千卡集群升级后 Hami vGPU 调度失败解决方案
本文来自 HAMi 社区开发者范会杨的投稿,详细记录了一个中大规模 GPU 集群(200 节点)从 Volcano 1.7 升级到 Volcano 1.12 + hami-dp 后,vGPU 调度延迟从秒级恶化到十几分钟的排查与解决全过程。文章从节点注解机制、握手机制出发,层层剖析根因(API Server 限流 → Patch 延迟 → 资源视图超时),并给出了删除握手机制、优化注解更新策略的修改方案,最终经过多轮验证确认修复有效。如果你也在大规模集群中使用 Hami vGPU,这篇文章会是一个很好的参考。
问题描述
200 个 NVIDIA 节点的云池从 Volcano 1.7 + volcano-dp 升级到 Volcano 1.12 + hami-dp 后,启动申请 GPU 的测试任务调度极慢,耗时十几分钟才能成功调度,严重影响了业务效率。
背景知识
节点注解机制
在 Volcano + hami-dp 配合使用的环境中,hami-dp Pod 会扫描节点上的 GPU 信息,给节点打上如下注解:
volcano.sh/node-vgpu-handshake:握手注解,用于 hami-dp 与调度器之间的状态同步volcano.sh/node-vgpu-register:GPU 资源注册注解,记录 GPU 详细信息
注册注解格式解析:
GPU-f571c8f8-948a-71b4-3be1-2bf02c7a1b20,10,32768,NVIDIA-Tesla V100S-PCIE-32GB,true,hami-core
| 字段 | 含义 |
|---|---|
GPU-xxx | GPU 的 UUID |
10 | 一个物理 GPU 生成 10 个 gpu-number 资源,限制一个物理 GPU 最多被挂载给 10 个 Pod |
32768 | GPU 显存大小(MB) |
NVIDIA-Tesla V100S-PCIE-32GB | GPU 型号 |
true | 健康状态,true 表示 healthy |
hami-core | 切分模式,hami-core 或者 mig |
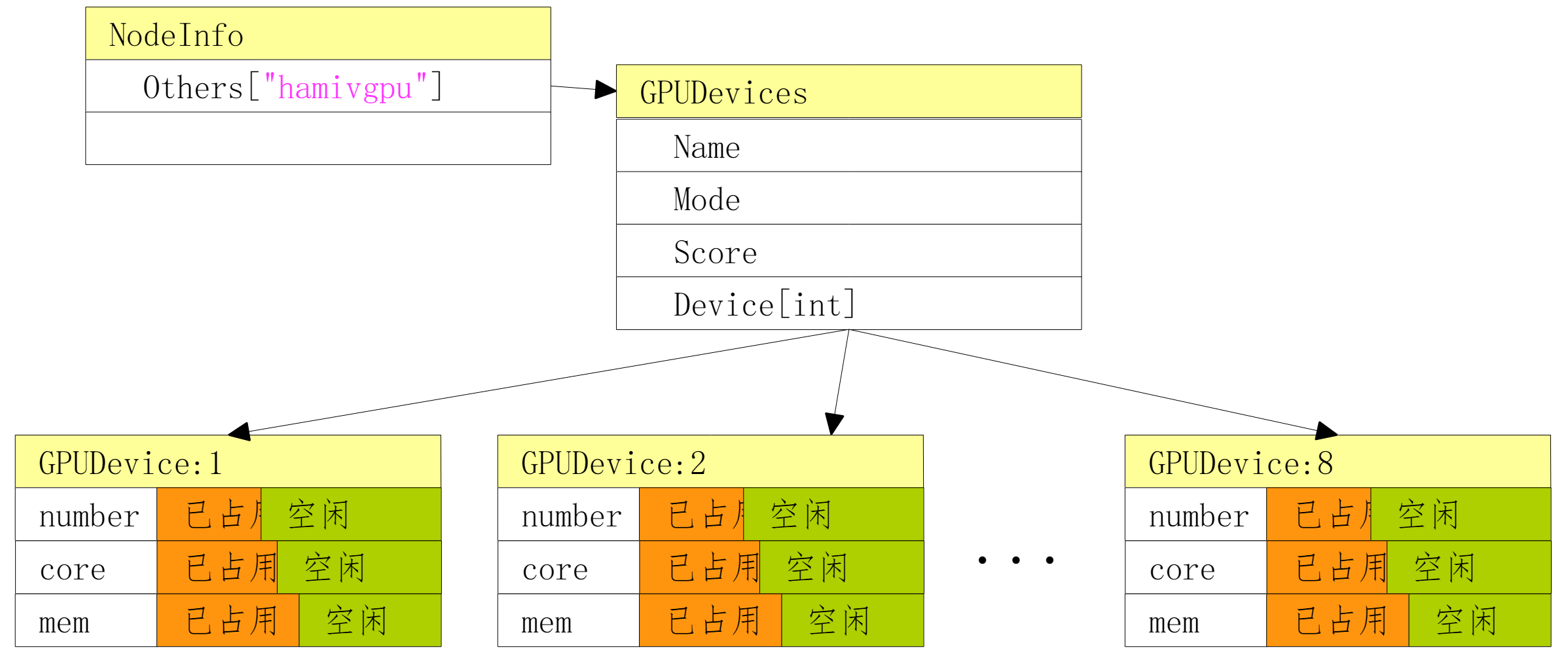
资源视图
Volcano-scheduler 根据以上节点注解生成 hami vGPU 资源视图,对节点上 GPU 数量、每个 GPU 的 gpu-number 数量、显存数量、算力百分比三个维度的资源总量进行记录。
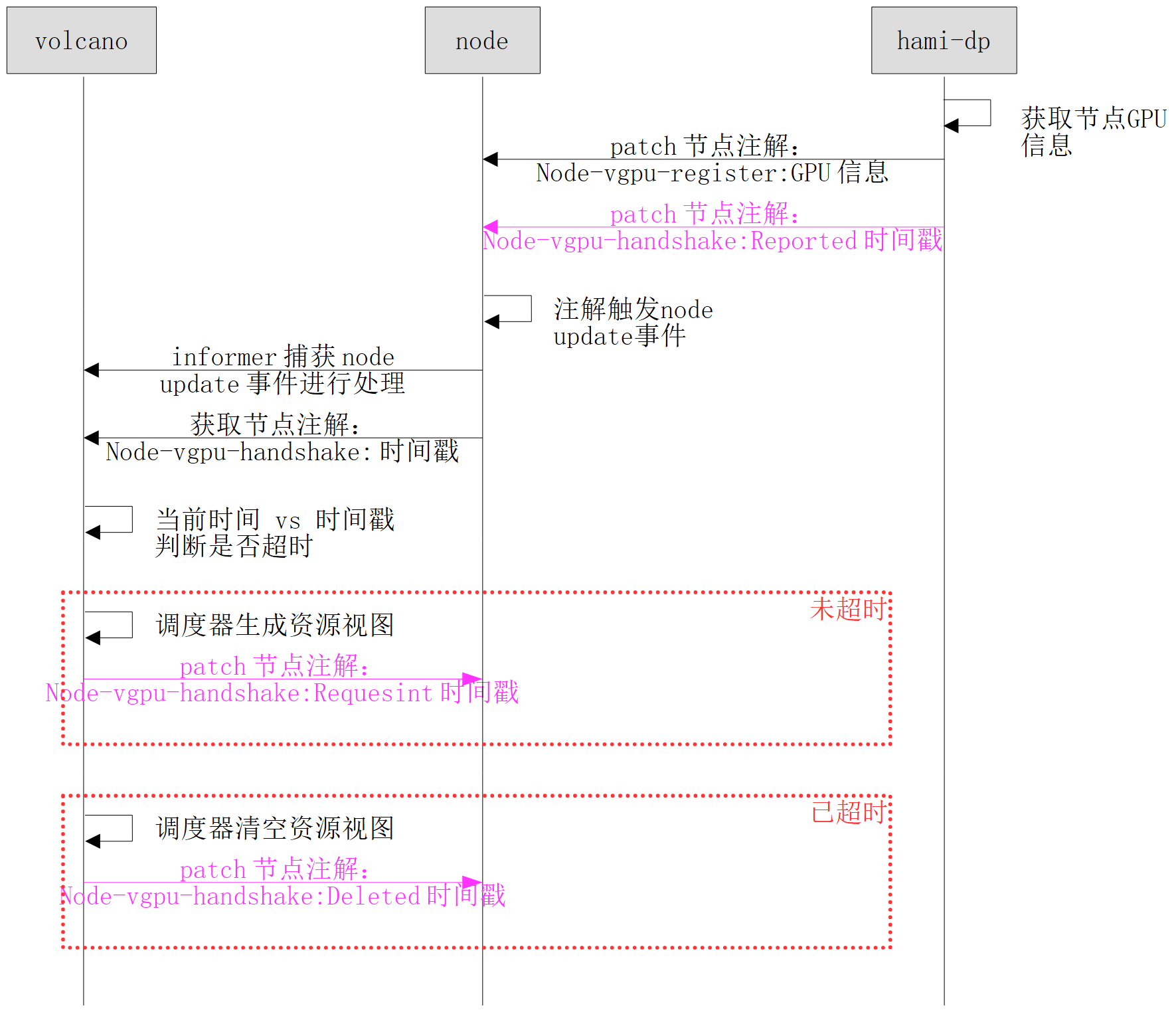
握手机制
为保证 GPU 掉卡或 hami-dp Pod 卡死等原因导致的 GPU 资源量变化被 volcano-scheduler 及时感知,hami-dp 和 volcano-scheduler 之间通过节点注解实现了握手机制:
- hami-dp 侧:在更新
node-vgpu-register注解时,同时给节点 patch 上握手注解,并触发 node update 事件 - volcano-scheduler 侧:处理 node update 事件时,对节点握手注解中的时间戳进行判断
握手状态流转:
- 如果注解值是
Reported + 时间戳,调度器修改注解值为Requesting + 时间戳 - 如果注解值是
Requesting + 时间戳,且当前时间距离时间戳小于 60s,生成资源视图 - 如果注解值是
Requesting + 时间戳,且当前时间距离时间戳大于 60s,清空资源视图,修改注解值为Deleted + 时间戳 - 如果注解值是
Deleted + 时间戳,清空资源视图
调度器握手代码:
if strings.Contains(handshake, "Requesting") {
formertime, _ := time.Parse("2006.01.02 15:04:05", strings.Split(handshake, "_")[1])
if time.Now().After(formertime.Add(time.Second * 60)) {
klog.Infof("node %v device %s leave", node.Name, handshake)
tmppat := make(map[string]string)
tmppat[deviceconfig.VolcanoVGPUHandshake] = "Deleted_" + time.Now().Format("2006.01.02 15:04:05")
patchNodeAnnotations(node, tmppat)
return nil
}
} else if strings.Contains(handshake, "Deleted") {
return nil
} else {
tmppat := make(map[string]string)
tmppat[deviceconfig.VolcanoVGPUHandshake] = "Requesting_" + time.Now().Format("2006.01.02 15:04:05")
patchNodeAnnotations(node, tmppat)
}
握手频率问题:hami-dp 给节点更新握手注解的频率是 30s 一次,集群中 200 个 NVIDIA 节点上的 dp pod 都会给节点 patch 注解,同时 patch 触发的 node update 事件也会触发 scheduler 给节点 patch 注解。即每 30s 有 400 次 patch node 注解操作。
问题原因
经排查,问题的根因链如下:
- 注解操作过多:由于集群中 NVIDIA 节点较多,每个节点上都有 hami-dp Pod 周期性给节点 patch 注解,过多的 patch node 注解操作触发了 API Server 限流
- Patch 延迟:API Server 限流限制了调度器给节点打 patch,每次打 patch 被延迟接近 200ms
- 视图生成阻塞:打 patch 延迟阻塞了 hami vGPU 资源视图的生成
- 视图超时清空:由于集群中大量节点的 GPU 资源几乎被占满,只有少数几个节点可用。这几个节点生成 vGPU 视图时已经超时,视图被清空,导致当轮调度不成功。多轮以后才成功,因此一个测试 Pod 需要十几分钟后才能调度成功
日志佐证:
- 一个调度周期(Start 到 End scheduling)耗时为 52 秒,正常应该为 1s 内

- 一个调度周期内,patch 被延迟执行 260 次,每次接近 200ms

- 一个调度周期内,多个节点生成 vGPU 视图前已经超时
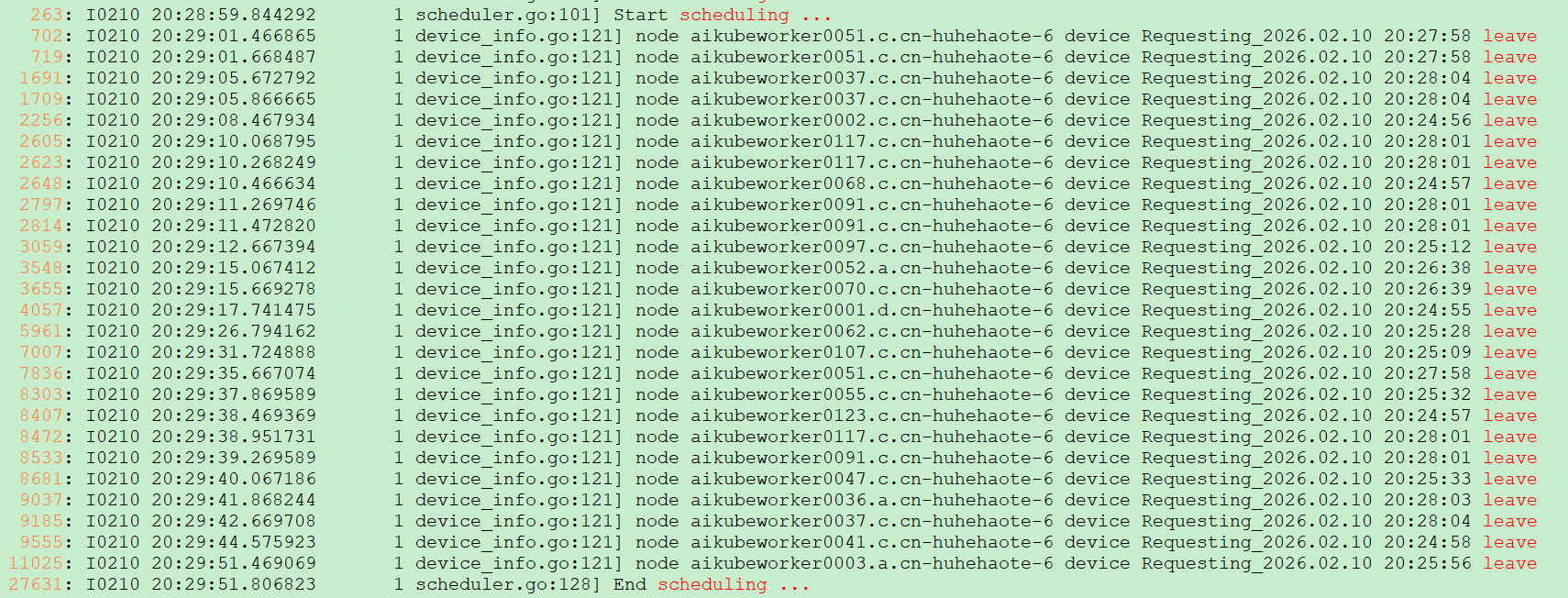
- 一个调度周期内,50 多秒后才开始处理调度任务

修改方案
核心思路
删掉 volcano-scheduler 和 hami-dp 之间通过 patch node 注解进行握手的机制,scheduler 和 hami-dp 都删掉处理 volcano.sh/node-vgpu-handshake 注解的相关代码。
具体修改
hami-dp 修改:
- 新增注解判断:实时获取设备封装成的注解 vs 节点已存在的注解,如果二者不一致再更新节点上的注解
Scheduler 修改:
- 新增
node.status.allocatable中 vGPU 资源的判断:如果没有 vGPU 资源直接清空视图(应对 dp Pod 挂死,注解无法更新的场景),如果有资源再根据节点注解生成 vGPU 资源视图
调度器优化:
- 删掉 node update 事件触发遍历 node 上 pod 进行资源使用统计的逻辑。**原因:**现有代码中,给节点 patch 注解或者标签这种完全不影响资源占用统计的 update 事件,也会触发遍历节点上所有 pod 进行资源占用统计,完全没有必要,反而增加了调度开销。
GPU 冲突修复:
- 同节点申请相同 gpu-number 数量的 Pod 缓 bind,规避 kubelet 调用 dp 时没传递 Pod 信息造成的 Pod 混乱问题。
**说明:**以上修改中的「对 Volcano 1.7 启动的旧 GPU Pod 的兼容」和「hami-vgpu 抢占功能(队列间抢占、队列内抢占)」为内部自研实现,当前社区代码暂不支持。贡献开源代码需走公司审批流程,后续计划提交社区。目前该方案内部也尚未上线,处于测试验证阶段。
修改验证
1. 握手注解不再变化
替换镜像后,节点上的 handshake 注解保持为修改前 dp patch 上的值,不再变化:
volcano.sh/node-vgpu-handshake: Reported 2026-05-25 07:58:20.213111834 +0000 UTC
2. 模拟 hami-dp Pod 卡死
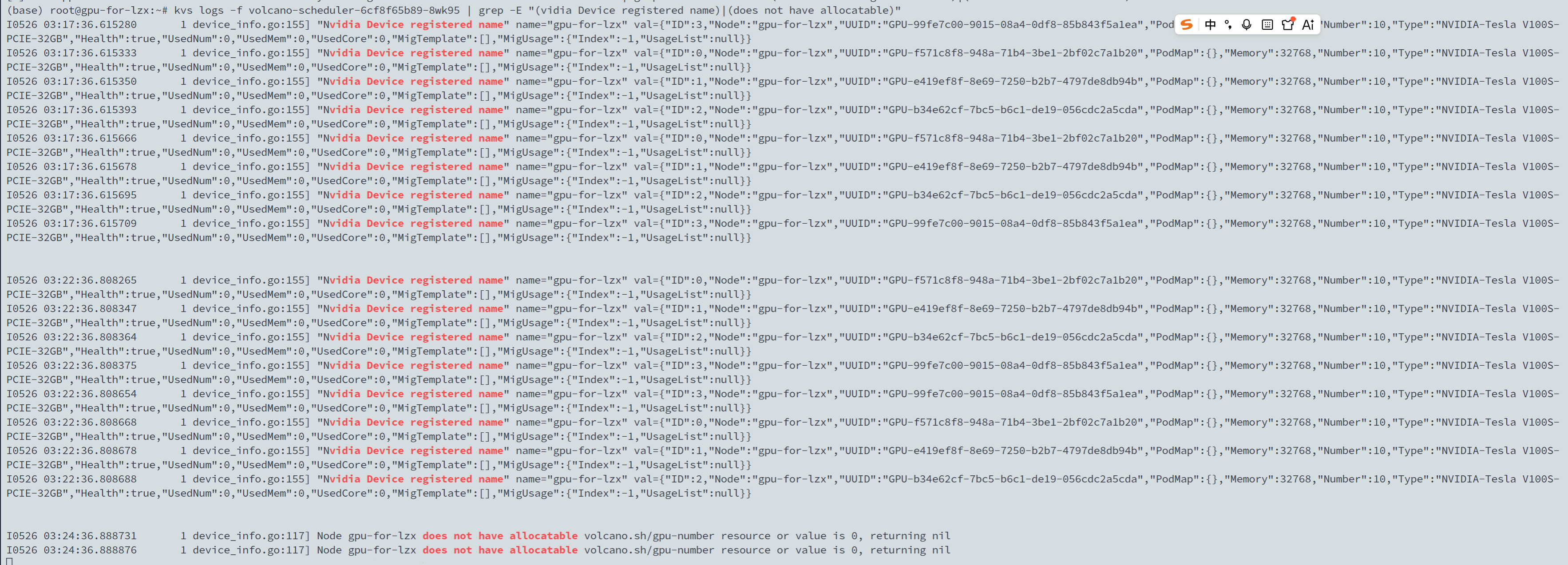
验证结果:dp Pod 卡死后,启动 GPU Pod 无法调度,符合预期。dp 重新启动后,调度器可感知资源变化,调度成功,符合预期。

3. 队列间整卡抢占测试
测试步骤:先启动 4 个低优任务占用 4 张 GPU,依次启动高优任务抢占 GPU,再删除高优任务回收 GPU。
验证结果:所有 GPU UUID 均不重复,抢占和回收行为完全符合预期。
4. 队列间 vGPU 抢占测试
测试场景一:vGPU 抢占 vGPU
- 启动 4 副本低优任务(每副本 4 卡,每卡 25%),启动高优任务(4 卡,每卡 60%)
- 高优任务驱逐 3 个低优任务,删除高优任务后低优任务恢复运行
测试场景二:pGPU 抢占 vGPU
- 启动高优任务申请 4 张整卡,低优任务全部驱逐
- 删除高优任务后,低优任务恢复运行
测试场景三:vGPU 抢占 pGPU
- 启动低优任务(4 副本,每副本一张整卡),启动高优任务(4 GPU,每卡 60%)
- 低优任务全部驱逐,删除高优任务后恢复运行
验证结果:所有场景均符合预期,GPU UUID 无重复。
5. 队列内 vGPU 抢占测试
测试步骤:启动低优任务(非 gang 调度),启动高优任务抢占,删除高优任务后回收。
验证结果:抢占和回收行为符合预期。
6. 旧 volcano-dp 兼容性测试
测试步骤:
- 使用旧 dp 启动占用 2 个 GPU 的 Pod
- 更换 hami-dp,更改调度器配置使用 hami-dp 的资源
- 再启动两个 Pod,检查 GPU 没有冲突
- 删除旧 Pod 后,使用 hami vGPU 重新启动
验证结果:新旧 Pod 的 GPU UUID 均不重复,兼容性良好。
总结
本次问题的根因是大规模集群中 hami-dp 与 volcano-scheduler 之间的握手机制产生了过多的 patch node 注解操作,导致 API Server 限流,进而阻塞了 vGPU 资源视图的生成。通过删除握手机制、优化注解更新策略和资源视图判断逻辑,彻底解决了调度延迟问题。经过多轮验证(包括 dp 卡死感知、整卡抢占、vGPU 抢占、队列内抢占和旧 dp 兼容性),所有功能均符合预期。