【Run:ai KAI-Scheduler 深度解析】补充篇:解密 Reservation Pod 如何获知 GPU 分配细节
昨天我们发布的[《Nvidia 收购 Run:ai 后开源的 KAI-Scheduler vs HAMi:GPU 共享的技术路线分析与协同展望》](https://dynamia.ai/zh/blog/Run ai- KAI-scheduler vs hami)深入探讨了 KAI-Scheduler 如何实现 GPU 分数共享,非常感谢大家的关注和热烈讨论!特别是有读者指出了一个关键技术细节需要进一步澄清,今天我们就来专门解析这个问题。
读者反馈与技术澄清
有读者在评论中提到:
“文章里少了一个关键的技术点没有讲,就是 GPU 的卡分配是由 device plugin 负责分配的,那么当 reservation pod 调度成功的时候,还不知道是哪个卡,没有办法更新 GpuSharingNodeInfo”
这个问题切中要害!不过,首先,我们需要对 GPU 资源分配的责任主体进行更准确的阐述:
实际上,调度决策完成后,GPU 设备资源的分配涉及三个关键组件的协作:
-
设备发现与资源报告(NVIDIA Device Plugin) NVIDIA Device Plugin 负责在节点上发现可用的物理 GPU,并通过 Kubernetes 的 Device Plugin API 将这些设备注册给 kubelet(如 nvidia.com/gpu)。它还会持续报告设备的健康状态,并在 kubelet 请求资源分配时,返回容器运行所需的挂载信息和环境变量。
-
资源分配决策与设备选择(kubelet) kubelet 负责在 Pod 被调度到本节点后,决定使用哪块具体的 GPU 设备。它根据 Device Plugin 上报的设备列表和健康状态,从未被分配的设备中选择所需数量的 GPU,并调用 Device Plugin 的 Allocate() 接口,传入所选设备的 ID。此过程发生在 Pod 启动之前,是实际资源分配的决策点。
-
设备挂载与运行时配置(NVIDIA Container Runtime) 当容器启动时,NVIDIA Container Runtime(作为 containerd 或 Docker 的扩展)根据 kubelet 传入的环境变量(如 NVIDIA_VISIBLE_DEVICES)和挂载信息,将对应的物理 GPU 设备节点和驱动库挂载到容器中,确保容器内的应用可以正常访问 GPU。
这一责任分离对本文要解决的核心问题同样十分关键:当 KAI-Scheduler 创建 Reservation Pod 后,它如何精确获知该 Pod 被分配了哪个具体的物理 GPU 设备?
如果不知道这个关键信息,KAI-Scheduler 就无法准确更新其内部维护的 GpuSharingNodeInfo(我们昨天提到的内部记账本),也就无法跟踪哪块物理 GPU 的资源被占用了多少。
那么,KAI-Scheduler 是如何打通这“最后一公里”的信息壁垒的呢?今天这篇补充文章,我们就来揭秘这个过程。
回顾:Reservation Pod 机制
KAI-Scheduler 的核心创新是引入 Reservation Pod 机制,解决原生 Kubernetes 不支持 GPU 分数共享的问题:
-
用户 Pod 请求 0.5 个 GPU 时,KAI-Scheduler 创建一个 Reservation Pod
-
这个 Pod 向 Kubernetes 请求一整个 GPU 资源
-
Kubernetes 将一个完整的物理 GPU 分配给该 Pod
-
KAI-Scheduler 在内部管理这个被"预留"的 GPU,实现多个用户 Pod 共享同一个物理 GPU
完整的 Pod 调度与 GPU 分配流程
为了更清晰地理解整个过程,让我们详细梳理从用户提交 Pod 到最终获取 GPU 资源的完整流程:
1. 用户 Pod 的调度决策
- 由 KAI-Scheduler 进行调度决策:
(1) KAI-Scheduler 接收到用户 Pod 请求
(2) 通过其内部的调度策略(包括各种插件如 gpuspread 或 gpupack)评估哪个节点适合运行该 Pod
(3) 计算该 Pod 应当在哪个节点上运行,以及使用哪个 GPU(现有的或新的 GPU 组)
- 节点和 GPU 选择过程:
// pkg/scheduler/gpu_sharing/gpuSharing.go
func AllocateFractionalGPUTaskToNode(
ssn *framework.Session,
stmt *framework.Statement,
pod *pod_info.PodInfo,
node *node_info.NodeInfo,
isPipelineOnly bool,
) bool {
// 获取适合该节点上的 GPU 列表
fittingGPUs := ssn.FittingGPUs(node, pod)
// 根据策略选择最合适的 GPU
gpuForSharing := getNodePreferableGpuForSharing(fittingGPUs, node, pod, isPipelineOnly)
if gpuForSharing == nil {
return false
}
// 将选择的 GPU 组分配给 Pod
pod.GPUGroups = gpuForSharing.Groups
// 后续分配逻辑...
return true
}
2. Reservation Pod 的创建与调度
一旦 KAI-Scheduler 确定了节点和 GPU 选择,就会进入绑定阶段:
- 创建 Reservation Pod:
(1) 如果需要使用新的 GPU,KAI-Scheduler 会通过 ReserveGpuDevice 函数创建一个 Reservation Pod
(2) 这个 Pod 被设置了 NodeName,明确指定应当在哪个节点上运行
(3) Reservation Pod 请求一个完整的 GPU 资源
// pkg/binder/binding/resourcereservation/resource_reservation.go
// createGPUReservationPod 在指定节点上创建一个 GPU 资源预留 Pod
func (rsc *service) createGPUReservationPod(ctx context.Context, nodeName, gpuGroup string) (*v1.Pod, error) {
podName := fmt.Sprintf("%s-%s-%s",
gpuReservationPodPrefix,
nodeName,
rand.String(reservationPodRandomCharacters),
)
resources := v1.ResourceRequirements{
Limits: v1.ResourceList{
constants.GpuResource: *resource.NewQuantity(numberOfGPUsToReserve, resource.DecimalSI),
},
}
return rsc.createResourceReservationPod(nodeName, gpuGroup, podName, gpuReservationPodPrefix, resources)
}
// createResourceReservationPod 创建通用资源预留 Pod(固定节点,不经过调度器)
func (rsc *service) createResourceReservationPod(
nodeName, gpuGroup, podName, appName string,
resources v1.ResourceRequirements,
) (*v1.Pod, error) {
podSpec := &v1.Pod{
ObjectMeta: metav1.ObjectMeta{
Name: podName,
Namespace: namespace,
Labels: map[string]string{
constants.AppLabelName: appLabelValue,
constants.GPUGroup: gpuGroup,
runaiResourceReservationAppLabelName: appName,
},
},
Spec: v1.PodSpec{
NodeName: nodeName, // 显式指定节点,不经过调度器
Containers: []v1.Container{
{
Name: resourceReservation,
Image: rsc.reservationPodImage, // 轻量级镜像
Resources: resources,
},
},
},
}
return podSpec, rsc.kubeClient.Create(context.Background(), podSpec)
}
- 跳过调度器直接指定节点:
(1) Reservation Pod 在创建时已经设置了 NodeName 字段
(2) 这意味着该 Pod 不会经过任何调度器(包括默认调度器)的调度流程
(3) 它会直接被分配到指定节点上,该节点的 kubelet 负责启动 Pod
- 等待 GPU 分配:
(1) KAI-Scheduler 创建 Reservation Pod 后,会阻塞等待该 Pod 获取实际的 GPU 设备 UUID
(2) 等待过程中,Pod 会被 NVIDIA Container Runtime 分配物理 GPU 设备
信息获取难题
在上述流程中,存在一个关键的信息差:当 Reservation Pod 被成功调度后,KAI-Scheduler 并不立即知道这个 Pod 被分配到了节点上的哪个具体物理 GPU 设备。
而没有这个信息,KAI-Scheduler 就无法准确更新其内部的 GpuSharingNodeInfo(用于记录每个物理 GPU 已分配的资源情况)。
这里展示了 KAI-Scheduler 内部的 GpuSharingNodeInfo 结构需要记录的信息:
// pkg/scheduler/api/node_info/gpu_sharing_node_info.go
// GpuSharingNodeInfo 记录节点上 GPU 共享使用的实时状态
type GpuSharingNodeInfo struct {
// 正在释放的共享 GPU(key = GPU ID)
ReleasingSharedGPUs map[string]bool
// 已实际使用的显存(字节)
UsedSharedGPUsMemory map[string]int64
// 正处于释放过程中的显存(字节)
ReleasingSharedGPUsMemory map[string]int64
// 已分配给 Pod 但尚未实际占用的显存(字节)
AllocatedSharedGPUsMemory map[string]int64
}
一、精妙解决方案:自检探测 + Watch 机制
KAI-Scheduler 通过以下设计巧妙解决了这个问题:
1 设备信息上报容器
Reservation Pod 容器运行一个小型应用程序(cmd/resourcereservation),它能够读取到 NVIDIA Container Runtime 为 Pod 挂载的 GPU 设备信息。
下面是这个设备信息上报容器如何获取 GPU 设备 UUID 的关键代码:
// pkg/resourcereservation/discovery/discovery.go
package discovery
import (
"context"
"fmt"
"os"
"path/filepath"
"strings"
)
const gpusDir = "/proc/driver/nvidia/gpus/"
// GetGPUDevice 返回指定 Pod 所在节点上对应的 GPU UUID
func GetGPUDevice(ctx context.Context, podName string, namespace string) (string, error) {
// 读取 GPU 目录
deviceSubDirs, err := os.ReadDir(gpusDir)
if err != nil {
return "", err
}
// 遍历每个 GPU 子目录
for _, subDir := range deviceSubDirs {
infoFilePath := filepath.Join(gpusDir, subDir.Name(), "information")
data, err := os.ReadFile(infoFilePath)
if err != nil {
continue
}
content := string(data)
lines := strings.Split(content, "\n")
for _, line := range lines {
if strings.Contains(line, "GPU UUID") {
words := strings.Fields(line)
return words[len(words)-1], nil // 返回最后一个字段即为 GPU UUID
}
}
}
return "", fmt.Errorf("failed to find GPU UUID")
}
2 信息回传
设备信息上报容器将获取到的 GPU 设备 UUID 写入 Reservation Pod 的 Annotations 中。
// cmd/resourcereservation/app/app.go
func Run(ctx context.Context) error {
// ...(省略前置逻辑)
// 获取当前 Pod 的 namespace 与 name
namespace, name, err := poddetails.CurrentPodDetails()
if err != nil {
return err
}
// 初始化 Pod 注解补丁器
patch := patcher.NewPodPatcher(kubeClient, namespace, name)
// 若尚未打过补丁
if !patched {
var gpuDevice string
gpuDevice, err = discovery.GetGPUDevice(ctx, namespace, name)
if err != nil {
return err
}
logger.Info("Found GPU device", "deviceId", gpuDevice)
// 将发现的 GPU UUID 写入 Pod 注解
err = patch.PatchDeviceInfo(ctx, gpuDevice)
if err != nil {
return err
}
logger.Info("Pod was updated with GPU device UUID")
}
// ...(省略后续逻辑)
return nil
}
值得注意的是,虽然相关变量名和注解名中包含"index"字样,但实际存储的是完整的 GPU UUID:
// pkg/resourcereservation/patcher/pod_patcher.go
const (
reservedGpuIndexAnnotation = "run.ai/reserve_for_gpu_index"
)
// PatchDeviceInfo 将发现的 GPU UUID 写入当前 Pod 的注解
func (pp *PodPatcher) PatchDeviceInfo(ctx context.Context, uuid string) error {
// 获取当前 Pod 的完整信息(已省略错误处理)
pod, err := pp.kubeClient.CoreV1().Pods(pp.namespace).Get(ctx, pp.podName, metav1.GetOptions{})
if err != nil {
return err
}
// 初始化注解 map(若为空)
if pod.Annotations == nil {
pod.Annotations = make(map[string]string)
}
// 写入 GPU 设备 UUID
pod.Annotations[reservedGpuIndexAnnotation] = uuid
// 更新 Pod
_, err = pp.kubeClient.CoreV1().Pods(pp.namespace).Update(ctx, pod, metav1.UpdateOptions{})
return err
}
3 Watch 机制
KAI-Scheduler 通过 Kubernetes Watch API 监控 Reservation Pod 的变化,一旦发现 GPU 设备 UUID 的注解出现,就获取该信息并更新内部状态。
// pkg/binder/binding/resourcereservation/resource_reservation.go
// waitForGPUReservationPodAllocation 监听 GPU 预留 Pod,直到其注解中写入 GPU UUID。
func (rsc *service) waitForGPUReservationPodAllocation(
ctx context.Context,
nodeName,
gpuReservationPodName string,
) string {
// 构造 List-Watch 对象
watcher, err := rsc.kubeClient.Watch(
ctx,
&v1.PodList{},
client.InNamespace(namespace),
client.MatchingFields{"metadata.name": gpuReservationPodName},
)
if err != nil {
// 错误处理(省略)
return unknownGpuIndicator
}
defer watcher.Stop()
timeout := time.After(rsc.allocationTimeout)
for {
select {
case <-timeout:
// 超时处理:返回未知 GPU 标识
return unknownGpuIndicator
case event := <-watcher.ResultChan():
pod := event.Object.(*v1.Pod)
if pod.Annotations[gpuIndexAnnotationName] != "" {
// 成功拿到 GPU UUID
return pod.Annotations[gpuIndexAnnotationName]
}
}
}
}
4 用户 Pod 绑定
获取 GPU UUID 后,KAI-Scheduler 会:
-
更新内部状态:记录 GPU 的使用情况
-
绑定用户 Pod:将用户 Pod 与 Reservation Pod 关联,让它们共享同一个 GPU
-
设置环境变量:确保用户 Pod 能够访问正确的 GPU 设备
// pkg/binder/binding/binder.go
func (b *Binder) Bind(
ctx context.Context,
pod *v1.Pod,
node *v1.Node,
bindRequest *v1alpha2.BindRequest,
) error {
// 1. 区分是否为 GPU 共享场景
var reservedGPUIds []string
var err error
if common.IsSharedGPUAllocation(bindRequest) {
// 1.1 通过 ResourceReservation 机制提前锁定 GPU
reservedGPUIds, err = b.reserveGPUs(ctx, pod, bindRequest)
if err != nil {
return fmt.Errorf("failed to reserve GPUs: %w", err)
}
}
// 2. 构造标准的 Kubernetes Binding 对象
binding := &v1.Binding{
ObjectMeta: metav1.ObjectMeta{
Namespace: pod.Namespace,
Name: pod.Name,
UID: pod.UID,
},
Target: v1.ObjectReference{
Kind: "Node",
Name: node.Name,
},
}
// 3. 调用 API Server 完成绑定
if err := b.kubeClient.CoreV1().Pods(pod.Namespace).Bind(ctx, binding, metav1.CreateOptions{}); err != nil {
return fmt.Errorf("failed to bind pod %s/%s to node %s: %w", pod.Namespace, pod.Name, node.Name, err)
}
// 4. 可选:把预留的 GPU UUID 写回 Pod 注解或做其他后处理
if len(reservedGPUIds) > 0 {
// ...(省略)
}
return nil
}
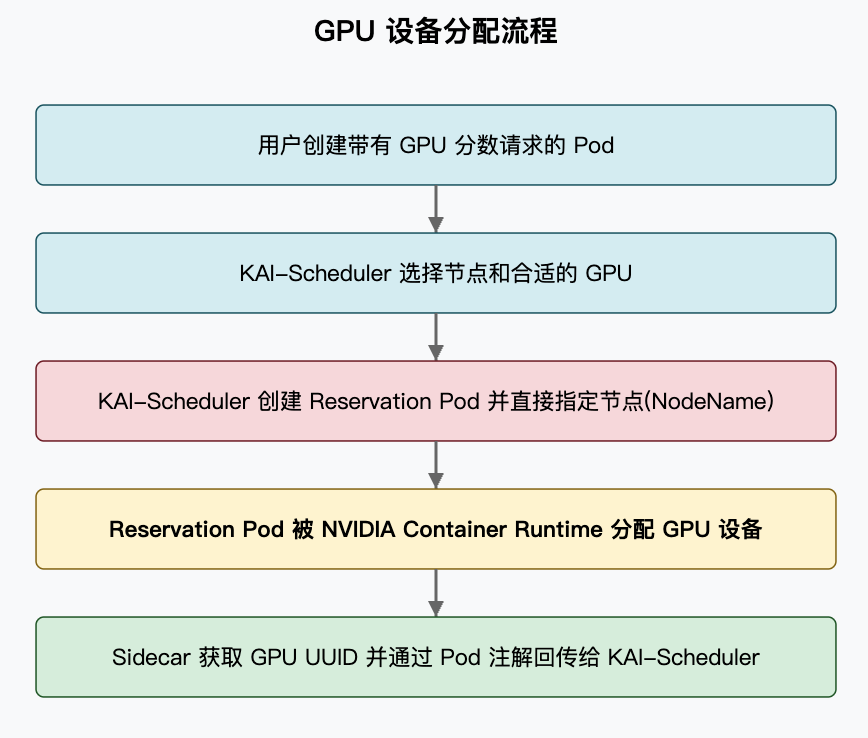
二、完整信息流:从调度到设备识别
(1)KAI-Scheduler 为用户 Pod 选择合适的节点和 GPU
用户请求分数 GPU 时,KAI-Scheduler 执行调度决策,并选择合适的节点运行该 Pod。
(2)KAI-Scheduler 创建 Reservation Pod 并指定节点
KAI-Scheduler 创建一个请求整个 GPU 资源的 Reservation Pod,并直接指定节点(设置 NodeName):
apiVersion: v1
kind: Pod
metadata:
name: runai-reservation-gpu-node-1-abc45
namespace: runai-reservation
labels:
app: runai-reservation
runai-gpu-group: gpu-group-xyz # GPU 组标识符
app.runai.resource.reservation: runai-reservation-gpu
annotations:
karpenter.sh/do-not-disrupt: "true"
spec:
nodeName: node-1 # 直接绑定到指定节点
serviceAccountName: runai-reservation
containers:
- name: runai-reservation
image: <resource-reservation-pod-image> # 实际镜像由配置决定
imagePullPolicy: IfNotPresent
resources:
limits:
nvidia.com/gpu: 1
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
(3)Device Plugin 告知 kubelet 节点上有可用 GPU 资源并参与资源分配决策
NVIDIA Device Plugin 识别节点上的 GPU 设备并报告给 Kubernetes。
(4)Pod 被直接调度到特定节点,NVIDIA Container Runtime 根据 Device Plugin 的分配结果,将特定的物理 GPU 设备挂载到容器中
设备挂载体现为环境变量和设备文件:
环境变量:NVIDIA_VISIBLE_DEVICES=GPU-UUID 或设备索引设备文件:/dev/nvidia0
(5)Reservation Pod 中的设备信息上报容器启动,它读取 NVIDIA 驱动提供的设备信息,识别出自己被分配的是哪个 GPU 设备的 UUID
如前面代码示例,设备信息上报容器通过读取 /proc/driver/nvidia/gpus/ 目录下的信息文件获取 GPU UUID。
(6)设备信息上报容器将此 UUID 写入 Pod 注解
更新 Pod 的注解:
metadata:
annotations:
# 存储完整的 GPU UUID,用于资源预留
run.ai/reserve_for_gpu_index: "GPU-UUID"
(7)KAI-Scheduler 的 Watch 机制检测到注解更新,获取 GPU 设备 UUID
Watch 机制捕获 Pod 更新事件,提取 GPU UUID 信息。
(8)KAI-Scheduler 更新内部 GpuSharingNodeInfo,记录该物理 GPU 的使用情况
// 更新内部状态示例
requestedMemory := nodeInfo.GetResourceGpuMemory(task.ResReq)
// 累加已使用的显存
nodeInfo.UsedSharedGPUsMemory[gpuGroup] += requestedMemory
// 累加已分配的显存(可能尚未真正使用)
nodeInfo.AllocatedSharedGPUsMemory[gpuGroup] += requestedMemory
(9)KAI-Scheduler 将用户 Pod 绑定到同一节点并配置 GPU 访问
确保用户 Pod 使用正确的 GPU 设备,通过环境变量和标签建立关联。
三、总结:优雅的异步信息同步
通过这种设计,KAI-Scheduler 巧妙地解决了 Kubernetes 架构中调度决策与设备分配之间的异步性问题:
-
尊重职责分离:保持与 Kubernetes 各组件职责边界的兼容
-
桥接信息鸿沟:通过一个专门的设备信息上报程序传递关键设备信息
-
异步信息同步:用 Watch 机制优雅地处理异步事件流
这一机制确保了即使在 GPU 资源分配由开头提到的三大组件共同完成的情况下,KAI-Scheduler 仍能精确追踪每个物理 GPU 的使用情况,为 AI 工作负载提供高效的分数 GPU 共享能力。
再次感谢那位提出问题的读者,正是这样的深入探讨推动了我们对技术细节的理解!希望这篇补充能清晰地解答你的疑惑。
感谢阅读!如果你觉得这篇文章对你有帮助,欢迎点赞、推荐、分享给更多朋友!
HAMi,全称是 Heterogeneous AI Computing Virtualization Middleware(异构算力虚拟化中间件),是一套为管理 k8s 集群中的异构 AI 计算设备而设计的“一站式”架构,能够提供异构 AI 设备共享能力,提供任务间的资源隔离。HAMi 致力于提升 k8s 集群中异构计算设备的利用率,为不同类型的异构设备提供统一的复用接口。HAMi 当前是 CNCF Sandbox 项目,已被 CNCF 纳入 CNAI 类别技术全景图。