HAMi vGPU 原理分析 Part3:hami- scheduler 工作流程分析
上篇我们分析了 hami-webhook,该 Webhook 将申请了 vGPU 资源的 Pod 的调度器修改为 hami-scheduler,后续使用 hami-scheduler 进行调度。
本文为 HAMi 原理分析的第三篇,分析 hami-scheduler 工作流程。
上篇主要分析了 hami-webhook,解决了:Pod 是如何使用到 hami-scheduler,创建 Pod 时我们未指定 SchedulerName 默认会使用 default-scheduler 进行调度才对 问题。
这篇开始分析 hami-scheduler,解决另一个问题:hami-scheduler 逻辑,spread & binpark 等 高级调度策略是如何实现的
写完发现内容还是很多,spread & binpark 调度策略下一篇在分析吧,这篇主要分析调度流程。
以下分析基于 HAMi v2.4.0
省流:
HAMi Webhook、Scheduler 工作流程如下:
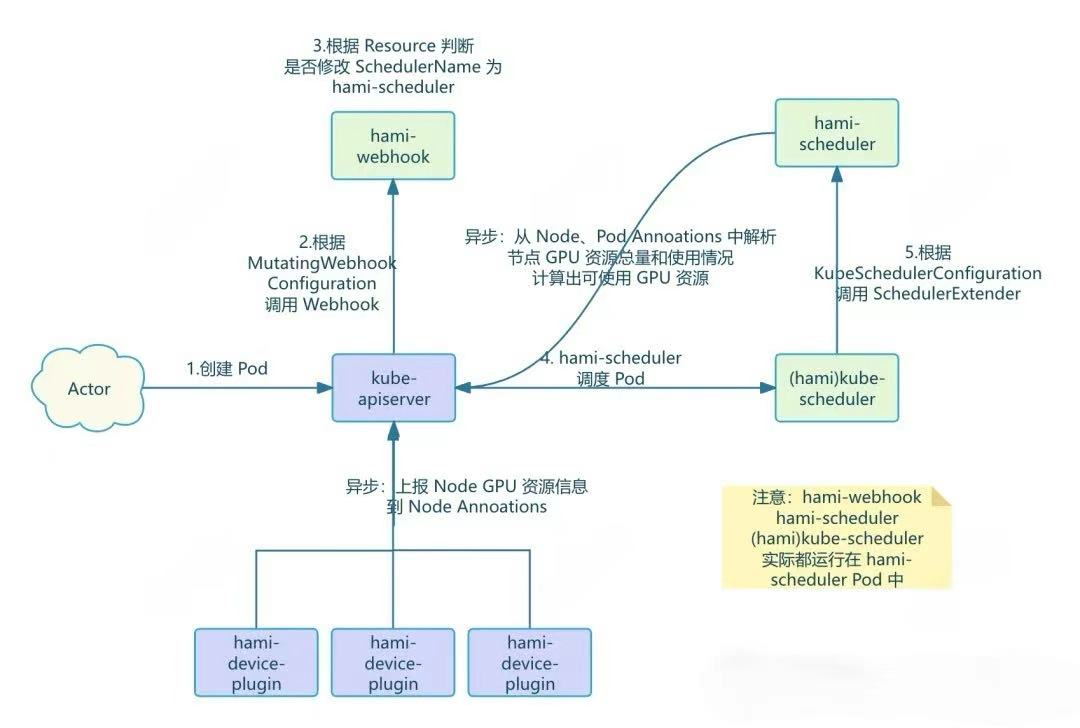
-
用户创建 Pod 并在 Pod 中申请了 vGPU 资源
-
kube-apiserver 根据 MutatingWebhookConfiguration 配置请求 HAMi-Webhook
-
HAMi-Webhook 检测 Pod 中的 Resource,如果申请的由 HAMi 管理的 vGPU 资源,就会把 Pod 中的 SchedulerName 改成了 hami-scheduler,这样这个 Pod 就会由 hami-scheduler 进行调度了。
-
对于特权模式的 Pod,Webhook 会直接跳过不处理
-
对于使用 vGPU 资源但指定了 nodeName 的 Pod,Webhook 会直接拒绝
- hami-scheduler 进行 Pod 调度,不过就是用的 k8s 的默认 kube-scheduler 镜像,因此调度逻辑和默认的 default-scheduler 是一样的,但是 kube-scheduler 还会根据 KubeSchedulerConfiguration 配置,调用 Extender Scheduler 插件
-
这个 Extender Scheduler 就是 hami-scheduler Pod 中的另一个 Container,该 Container 同时提供了 Webhook 和 Scheduler 相关 API。
-
当 Pod 申请了 vGPU 资源时,kube-scheduler 就会根据配置以 HTTP 形式调用 Extender Scheduler 插件,这样就实现了自定义调度逻辑。
- Extender Scheduler 插件包含了真正的 hami 调度逻辑,调度时根据节点剩余资源量进行打分选择节点
- 这里就包含了 spread & binpark 等 高级调度策略的实现
- 异步任务,包括 GPU 感知逻辑
-
devicePlugin 中的后台 Goroutine 定时上报 Node 上的 GPU 资源并写入到 Node 的 Annoations
-
除了 DevicePlugin 之外,还使用异步任务以 Patch Annotation 方式提交更多信息
-
Extender Scheduler 插件根据 Node Annoations 解析出 GPU 资源总量、从 Node 上已经运行的 Pod 的 Annoations 中解析出 GPU 使用量,计算出每个 Node 剩余的可用资源保存到内存供调度时使用
1.概述
Hami-scheduler 主要是 Pod 的调度逻辑,从集群节点中为当前 Pod 选择最合适的节点。
Hami-scheduler 也是通过 Scheduler Extender 方式实现的。
但是 HAMi 并没有直接扩展 default-scheduler,而是使用默认的 kube-scheduler 镜像额外启动了一个 scheduler,但是通过配置把名称指定为了 hami-scheduler。
然后给这个 hami-scheduler 配置了 Extender,Extender 服务就是同 Pod 中的另一个 Container 启动的一个 http 服务。
ps:后续说的 hami-scheduler 一般只这部分 Extender 实现的调度插件
2.具体部署
Deployment
Hami-scheduler 使用 Deployment 进行部署,该 Deployment 中有两个 Container,其中一个是原生的 kube-scheduler,另一个则是 HAMi 的 Scheduler 服务。
完整 yaml 如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: vgpu-hami-scheduler
namespace: kube-system
spec:
template:
spec:
containers:
# vanilla kube-scheduler (patched to load our config)
- command:
- kube-scheduler
- --config=/config/config.yaml
- -v=4
- --leader-elect=true
- --leader-elect-resource-name=hami-scheduler
- --leader-elect-resource-namespace=kube-system
image: 192.168.116.54:5000/kube-scheduler:v1.23.17
imagePullPolicy: IfNotPresent
name: kube-scheduler
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /config
name: scheduler-config
# HAMI scheduler-extender (implements filter & bind)
- command:
- scheduler
- --resource-name=nvidia.com/vgpu
- --resource-mem=nvidia.com/gpumem
- --resource-cores=nvidia.com/gpucores
- --resource-mem-percentage=nvidia.com/gpumem-percentage
- --resource-priority=nvidia.com/priority
- --http_bind=0.0.0.0:443
- --cert_file=/tls/tls.crt
- --key_file=/tls/tls.key
- --scheduler-name=hami-scheduler
- --metrics-bind-address=:9395
- --default-mem=0
- --default-gpu=1
- --default-cores=0
- --iluvatar-memory=iluvatar.ai/vcuda-memory
- --iluvatar-cores=iluvatar.ai/vcuda-core
- --cambricon-mlu-name=cambricon.com/vmlu
- --cambricon-mlu-memory=cambricon.com/mlu.smlu.vmemory
- --cambricon-mlu-cores=cambricon.com/mlu.smlu.vcore
- --ascend-name=huawei.com/Ascend910
- --ascend-memory=huawei.com/Ascend910-memory
- --ascend310p-name=huawei.com/Ascend310P
- --ascend310p-memory=huawei.com/Ascend310P-memory
- --overwrite-env=false
- --node-scheduler-policy=binpack
- --gpu-scheduler-policy=spread
- --debug
- -v=4
image: projecthami/hami:v2.3.13
imagePullPolicy: IfNotPresent
name: vgpu-scheduler-extender
ports:
- containerPort: 443
name: http
protocol: TCP
volumeMounts:
- mountPath: /tls
name: tls-config
dnsPolicy: ClusterFirst
priorityClassName: system-node-critical
restartPolicy: Always
schedulerName: default-scheduler
serviceAccount: vgpu-hami-scheduler
serviceAccountName: vgpu-hami-scheduler
terminationGracePeriodSeconds: 30
volumes:
- name: tls-config
secret:
defaultMode: 420
secretName: vgpu-hami-scheduler-tls
- configMap:
defaultMode: 420
name: vgpu-hami-scheduler-newversion
name: scheduler-config
KubeSchedulerConfiguration
对应的 Scheduler 的配置文件存储在 Configmap 中,具体内容如下:
apiVersion: v1
data:
config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: false
profiles:
- schedulerName: hami-scheduler
extenders:
- urlPrefix: "https://127.0.0.1:443"
filterVerb: filter
bindVerb: bind
nodeCacheCapable: true
weight: 1
httpTimeout: 30s
enableHTTPS: true
tlsConfig:
insecure: true
managedResources:
- name: nvidia.com/vgpu
ignoredByScheduler: true
- name: nvidia.com/gpumem
ignoredByScheduler: true
- name: nvidia.com/gpucores
ignoredByScheduler: true
- name: nvidia.com/gpumem-percentage
ignoredByScheduler: true
- name: nvidia.com/priority
ignoredByScheduler: true
- name: cambricon.com/vmlu
ignoredByScheduler: true
- name: hygon.com/dcunum
ignoredByScheduler: true
- name: hygon.com/dcumem
ignoredByScheduler: true
- name: hygon.com/dcucores
ignoredByScheduler: true
- name: iluvatar.ai/vgpu
ignoredByScheduler: true
- name: huawei.com/Ascend910-memory
ignoredByScheduler: true
- name: huawei.com/Ascend910
ignoredByScheduler: true
- name: huawei.com/Ascend310P-memory
ignoredByScheduler: true
- name: huawei.com/Ascend310P
ignoredByScheduler: true
kind: ConfigMap
metadata:
name: vgpu-hami-scheduler-newversion
namespace: kube-system
SchedulerName
首先是指定了 Scheduler 名字叫做 hami-scheduler,k8s 默认的调度器叫做 default-scheduler。
profiles:
- schedulerName: hami-scheduler
创建 Pod 的时候我们是没有指定 schedulerName 的,所以默认都会使用 default-scheduler,也就是默认 kube-scheduler 进行调度。
之前 hami-webhook 修改 SchedulerName 时就需要和这里配置的名称对应。
Extenders
调度器核心配置如下:
extenders:
- urlPrefix: "https://127.0.0.1:443"
filterVerb: filter
bindVerb: bind
参数解释:
-
urlPrefix: "https://127.0.0.1:443":这是一个调度器扩展器的服务地址,Kubernetes 调度器会调用这个地址来请求外部调度逻辑。可以通过 HTTPS 访问。(External Scheduler 因为是和 kube-scheduler 部署在一个 Pod 里的,因此使用 127.0.0.1 进行访问)
-
filterVerb: filter:这个动词指示了调度器会调用这个扩展器服务来过滤节点,即决定哪些节点适合调度 Pod。(Filter 接口对应这个 http 服务的 url 就是 /filter)
-
bindVerb: bind:调度器扩展器可以执行绑定操作,即将 Pod 绑定到特定节点。(同上,bind 就要对应 /bind 这个接口)
managedResources
managedResources 这部分指定这个扩展调度器 hami-cheduler 管理的资源,只有 Pod Resource 中申请了 managedResources 中指定的资源时,Scheduler 才会请求我们配置的 Extender,也就是 hami-scheduler。
即:只要没申请 vGPU 资源,就是指定使用 hami-scheduler 调度,也是由名为 hami-scheduler 的 kube-scheduler 进行调度,不会请求 Extender,真正的 HAMi 调度插件不会生效。
managedResources:
- name: nvidia.com/vgpu
ignoredByScheduler: true
- name: nvidia.com/gpumem
ignoredByScheduler: true
- name: nvidia.com/gpucores
ignoredByScheduler: true
- name: nvidia.com/gpumem-percentage
ignoredByScheduler: true
- name: nvidia.com/priority
ignoredByScheduler: true
- name: cambricon.com/vmlu
ignoredByScheduler: true
- name: hygon.com/dcunum
ignoredByScheduler: true
- name: hygon.com/dcumem
ignoredByScheduler: true
- name: hygon.com/dcucores
ignoredByScheduler: true
- name: iluvatar.ai/vgpu
ignoredByScheduler: true
- name: huawei.com/Ascend910-memory
ignoredByScheduler: true
- name: huawei.com/Ascend910
ignoredByScheduler: true
- name: huawei.com/Ascend310P-memory
ignoredByScheduler: true
- name: huawei.com/Ascend310P
ignoredByScheduler: true
-
name: nvidia.com/vgpu:资源名称
-
ignoredByScheduler:当设置为 true 时,调度器在做节点资源匹配和资源分配时,会忽略这个资源。这些资源都由扩展的 hami-scheduler 进行调度即可。
这样配置之后,对于 nvidia.com/vgpu、nvidia.com/gpumem 等等 managedResources 中指定的资源,调度器在做节点资源匹配和资源分配时,会忽略这个资源,不会因为 Node 上没有这些虚拟资源,就直接调度失败了。
当调度器请求扩展的 hami-scheduler 进行调度时,hami-scheduler 就能够正常处理这些资源,根据 Pod 申请的 Resource 配置找到对应的节点。
接下来则分析 hami-scheduler 的具体实现,包括两个问题:
-
hami-scheduler 如何感知 Node 上的 GPU 信息的,因为前面提到 gpucore、gpumem 这些都是虚拟资源,DevicePlugin 也是没有直接上报到 Node 上的
-
hami-scheduler 是如何选择最合适的节点的,spark & binpark 等高级调度策略是如何实现的
3. hami 如何感知 Nod 上的 GPU 资源情况的
分为两部分:
-
感知 Node 上的 GPU 资源信息
-
感知 Node 上 GPU 资源使用情况
因为 gpucore、gpumem 这些都是虚拟资源,因此不能像 DevicePlugin 上报的标准第三方资源一样,由 K8s 直接维护,而是需要 hami 自行维护。
为什么需要自定义感知逻辑
到这里大家可能会有疑问,上一篇文章中介绍了 hami-device-plugin-nvidia,这里的 devicePlugin 不就已经感知了节点上的 GPU 并上报到 kube-apiserver 了吗,怎么还需要实现一个感知逻辑?
# 节点状态示例(kubectl get node <node-name> -oyaml)
capacity:
cpu: "64"
memory: 256Gi
nvidia.com/vgpu: "20" # 20 个 vGPU(由 device-split-count 放大)
nvidia.com/gpumem: "9437184" # 总可用显存 MB
nvidia.com/gpucores: "2000" # 总可用核心
pods: "110"
因为:hami-scheduler 做了细粒度的 gpucore、gpumem 切分,那么就要知道节点上的 GPU 具体数量、每张卡的显存大小等信息,不然如果把 Pod 分配到一个所有 GPU 显存都已经消耗完的 Node 上不就出问题了。
感知节点上的 GPU 资源
Hami 是如何感知节点上的 GPU 情况的呢?也就是之前 start 方法中的这个 Goroutine 在维护,核心就是在这个 RegisterFromNodeAnnotations 方法中
// 后台协程:周期性读取 Node 上的 GPU 信息并以 annotation 形式同步到调度器缓存
go sher.RegisterFromNodeAnnotations()
精简后代码如下:
调用 kube-apiserver 获取到节点列表,然后从 node 的 Annoations 中解析出 Device 信息,并保存到内存中。
func (s *Scheduler) RegisterFromNodeAnnotations() {
klog.V(5).Infoln("Scheduler into RegisterFromNodeAnnotations")
ticker := time.NewTicker(15 * time.Second)
defer ticker.Stop()
for {
select {
case <-s.nodeNotify:
case <-ticker.C:
case <-s.stopCh:
return
}
// 1. 列表节点
labelSel := labels.Everything()
if len(config.NodeLabelSelector) > 0 {
labelSel = (labels.Set)(config.NodeLabelSelector).AsSelector()
}
rawNodes, err := s.nodeLister.List(labelSel)
if err != nil {
klog.Errorln("nodes list failed", err.Error())
continue
}
// 2. 遍历节点并解析 GPU 信息
for _, n := range rawNodes {
devInfos, err := devInstance.GetNodeDevices(*n)
if err != nil {
klog.Errorln("get node devices failed", err.Error())
continue
}
nodeInfo := util.NodeInfo{Devices: []util.DeviceInfo{}}
for _, di := range devInfos {
found := false
// 更新已缓存的 GPU
if cached, ok := s.nodes[n.Name]; ok {
for i, cd := range cached.Devices {
if cd.ID == di.ID {
s.nodes[n.Name].Devices[i].Devmem = di.Devmem
s.nodes[n.Name].Devices[i].Devcore = di.Devcore
found = true
break
}
}
}
// 新增 GPU
if !found {
nodeInfo.Devices = append(nodeInfo.Devices, util.DeviceInfo{
ID: di.ID,
Index: uint(di.Index),
Count: di.Count,
Devmem: di.Devmem,
Devcore: di.Devcore,
Type: di.Type,
Numa: di.Numa,
Health: di.Health,
DeviceVendor: devhandsk,
})
}
}
s.addNode(n.Name, nodeInfo)
}
}
}
会将最新的 Node 数据存到内存中,便于调度时使用,就是 nodeManager 中的 nodes 这个 map 对象
type Scheduler struct {
nodeManager
podManager
stopCh chan struct{}
kubeClient kubernetes.Interface
podLister listerscorev1.PodLister
nodeLister listerscorev1.NodeLister
// Node status returned by Filter
cachedstatus map[string]*NodeUsage
nodeNotify chan struct{}
// Node Overview
overviewstatus map[string]*NodeUsage
eventRecorder record.EventRecorder
}
type nodeManager struct {
nodes map[string]*util.NodeInfo
mutex sync.RWMutex
}
重点来了:这里的数据来源是 node 的 Annoations,而这个 Annoations 就是上一篇中提到的 hami device plugin nvidia 中的一个后台 goroutine 在维护。
// getNodesUsage 返回所有节点及其设备显存/核心占用,并过滤 nodeSelector / taints / nodeAffinity / unschedulable / nodeName
func (s *Scheduler) getNodesUsage(nodes *[]string, task *corev1.Pod) (*map[string]*NodeUsage, map[string]string, error) {
overall := make(map[string]*NodeUsage)
cache := make(map[string]*NodeUsage)
failed := make(map[string]string)
// 1. 列出所有节点
allNodes, err := s.ListNodes()
if err != nil {
return &overall, failed, err
}
// 2. 初始化节点设备列表
for _, n := range allNodes {
nodeU := &NodeUsage{}
policy := config.GPUSchedulerPolicy
if task != nil && task.Annotations != nil {
if v, ok := task.Annotations[policy.GPUSchedulerPolicyAnnotationKey]; ok {
policy = v
}
}
nodeU.Devices = policy.DeviceUsageList{
Policy: policy,
DeviceLists: []*policy.DeviceListsScore{},
}
for _, d := range n.Devices {
nodeU.Devices.DeviceLists = append(nodeU.Devices.DeviceLists, &policy.DeviceListsScore{
Score: 0,
Device: &util.DeviceUsage{
ID: d.ID,
Index: d.Index,
Used: 0,
Count: d.Count,
Usedmem: 0,
Totalmem: d.Devmem,
Totalcore: d.Devcore,
Usedcores: 0,
Type: d.Type,
Numa: d.Numa,
Health: d.Health,
},
})
}
overall[n.ID] = nodeU
}
// 3. 叠加已运行 Pod 占用
podsInfo := s.ListPodsInfo()
for _, p := range podsInfo {
node, ok := overall[p.NodeID]
if !ok {
continue
}
for _, podSingle := range p.Devices {
for _, ctrDevs := range podSingle {
for _, uDev := range ctrDevs {
for _, d := range node.Devices.DeviceLists {
if d.Device.ID == uDev.UUID {
d.Device.Used++
d.Device.Usedmem += uDev.Usedmem
d.Device.Usedcores += uDev.Usedcores
}
}
}
}
}
klog.V(5).Infof("usage: pod %v assigned %v %v", p.Name, p.NodeID, p.Devices)
}
s.overviewstatus = overall
// 4. 仅保留 caller 指定的节点
for _, nodeID := range *nodes {
node, err := s.GetNode(nodeID)
if err != nil {
klog.V(5).InfoS("node unregistered", "node", nodeID, "error", err)
failed[nodeID] = "node unregistered"
continue
}
cache[node.ID] = overall[node.ID]
}
s.cachedstatus = cache
return &cache, failed, nil
}
大概长这样:
apiVersion: v1
kind: Node
metadata:
annotations:
csi.volume.kubernetes.io/nodeid: >
{"nfs.csi.k8s.io":"j99cloudvm","rbd.csi.ceph.com":"j99cloudvm"}
hami.io/node-handshake: Requesting_2024.11.19 03:10:32
hami.io/node-handshake-dcu: Deleted_2024.09.13 06:42:44
hami.io/node-nvidia-register: >
GPU-03f69c50-207a-2038-9b45-23cac89cb67d,10,46068,100,NVIDIA-NVIDIA A40,0,true:
GPU-1afede84-4e70-2174-49af-f07ebb94d1ae,10,46068,100,NVIDIA-NVIDIA A40,0,true:
kubeadm.alpha.kubernetes.io/cri-socket: /run/containerd/containerd.sock
其中下面这个就是 GPU 的具体信息,包括 ID、型号、内存等信息。
hami.io/node-nvidia-register: 'GPU-03f69c50-207a-2038-9b45-23cac89cb67d,10,46068,100,NVIDIA-NVIDIA
A40,0,true:GPU-1afede84-4e70-2174-49af-f07ebb94d1ae,10,46068,100,NVIDIA-NVIDIA
A40,0,true:'
感知节点上 GPU 使用情况
除此之外,hami 还需要感知到 GPU 的使用情况,才能计算出还有多少 gpucore、gpumem 可以使用。
这里使用的 client-go 中提供的 Informer 机制,Watch Pod 和 Node 的变化情况,获取 Node 上运行的 Pod,根据 Pod 申请的资源和 Node 上的总资源计算出剩余资源。
// pkg/scheduler/scheduler.go#L127
func (s *Scheduler) Start() {
kubeClient, err := k8sutil.NewClient()
check(err)
s.kubeClient = kubeClient
informerFactory := informers.NewSharedInformerFactoryWithOptions(s.kubeClient, time.Hour*1)
s.podLister = informerFactory.Core().V1().Pods().Lister()
s.nodeLister = informerFactory.Core().V1().Nodes().Lister()
informer := informerFactory.Core().V1().Pods().Informer()
informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: s.onAddPod,
UpdateFunc: s.onUpdatePod,
DeleteFunc: s.onDelPod,
})
informerFactory.Core().V1().Nodes().Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: s.onAddNode,
UpdateFunc: s.onUpdateNode,
DeleteFunc: s.onDelNode,
})
informerFactory.Start(s.stopCh)
informerFactory.WaitForCacheSync(s.stopCh)
s.addAllEventHandlers()
}
其中 Pod Create、Update 时都会 j 进入下面这个 onAddPod 逻辑:
// AssignedNodeAnnotations = "hami.io/vgpu-node"
// pkg/scheduler/scheduler.go#L92
func (s *Scheduler) onAddPod(obj interface{}) {
pod, ok := obj.(*corev1.Pod)
if !ok {
klog.Errorf("unknown add object type")
return
}
nodeID, ok := pod.Annotations[util.AssignedNodeAnnotations]
if !ok {
return
}
if k8sutil.IsPodInTerminatedState(pod) {
s.delPod(pod)
return
}
podDev, _ := util.DecodePodDevices(util.SupportDevices, pod.Annotations)
s.addPod(pod, nodeID, podDev)
}
这边限制了只会处理 hami.io/vgpu-node annoations 的 Pod,过滤掉其他 Pod,从 Pod Annoations 中解析出该 Pod 使用的 GPU UUID 以及 memory 和 core 等信息。
Pod 上的 Annoations 大概是这样的:
$ k get po gpu-pod -oyaml
apiVersion: v1
kind: Pod
metadata:
annotations:
hami.io/bind-phase: success
hami.io/bind-time: "1727251686"
hami.io/vgpu-devices-allocated: GPU-03f69c50-207a-2038-9b45-23cac89cb67d,NVIDIA,3000,30:;
hami.io/vgpu-devices-to-allocate: ;
hami.io/vgpu-node: test
hami.io/vgpu-time: "1727251686"
其中hami.io/vgpu-devices-allocated 对应的 value 就是 GPU 信息,格式化后如下
GPU-03f69c50-207a-2038-9b45-23cac89cb67d,NVIDIA,3000,30:;
GPU-03f69c50-207a-2038-9b45-23cac89cb67d,NVIDIA,3000,30:;
-
GPU-03f69c50-207a-2038-9b45-23cac89cb67d:设备 UUID
-
NVIDIA:设备类型
-
3000:使用 3000M memory
-
30:使用 30% core
至于 Pod 删除则是直接删除内存中缓存的 Pod 信息即可。
Node 的变化则比较简单,就是往 nodeNotify channel 发送通知
func (s *Scheduler) onUpdateNode(_, newObj interface{}) {
s.nodeNotify <- struct{}{}
}
func (s *Scheduler) onDelNode(obj interface{}) {
s.nodeNotify <- struct{}{}
}
func (s *Scheduler) onAddNode(obj interface{}) {
s.nodeNotify <- struct{}{}
}
这个消息最终就会立即触发一次上面的 RegisterFromNodeAnnotations 逻辑
默认是定时的,每 15s 触发一次,增加 notify 可以在节点变化时更快感知到
func (s *Scheduler) RegisterFromNodeAnnotations() {
klog.V(5).Infoln("Scheduler into RegisterFromNodeAnnotations")
ticker := time.NewTicker(time.Second * 15)
for {
select {
case <-s.nodeNotify:
case <-ticker.C:
case <-s.stopCh:
return
}
// .....
}
}
通过这个 Informer HAMi 可以知道以下信息:
-
集群中的 GPU 节点情况,每个节点上的 GPU 设备信息
-
Pod 对 GPU 的具体使用情况,包括 memory、core 使用量等
通过这些信息,就可以完成后续的 Scheduler 逻辑了。
4.调度实现
上一步拿到集群中的 GPU 信息之后,就可以开始调度了,具体实现分为两个接口:
-
Filter:根据各种条件进行过滤,为当前 Pod 选择合适的节点
-
Bind:将 Pod 最终后某一个节点进行绑定,完成调度
Filter 接口
看下看 Filter 接口是怎么进行节点过滤的
// pkg/scheduler/scheduler.go#L444
func (s *Scheduler) Filter(args extenderv1.ExtenderArgs) (*extenderv1.ExtenderFilterResult, error) {
klog.InfoS("begin schedule filter", "pod", args.Pod.Name, "uuid", args.Pod.UID, "namespaces", args.Pod.Namespace)
nums := k8sutil.Resourcereqs(args.Pod)
total := 0
for _, n := range nums {
for _, k := range n {
total += int(k.Nums)
}
}
if total == 0 {
klog.V(1).Infof("pod %v not find resource", args.Pod.Name)
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, fmt.Errorf("does not request any resource"))
return &extenderv1.ExtenderFilterResult{
NodeNames: args.NodeNames,
FailedNodes: nil,
Error: "",
}, nil
}
annos := args.Pod.Annotations
s.delPod(args.Pod)
nodeUsage, failedNodes, err := s.getNodesUsage(args.NodeNames, args.Pod)
if err != nil {
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, err)
return nil, err
}
if len(failedNodes) != 0 {
klog.V(5).InfoS("getNodesUsage failed nodes", "nodes", failedNodes)
}
nodeScores, err := s.calcScore(nodeUsage, nums, annos, args.Pod)
if err != nil {
err := fmt.Errorf("calcScore failed %v for pod %v", err, args.Pod.Name)
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, err)
return nil, err
}
if len((*nodeScores).NodeList) == 0 {
klog.V(4).Infof("All node scores do not meet for pod %v", args.Pod.Name)
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, fmt.Errorf("no available node, all node scores do not meet"))
return &extenderv1.ExtenderFilterResult{
FailedNodes: failedNodes,
}, nil
}
klog.V(4).Infoln("nodeScores_len=", len((*nodeScores).NodeList))
sort.Sort(nodeScores)
m := (*nodeScores).NodeList[len((*nodeScores).NodeList)-1]
klog.Infof("schedule %v/%v to %v %v", args.Pod.Namespace, args.Pod.Name, m.NodeID, m.Devices)
annotations := make(map[string]string)
annotations[util.AssignedNodeAnnotations] = m.NodeID
annotations[util.AssignedTimeAnnotations] = strconv.FormatInt(time.Now().Unix(), 10)
for _, val := range device.GetDevices() {
val.PatchAnnotations(&annotations, m.Devices)
}
s.addPod(args.Pod, m.NodeID, m.Devices)
err = util.PatchPodAnnotations(args.Pod, annotations)
if err != nil {
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, err)
s.delPod(args.Pod)
return nil, err
}
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringSucceed, []string{m.NodeID}, nil)
res := extenderv1.ExtenderFilterResult{NodeNames: &[]string{m.NodeID}}
return &res, nil
}
对于没有申请特殊资源的 Pod 直接返回全部 Node 都可以调度,不做处理
nums := k8sutil.Resourcereqs(args.Pod)
total := 0
for _, n := range nums {
for _, k := range n {
total += int(k.Nums)
}
}
if total == 0 {
klog.V(1).Infof("pod %v not find resource", args.Pod.Name)
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, fmt.Errorf("does not request any resource"))
return &extenderv1.ExtenderFilterResult{
NodeNames: args.NodeNames,
FailedNodes: nil,
Error: "",
}, nil
}
否则就根据上一步中获取到的 Node 信息进行打分,具体打分逻辑则是根据每个节点上的已经使用的 GPU Core、GPU Memory 资源和总的 GPU Core、GPU Memory 的比值,根据权重归一化处理后得到最终的得分。
总的来说就是:节点上 GPU Core 和 GPU Memory 资源剩余越少,得分越高。
// pkg/scheduler/policy/node_policy.go#L52
func (ns *NodeScore) ComputeScore(devices DeviceUsageList) {
// current user having request resource
used, usedCore, usedMem := int32(0), int32(0), int32(0)
for _, device := range devices.DeviceLists {
used += device.Device.Used
usedCore += device.Device.Usedcores
usedMem += device.Device.Usedmem
}
klog.V(2).Infof("node %s used %d, usedCore %d, usedMem %d,", ns.NodeID, used, usedCore, usedMem)
total, totalCore, totalMem := int32(0), int32(0), int32(0)
for _, deviceLists := range devices.DeviceLists {
total += deviceLists.Device.Count
totalCore += deviceLists.Device.Totalcore
totalMem += deviceLists.Device.Totalmem
}
useScore := float32(used) / float32(total)
coreScore := float32(usedCore) / float32(totalCore)
memScore := float32(usedMem) / float32(totalMem)
ns.Score = float32(Weight) * (useScore + coreScore + memScore)
klog.V(2).Infof("node %s computer score is %f", ns.NodeID, ns.Score)
}
计算完成之后从中选了一个节点进行调度。
// 计算得分,拿到所有满足条件的节点
nodeScores, err := s.calcScore(nodeUsage, nums, annos, args.Pod)
// 排序
sort.Sort(nodeScores)
// 直接选择最后一个节点
m := (*nodeScores).NodeList[len((*nodeScores).NodeList)-1]
// 返回结果
res := extenderv1.ExtenderFilterResult{NodeNames: &[]string{m.NodeID}}
return &res, nil
到这里,我们已经拿到了最终要调度的 Node 了,调度逻辑就结束了。这里大家可能会有疑问:为什么 Filter 方法就只返回了一个节点,甚至还融合了打分的逻辑在里面。
如果按照正常逻辑实现 Filter、Score 等方法,最终 Scheduler 会汇总多个插件的打分,然后根据最终结果选择一个节点,**但是 HAMi 这边是要完全控制调度结果的,因此直接将 Filter、Score 逻辑融合到一起,最终就只返回一个目标节点,**这样最后肯定会调度到该节点。
Bind 接口
很简单,直接根据 Filter 的返回结果,将 Pod 和 Node 绑定即可完成调度。
func (s *Scheduler) Bind(args extenderv1.ExtenderBindingArgs) (*extenderv1.ExtenderBindingResult, error) {
klog.InfoS("Bind", "pod", args.PodName, "namespace", args.PodNamespace, "podUID", args.PodUID, "node", args.Node)
var err error
var res *extenderv1.ExtenderBindingResult
binding := &corev1.Binding{
ObjectMeta: metav1.ObjectMeta{Name: args.PodName, UID: args.PodUID},
Target: corev1.ObjectReference{Kind: "Node", Name: args.Node},
}
current, err := s.kubeClient.CoreV1().Pods(args.PodNamespace).Get(context.Background(), args.PodName, metav1.GetOptions{})
if err != nil {
klog.ErrorS(err, "Get pod failed")
}
node, err := s.kubeClient.CoreV1().Nodes().Get(context.Background(), args.Node, metav1.GetOptions{})
if err != nil {
klog.ErrorS(err, "Failed to get node", "node", args.Node)
s.recordScheduleBindingResultEvent(current, EventReasonBindingFailed, []string{}, fmt.Errorf("failed to get node %v", args.Node))
res = &extenderv1.ExtenderBindingResult{Error: err.Error()}
return res, nil
}
tmppatch := make(map[string]string)
for _, val := range device.GetDevices() {
err = val.LockNode(node, current)
if err != nil {
goto ReleaseNodeLocks
}
}
tmppatch[util.DeviceBindPhase] = "allocating"
tmppatch[util.BindTimeAnnotations] = strconv.FormatInt(time.Now().Unix(), 10)
err = util.PatchPodAnnotations(current, tmppatch)
if err != nil {
klog.ErrorS(err, "patch pod annotation failed")
}
if err = s.kubeClient.CoreV1().Pods(args.PodNamespace).Bind(context.Background(), binding, metav1.CreateOptions{}); err != nil {
klog.ErrorS(err, "Failed to bind pod", "pod", args.PodName, "namespace", args.PodNamespace, "podUID", args.PodUID, "node", args.Node)
}
if err == nil {
s.recordScheduleBindingResultEvent(current, EventReasonBindingSucceed, []string{args.Node}, nil)
res = &extenderv1.ExtenderBindingResult{Error: ""}
klog.Infoln("After Binding Process")
return res, nil
}
ReleaseNodeLocks:
klog.InfoS("bind failed", "err", err.Error())
for _, val := range device.GetDevices() {
val.ReleaseNodeLock(node, current)
}
s.recordScheduleBindingResultEvent(current, EventReasonBindingFailed, []string{}, err)
return &extenderv1.ExtenderBindingResult{Error: err.Error()}, nil
}
核心部分:
binding := &corev1.Binding{
ObjectMeta: metav1.ObjectMeta{Name: args.PodName, UID: args.PodUID},
Target: corev1.ObjectReference{Kind: "Node", Name: args.Node},
}
if err = s.kubeClient.CoreV1().Pods(args.PodNamespace).Bind(context.Background(), binding, metav1.CreateOptions{}); err != nil {
klog.ErrorS(err, "Failed to bind pod", "pod", args.PodName, "namespace", args.PodNamespace, "podUID", args.PodUID, "node", args.Node)
}
调用 api 创建了一个 binding 对象,将 Pod 调度到指定节点即可。
至此,Scheduler 的逻辑我们就分析完了,调度完成 Kubelet 就开始启动 Pod 了,然后 hami 的 device plugin 也要开始发挥作用了。
小结
这里 HAMi 是使用默认的 kube-scheduler 镜像额外启动了一个 scheduler,但是通过配置把名称指定为了 hami-scheduler。
然后给这个 hami-scheduler 配置了 Extender,Extender 服务就是同 Pod 中的另一个 Container 启动的一个 http 服务。
ps:我们说的 hami-scheduler 一般只这部分 Extender 实现的调度插件
然后在调度可以分为两部分:
-
获取 GPU 信息
(从 Node Annoations 中获取节点上的 GPU 资源信息) (从 Pod Annoations 中获取 GPU 的使用情况) -
按配置策略进行节点选择并完成调 (直接在 Filter 接口按照得分排序后返回最推荐的一个节点,以实现完全控制调度结果)
- 按照 GPU memory、core 剩余情况计算得分,剩余资源越多得分越低
5.小结
本文主要分析了 hami-scheduler 的实现原理,其中包含两个组件:
-
Webhook:根据 Pod Resource 中的 ResourceName 判断该 Pod 是否使用的 HAMi vGPU,如果是则修改 Pod 的 SchedulerName 为 hami-scheduler,让 hami-scheduler 进行调度。
-
Scheduler:以 kube-shceduler 为镜像启动服务并改名为 hami-scheduler,然后通过配置 extender 接入真正的 hami-scheduler 逻辑。(从 Node 的 Annoations 上解析拿到 GPU 资源信息,从已经运行的 Pod Annoations 上解析拿到 Pod 消耗的 GPU 资源计算出每个 Node 上真实可用的 GPU 资源)(根据节点剩余资源进行打分,然后根据配置的 Spread、Binpack 调度策略选择得分最高或最低的节点,将 Pod 进行调度。)
HAMi Webhook、Scheduler 工作流程如下
-
用户创建 Pod 并在 Pod 中申请了 vGPU 资源
-
kube-apiserver 根据 MutatingWebhookConfiguration 配置请求 HAMi-Webhook
-
HAMi-Webhook 检测 Pod 中的 Resource,如果申请的由 HAMi 管理的 vGPU 资源,就会把 Pod 中的 SchedulerName 改成了 hami-scheduler,这样这个 Pod 就会由 hami-scheduler 进行调度了。
-
对于特权模式的 Pod,Webhook 会直接跳过不处理
-
对于使用 vGPU 资源但指定了 nodeName 的 Pod,Webhook 会直接拒绝
- hami-scheduler 进行 Pod 调度,不过就是用的 k8s 的默认 kube-scheduler 镜像,因此调度逻辑和默认的 default-scheduler 是一样的,但是 kube-scheduler 还会根据 KubeSchedulerConfiguration 配置,调用 Extender Scheduler 插件
-
这个 Extender Scheduler 就是 hami-scheduler Pod 中的另一个 Container,该 Container 同时提供了 Webhook 和 Scheduler 相关 API。
-
当 Pod 申请了 vGPU 资源时,kube-scheduler 就会根据配置以 HTTP 形式调用 Extender Scheduler 插件,这样就实现了自定义调度逻辑
- Extender Scheduler 插件包含了真正的 hami 调度逻辑,调度时根据节点剩余资源量进行打分选择节点
- 这里就包含了 spread & binpark 等 高级调度策略的实现
- 异步任务,包括 GPU 感知逻辑
-
devicePlugin 中的后台 Goroutine 定时上报 Node 上的 GPU 资源并写入到 Node 的 Annoations
-
除了 DevicePlugin 之外,还使用异步任务以 Patch Annotation 方式提交更多信息
-
Extender Scheduler 插件根据 Node Annoations 解析出 GPU 资源总量、从 Node 上已经运行的 Pod 的 Annoations 中解析出 GPU 使用量,计算出每个 Node 剩余的可用资源保存到内存供调度时使用
至此,HAMi Webhook、Scheduler 就分析完了,spread & binpark 等 高级调度策略是如何实现的留着下篇分析~。
想了解更多 HAMi 项目信息,请访问 GitHub 仓库 或加入我们的 Slack 社区。