽然 K8s 以为是被 Reservation Pod 占满了)。
-
防止冲突: 阻止标准调度器染指这个正在被共享的 GPU。
-
逻辑分组: 通过给 Reservation Pod 和共享它的用户 Pod 打上相同的标签 (如 gpu-group: xyz123),将它们逻辑上绑定在一起。
三、深入技术细节:KAI GPU Sharing 如何运作?
了解了核心思想,我们再深入看看具体实现:
- 用户请求: 用户 Pod 通过 annotations 提交分数 GPU 需求,例如:
metadata:
annotations:
gpu-fraction: "0.2" # 请求 20% GPU 资源
- KAI 调度:
-
KAI-Scheduler 识别到 gpu-fraction 注解。
-
计算所需资源(如 20% 对应多少显存),并寻找合适的节点和物理 GPU。
pkg/scheduler/gpu_sharing/gpuSharing.go 中实现的分配逻辑:
func AllocateFractionalGPUTaskToNode(
ssn *framework.Session,
stmt *framework.Statement,
pod *pod_info.PodInfo,
node *node_info.NodeInfo,
isPipelineOnly bool,
) bool {
fittingGPUs := ssn.FittingGPUs(node, pod)
gpuForSharing := getNodePreferableGpuForSharing(fittingGPUs, node, pod, isPipelineOnly)
if gpuForSharing == nil {
return false
}
pod.GPUGroups = gpuForSharing.Groups
isPipelineOnly = isPipelineOnly || gpuForSharing.IsReleasing
success := allocateSharedGPUTask(ssn, stmt, node, pod, isPipelineOnly)
if !success {
pod.GPUGroups = nil
}
return success
}
关键:Reservation Pod 管理
-
首次分配: 如果这是第一个请求共享该 GPU 的 Pod,KAI-Scheduler 会创建一个 Reservation Pod(调用 createResourceReservationPod),请求 nvidia.com/gpu: "1",并为其打上唯一的 gpu-group 标签。
-
后续分配: 如果检测到已有 Pod 正在共享该 GPU(即存在对应 gpu-group 的 Reservation Pod),则复用这个 Reservation Pod,不再创建新的。
-
绑定: KAI-Scheduler 会给当前用户 Pod 也打上相同的 gpu-group 标签,建立关联。
-
pkg/binder/binding/resourcereservation/resource_reservation.go 中实现的 Reservation Pod 创建逻辑:
// createResourceReservationPod 在指定节点上创建一个仅用于资源预留的 Pod
func (rsc *service) createResourceReservationPod(
nodeName, gpuGroup, podName, appName string,
resources v1.ResourceRequirements,
) (*v1.Pod, error) {
podSpec := &v1.Pod{
ObjectMeta: metav1.ObjectMeta{
Name: podName,
Namespace: namespace, // runai-reservation
Labels: map[string]string{
constants.AppLabelName: appLabelValue,
constants.GPUGroup: gpuGroup,
runaiResourceReservationAppLabelName: appName,
},
},
Spec: v1.PodSpec{
NodeName: nodeName, // 固定到特定节点
ServiceAccountName: serviceAccountName,
Containers: []v1.Container{
{
Name: resourceReservation,
Image: rsc.reservationPodImage, // 轻量级容器镜像
Resources: resources, // 请求整个 GPU
// ...其他配置
},
},
},
}
return podSpec, rsc.kubeClient.Create(context.Background(), podSpec)
}
- 内部记账:在 KAI-Scheduler 的内部状态(GpuSharingNodeInfo 结构)中,精确记录每个 gpu-group 下已分配的 GPU 显存。在 pkg/scheduler/api/node_info/gpu_sharing_node_info.go 中定义的跟踪 GPU 共享状态的核心结构:
// GpuSharingNodeInfo 记录节点内 GPU 共享使用的实时状态
type GpuSharingNodeInfo struct {
// 正在释放的共享 GPU(key 为 GPU ID)
ReleasingSharedGPUs map[string]bool
// 每个 GPU 上已被占用的显存(单位:字节)
UsedSharedGPUsMemory map[string]int64
// 正在释放的显存量(单位:字节)
ReleasingSharedGPUsMemory map[string]int64
// 已分配的共享显存量(单位:字节)
AllocatedSharedGPUsMemory map[string]int64
}
-
UsedSharedGPUsMemory
记录每个 GPU 组上 已实际被 Pod 使用 的显存总量(字节)。 -
ReleasingSharedGPUsMemory
记录每个 GPU 组上 正处于释放过程中 的显存总量(字节)。 -
AllocatedSharedGPUsMemory
记录每个 GPU 组上 已被 Scheduler 分配 给 Pod、但 Pod 可能尚未真正占用的显存总量(字节)。

- 资源回收:
-
当一个共享 GPU 的用户 Pod 终止时,KAI 更新内部记账。
-
当最后一个关联到某个 gpu-group 的用户 Pod 结束时,KAI-Scheduler 会检查到这个 gpu-group 不再有活跃用户 Pod,于是删除对应的 Reservation Pod(syncForPods 中的逻辑),将 GPU 资源“归还”给 K8s。

- syncForPods 函数中实现的资源回收逻辑:
// syncForPods 将当前节点上的 Pod 分为两类:资源预留 Pod 和实际使用 GPU 的分数 Pod,
// 并在没有对应分数 Pod 时清理遗留的预留 Pod。
func (rsc *service) syncForPods(ctx context.Context, pods []*v1.Pod, gpuGroupToSync string) error {
logger := log.FromContext(ctx)
reservationPods := map[string]*v1.Pod{}
fractionPods := map[string][]*v1.Pod{}
// 1. 按 GPU 组将 Pod 分为预留 Pod 和分数 Pod
for _, pod := range pods {
if pod.Namespace == namespace { // 预留 Pod
reservationPods[gpuGroupToSync] = pod
continue
}
if slices.Contains([]v1.PodPhase{v1.PodRunning, v1.PodPending}, pod.Status.Phase) {
fractionPods[gpuGroupToSync] = append(fractionPods[gpuGroupToSync], pod)
}
}
// 2. 如果某 GPU 组已无分数 Pod,则删除对应的预留 Pod
for gpuGroup, reservationPod := range reservationPods {
if _, found := fractionPods[gpuGroup]; !found {
logger.Info("Did not find fraction pod for gpu group, deleting reservation pod",
"gpuGroup", gpuGroup)
if err := rsc.deleteReservationPod(ctx, reservationPod); err != nil {
return err
}
}
}
return nil
}
关键洞察:调度器层面的控制,暂无底层介入
KAI-Scheduler 的 GPU Sharing 实现,仅是在调度器层面通过创建/管理 Pod、解析 Annotation 和维护内部状态来完成的。
因此,KAI-Scheduler 的实现是“软隔离”。
方案剖析
四、KAI 方案优劣分析:优雅与无奈并存
我们来客观分析一下 KAI-Scheduler GPU Sharing 的特点:
亮点
-
优雅集成: 完全使用 K8s 标准原语(Pod, Annotation, Label),对 K8s 核心组件零修改,部署和集成相对简单。
-
良好兼容: Reservation Pod 的设计巧妙地避免了与 kube-scheduler 等其他组件的直接冲突。
-
高度灵活: 理论上支持任意比例的分数 GPU 分配,不受预设档位限制。
-
架构创新: "逻辑欺骗"的设计思路,展示了在 K8s 现有框架下扩展能力的聪明才智。
局限
-
软隔离 (Soft Isolation):这是其设计的核心特点。KAI-Scheduler 不提供任何强制性的资源隔离(无论是显存还是计算单元)。它只负责“逻辑上”的分配与调度。
-
依赖“君子协定”: 实际资源使用 完全依赖于 Pod 内运行的应用程序自觉。一个 Pod 即使只申请了 gpu-fraction: "0.2",它也可以尝试使用 80% 甚至 100% 的 GPU 显存或算力。KAI 纯调度层面无法阻止这一点。
-
潜在干扰: 这意味着它无法防止行为不端的应用(无论是无意还是恶意)超额使用资源,从而干扰同一块物理 GPU 上的其他“邻居”Pod,导致性能抖动甚至 OOM。
-
应用需配合: 为了尽可能模拟隔离效果,用户必须在应用程序代码内部手动设置资源限制(例如使用 torch.cuda.set_per_process_memory_fraction 或 TensorFlow 的类似配置),这增加了使用的复杂性和潜在的出错点。
路径对比
五、技术路径对比:KAI 的轻量级 vs HAMi 的硬隔离
现在,让我们对比 KAI 的方案与 HAMi 的技术路径:
HAMi(以及其他追求强隔离的 GPU 虚拟化方案)的核心优势在于实现了 硬隔离 (Hard Isolation)。这通常是通过以下方式达成的:
- 定制 HAMi Device Plugin: 不仅仅是上报资源,更是在分配时注入隔离配置。
- 结合 HAMi-Core: 利用更底层的 CUDA-Runtime 和 CUDA-Driver 层之间的拦截,对每个容器的 GPU 显存资源进行强制性限制。
硬隔离带来的关键优势:
- 资源有保障: 每个容器能使用的 GPU 资源有明确的上限,无法超额占用。
- 隔离性强: 有效防止“吵闹邻居”问题,保障多租户环境下的服务质量 (QoS)。
- 应用透明: 大部分情况下,用户应用程序无需修改代码或添加额外配置。
场景决定选择:
- KAI-Scheduler 的轻量级: 其部署简单、与 K8s 生态结合优雅的特点非常有吸引力。它提供了一种轻量级的 GPU 共享调度方案。
- HAMi 的硬隔离: 对资源保障和性能稳定性有严格要求的场景。
合作展望
六、社区对话与未来展望:协同发展
KAI-Scheduler 的 GPU Sharing 机制无疑是一种巧妙且值得借鉴的设计,它展示了在 K8s 现有体系内通过调度器创新解决实际问题的能力。其对 K8s 原语的精妙运用,为社区提供了新的思路。
同时,我们也看到,对于 GPU 共享的核心需求之一——可靠的资源隔离与保障,KAI 的“软隔离”与 HAMi 追求的“硬隔离”代表了不同的技术路径和权衡。
令人欣喜的是,我们与 Run:ai (Nvidia) 团队已经就这些技术方向展开了积极的交流。在最近的 KubeCon EU 现场,我们与 Run:ai CTO 及其同事进行了富有成效的讨论,特别是在硬隔离的技术方案上交流了看法,HAMi 分享了我们在这方面的实践和思考。双方都表达了对 GPU 资源管理领域持续探索的热情,并期待未来能有更深入的技术交流与合作。


KubeCon EU 现场 HAMi Maintainer 与 Run:ai CTO Ronen Dar 及其同事的愉快合照
我们认为,KAI-Scheduler 的开源为社区带来了新的活力和选择。它与 HAMi 所代表的硬隔离方案并非相互排斥,而是可以看作是针对不同场景和需求的补充。KAI 的调度策略创新,结合 HAMi 在硬隔离方面的探索,或许能为社区带来更完善、更灵活的 GPU 虚拟化解决方案。
七、总结:积极对话、合作共赢、共促未来
- KAI-Scheduler GPU Sharing: 设计优雅,兼容 K8s 生态,通过 Reservation Pod 巧妙实现调度层面的分数 GPU 管理。但本质是软隔离,依赖应用自律。
- HAMi: 追求硬隔离,通过 HAMi Device Plugin 及 HAMi-Core 提供强制性的资源限制和保障,更适合对隔离性要求高的生产环境。
- 社区与合作:我们赞赏 KAI 团队的技术创新,并对其开源表示欢迎。通过与 Run:ai (Nvidia) 团队在 KubeCon EU 的积极对话,我们看到了社区合作的巨大潜力。双方的技术交流,特别是在硬隔离等方向的探讨,预示着未来共同推动 GPU 资源管理技术发展的可能性。
HAMi 社区将持续关注 KAI-Scheduler 的发展,并积极参与社区讨论,期待与包括 Nvidia/Run:ai 在内的伙伴们一起,为 Kubernetes 用户带来更强大、更灵活、更可靠的 GPU 解决方案。
欢迎讨论
你对 KAI-Scheduler 的 GPU Sharing 怎么看?你认为软隔离和硬隔离分别适用于哪些场景?欢迎在评论区留下你的看法,或者加入我们的 HAMi 社区一起交流!
感谢阅读!如果你觉得这篇文章对你有帮助,欢迎点赞、推荐、分享给更多朋友!
HAMi,全称是 Heterogeneous AI Computing Virtualization Middleware(异构算力虚拟化中间件),是一套为管理 k8s 集群中的异构 AI 计算设备而设计的“一站式”架构,能够提供异构 AI 设备共享能力,提供任务间的资源隔离。HAMi 致力于提升 k8s 集群中异构计算设备的利用率,为不同类型的异构设备提供统一的复用接口。HAMi 当前是 CNCF Sandbox 项目,已被 CNCF 纳入 CNAI 类别技术全景图。