【原理解析】HAMi 扩展 ResourceQuota | 精准的 GPU 资源配额管理实现详解
HAMi 社区在 v2.7.0 版本中,针对原生 Kubernetes ResourceQuota 在 GPU 等异构算力场景下的局限性,推出了一套扩展 ResourceQuota 机制。此特性旨在解决原生配额管理无法处理的"资源关联"与"动态资源"两大痛点,为多租户环境下的 GPU 资源治理提供了更为精准、可靠的控制能力。
本文将在功能介绍的基础上,深入代码实现,详细剖析 HAMi 扩展 ResourceQuota 的具体设计与实现原理。
核心痛点:原生 ResourceQuota 的两大局限性
1. 无法理解资源关联
原生 ResourceQuota 独立计算每项资源,无法理解其内在关联。例如,当一个 Pod 请求 2 个 GPU,每个分配 2000MB 显存时(nvidia.com/gpu: 2, nvidia.com/gpumem: 2000),原生 Quota 会错误地将总显存需求记为 2000MB,而不是正确的 2 * 2000MB = 4000MB。这导致配额管理严重失真。
2. 无法处理动态资源
对于按百分比申请显存的请求(如 gpumem-percentage: 50),其实际显存占用量只有在调度决策完成后(即确定了具体分配到哪一块物理 GPU 上)才能计算出来。原生 ResourceQuota 在调度前进行检查,无法处理这种需要"先调度,后扣减"的动态资源值。
解决方案:增强型 ResourceQuota
HAMi 的解决方案并非替代或重写原生 ResourceQuota,而是在其之上,在 HAMi 调度器构建了一个轻量级、非侵入式的增强层。其核心工作原理是:HAMi 调度器会监控标准的 ResourceQuota 对象,当发现其中定义了由 HAMi 所管理的、且以 limits. 为前缀的资源时(如 limits.nvidia.com/gpumem),便会在自己的调度周期内对这些资源执行配额检查,从而应用其更为精细的计算规则。
原理实现:代码深度解析
HAMi 对扩展 ResourceQuota 的处理,其核心分为 "配额同步" 和 "调度时检查" 两个阶段。
1. 阶段一:配额同步 - 监听与缓存
此阶段的目标是将 K8s 集群中带有 limits. 前缀的 ResourceQuota 对象,同步到一个由 HAMi 调度器自身维护的本地缓存中。
监听与识别
HAMi 调度器通过 Informer 机制监听集群中 ResourceQuota 对象的增删改事件。当事件发生时,onAddQuota 等事件处理器会被触发。
前缀过滤与缓存
在 AddQuota 函数中,代码会遍历 ResourceQuota 对象中 spec.hard 定义的所有资源项。只有那些以 limits. 为前缀的资源项才会被识别并处理。随后,资源名称会被剥离前缀,并连同其限制值(Limit)一同存入一个全局的 QuotaManager 缓存中。
其核心实现位于 pkg/device/quota.go:
// File: pkg/device/quota.go
// AddQuota 将 K8s ResourceQuota 对象中的扩展资源同步到本地缓存
func (q *QuotaManager) AddQuota(quota *corev1.ResourceQuota) {
q.mutex.Lock()
defer q.mutex.Unlock()
for idx, val := range quota.Spec.Hard {
value, ok := val.AsInt64()
if ok {
// 1. 检查是否存在 "limits." 前缀
if !strings.HasPrefix(idx.String(), "limits.") {
continue
}
// 2. 剥离前缀,得到真实的资源名称
dn := strings.TrimPrefix(idx.String(), "limits.")
if !IsManagedQuota(dn) { // 检查是否是 HAMi 管理的资源类型
continue
}
// ...
// 3. 将资源和其 Limit 值写入本地缓存
(*dp)[dn].Limit = value
// ...
}
}
}
2. 阶段二:调度时检查 - 迭代式的逐卡验证
这是 HAMi 扩展 ResourceQuota 实现其智能计算能力的核心所在。当一个 Pod 进入调度流程后,其配额检查并非一次性的"总量"计算,而是在设备端的 Fit() 函数中,伴随着为 Pod 寻找合适物理卡的过程,以一种循环迭代、逐卡验证的方式完成的。
其决策流程如下图所示:
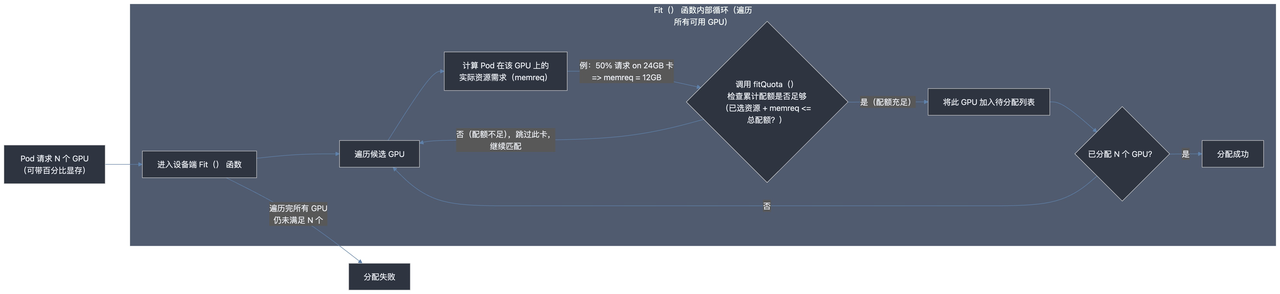
该流程通过以下方式,解决了"资源关联"和"动态资源"这两大难题:
动态资源计算
在 Fit() 函数的循环内部,当检查每一张具体的物理卡时,代码会根据这张卡的实际硬件规格(如 dev.Totalmem)来计算 Pod 请求的动态资源(如百分比显存)应转换成的具体数值。
资源关联计算
fitQuota 函数在检查时,会考虑当前 Pod 内已经选定要分配的卡(tmpDevs)和正要尝试分配的这张新卡的资源总和。这确保了当 Pod 请求多个设备时,其关联的资源(如总显存)是被累加计算的。
其核心实现位于 pkg/device/nvidia/device.go:
// File: pkg/device/nvidia/device.go
// Fit 函数 (简化逻辑)
func (nv *NvidiaGPUDevices) Fit(...) (bool, map[string]device.ContainerDevices, string) {
// ...
// 循环遍历节点上所有可用的 GPU 设备
for i := len(devices) - 1; i >= 0; i-- {
dev := devices[i]
memreq := int32(0)
// 1. 动态资源计算:
// 如果请求的是百分比显存,则根据当前 dev 卡的实际总显存进行计算
if k.MemPercentagereq != 101 && k.Memreq == 0 {
memreq = dev.Totalmem * k.MemPercentagereq / 100
}
// 2. 关联资源检查 (调用 fitQuota):
// 检查 "已为本 Pod 分配的资源 + 当前这张卡的资源" 是否超出配额
if !fitQuota(tmpDevs, pod.Namespace, int64(memreq), int64(k.Coresreq)) {
continue // 配额不足,跳过此卡
}
// ... (其他检查) ...
// 如果检查通过,将此卡加入待分配列表 tmpDevs
tmpDevs[k.Type] = append(tmpDevs[k.Type], ...)
if k.Nums == 0 {
return true, tmpDevs, "" // 已满足 Pod 请求的卡数量,分配成功
}
}
// ...
}
// fitQuota 负责调用核心的配额检查逻辑
func fitQuota(tmpDevs map[string]device.ContainerDevices, ns string, memreq int64, coresreq int64) bool {
mem := memreq
core := coresreq
// 将待分配列表中的资源累加
for _, val := range tmpDevs[NvidiaGPUDevice] {
mem += int64(val.Usedmem)
core += int64(val.Usedcores)
}
// 调用 QuotaManager 的缓存进行最终检查
return device.GetLocalCache().FitQuota(ns, mem, core, NvidiaGPUDevice)
}
3. 行为差异与实现说明
需要注意的是,HAMi 的扩展 ResourceQuota 机制在实现和行为上与原生 ResourceQuota 存在两个关键差异:
独立的内部状态
HAMi 的配额计算(如 2 * 2000MB = 4000MB)与用量统计,完全在其调度器内部的 QuotaManager 缓存中进行,不会写回到 Kubernetes 原生的 ResourceQuota 对象的 status 字段。这意味着通过 kubectl describe resourcequota 查看到的 used 字段,无法反映由 HAMi 管理的扩展资源的真实用量。
调度失败行为
当一个 Pod 的资源请求超出了 HAMi 管理的配额时,其行为与原生 ResourceQuota 不同。原生机制下,超额的 Pod 会在创建时被 API Server 直接拒绝。而在 HAMi 的机制下,Pod 对象会被成功创建,但会被 HAMi 调度器判定为不可调度,使其保持在 Pending 状态,直到配额被释放或调整。
使用方式
用户只需在标准的 ResourceQuota 对象中,为你希望由 HAMi 进行精细化管理的资源名称加上 limits. 前缀即可。
apiVersion: v1
kind: ResourceQuota
metadata:
name: gpu-quota
namespace: default
spec:
hard:
limits.nvidia.com/gpu: "2"
limits.nvidia.com/gpumem: "4000"
总结
HAMi 扩展 ResourceQuota 的设计并未修改原生控制器,而是通过在 HAMi 调度器中实现的独立检查逻辑来扩展功能。其核心在于为 Pod 筛选物理设备时,通过计算每个候选设备的动态资源并累加验证,解决了原生机制无法处理动态和关联资源的问题。
参考资料
再次由衷感谢社区开发者 @FouoF 对该特性的贡献!