Saving ¥200K/Month for a 2,000-Developer Team: Sangfor AI Computing Gateway and Production-Grade vGPU Scheduling
Key Highlights
- Intelligent routing engine reduced monthly external model invocation costs for a 2,000-developer team from ¥400K to ¥200K (50% cost reduction)
- vGPU fine-grained partitioning at 1%/256MB granularity, single-card model capacity increased 8x+, resource utilization improved 3x+
- Cloud-on-cloud elastic scheduling, fault interruption time reduced from 1 hour to under 10 minutes
- Volcano + HAMi four major scheduling control plane optimizations, covering gang/LWS full scenarios
The "Focus on Efficiency, Not Raw Power | HAMi Community Meetup" Shenzhen edition, initiated by the HAMi community and hosted by Dynamia AI, was successfully held on April 25, 2026 in Shenzhen. This article is the sixth installment of the HAMi Community Meetup Shenzhen recap series. Sangfor Cloud AI Chief Architect Jia Haojie shared a complete enterprise AI computing governance practice — from the computing challenges of the Agent era to intelligent routing and safety guardrails of the AI Computing Gateway, to Volcano + HAMi production-grade vGPU scheduling.

Speaker: Jia Haojie (Sangfor Cloud AI Chief Architect)
Video Replay & Slide Download
- Bilibili: Sangfor AI Computing Gateway: Computing Optimization and Model Governance Practice - Jia Haojie
- Download Slides: ai-computing-gateway-sangfor-jiahaojie.pdf
The Agent-Era Computing Storm: Four Core Challenges
Agent applications are developing rapidly, and AI computing consumption is growing exponentially. IDC predicts that token consumption in 2030 will grow more than 600x compared to 2025. Enterprises must find systematic solutions across four dimensions: cost, security, reliability, and control.
Computing Consumption Explosion
Agent applications are reshaping the landscape of AI computing demand. OpenClaw went viral globally, becoming the #1 GitHub repository by star count within 3 months; Kimi's subscription revenue in the first 20 days of 2026 exceeded the entire year of 2025. Open AI-Agent applications automatically "think" and "execute" in the background, bringing uncontrollable burst traffic and causing exponential growth in computing consumption.
Cost Spiral
Better results come with exponentially soaring costs. Popular AI scenarios like AI Coding and digital employees typically use the best-performing models — either with extremely high token invocation costs (starting at ¥10K/person/month) or extremely high local GPU costs (starting at ¥X0K/person). Every department says GPU/Tokens are insufficient, but management has no clear visibility into whether they're truly being used for valuable AI scenarios.
High Security Risks
Applications running "bare" is a common phenomenon: uncontrolled privacy data, lax permission management, and enterprise core data assets face theft risks. Agent plaintext transmission leads to data leaks, and customer data may be used to train models when using public MaaS services, further causing data breaches.
Poor Computing Supply Reliability
Single computing providers and model services create high single-point failure risks; multiple computing providers have inconsistent performance and fluctuations, leading to business instability; dedicated computing capacity struggles to support burst traffic, affecting business stability and user experience.
AI Computing Gateway: The Enterprise's Own "Computing Scheduling & Optimization Center"
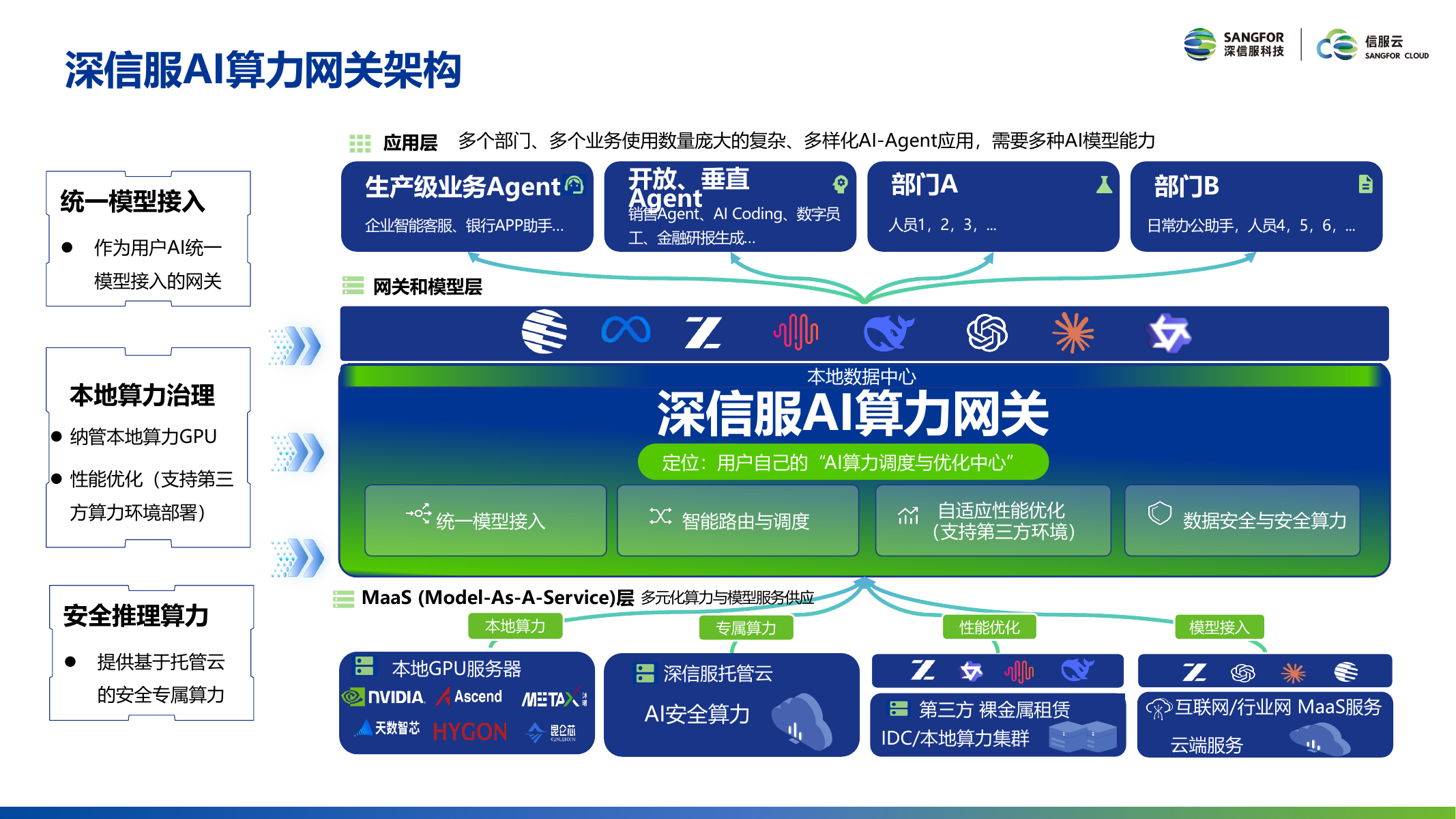
Sangfor AI Computing Gateway is positioned as the enterprise's unified AI model access layer, interfacing upward with various Agent applications and downward aggregating diversified computing and model services, achieving three major goals: unified model service access, global computing usage visibility, and intelligent routing cost optimization.
Five-Layer Architecture Overview
The AI Computing Gateway adopts a layered architecture design:
| Layer | Core Capability | Description |
|---|---|---|
| Application Layer | Open/Vertical Agents, Production Business Agents | Sales Agent, AI Coding, Digital Employee, Intelligent Customer Service, etc. |
| Gateway Layer | Unified Access, Intelligent Routing, Adaptive Optimization, Safety Guardrails | AI Computing Gateway core, providing comprehensive governance capabilities |
| MaaS Layer | Diversified Model Service Aggregation | Unified management of model service access and distribution |
| Cloud Services | Public Cloud Tokens (pay-per-invocation) | OpenAI, Anthropic, Kimi, DeepSeek, Qwen, GLM, etc. |
| Local Computing | GPU Servers + Managed Cloud Dedicated Computing | Self-built computing centers, carrier computing centers, bare metal rental |
Global Visibility and Precise Control
The gateway achieves unified distribution and management of global model services, with global usage visible by department, route, model, and API-Key. Monitoring dimensions cover: invocation provider, input/output tokens and content, cost, API type, throughput, first-token latency, end-to-end latency, and other comprehensive metrics.
Precise rate limiting and quota control based on request frequency, input/output tokens, concurrent connections, and access restrictions, with permissions refined to organizations and departments via API Keys, ensuring precise computing control for each department.
Intelligent Routing Engine: Making Every Computing Dollar Count
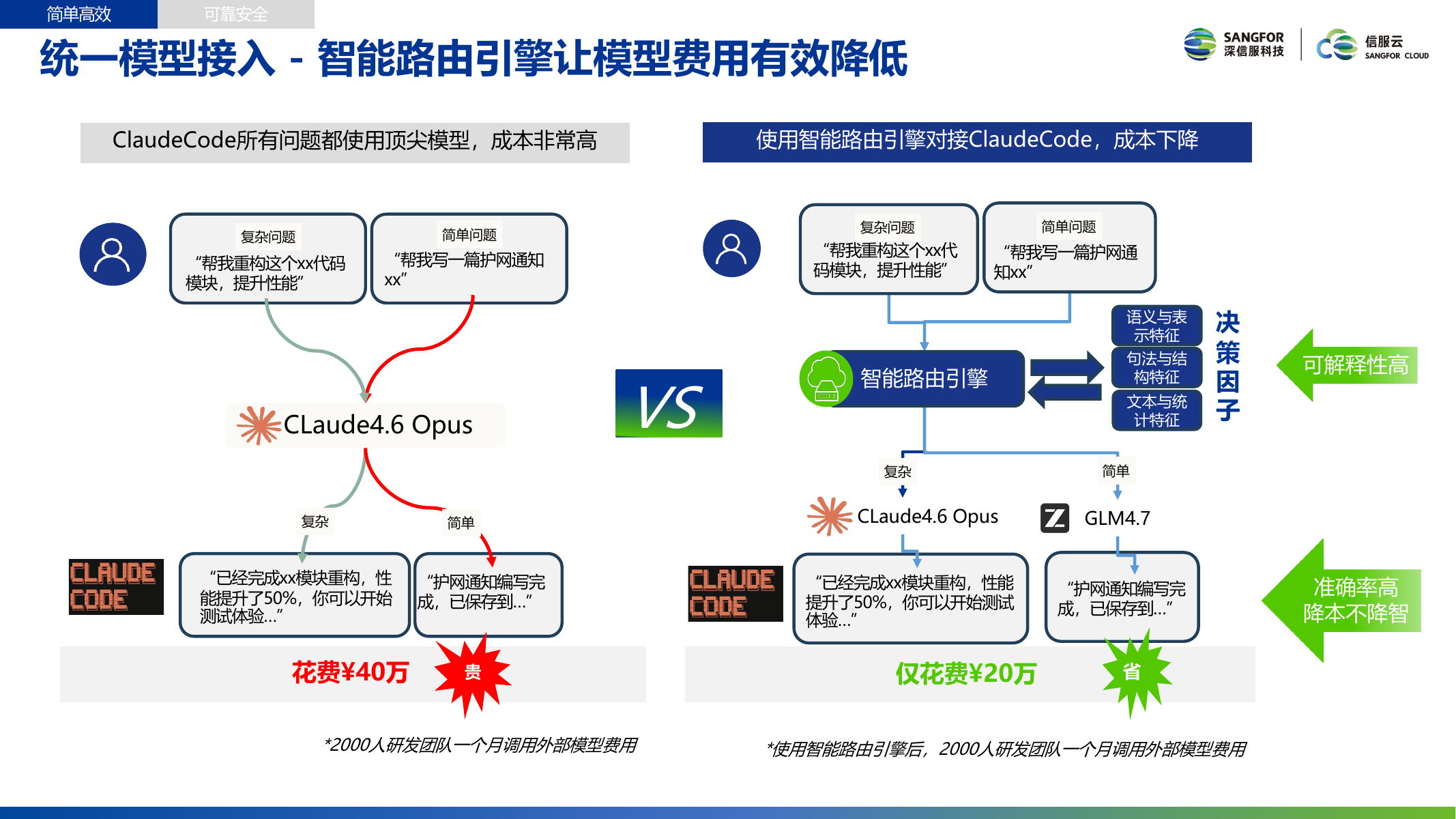
Real-World Result: Using the intelligent routing engine with Claude Code, a 2,000-developer team's monthly external model invocation costs dropped from ¥400K to ¥200K, a 50% cost reduction while maintaining service quality.
Core Problem
Take Claude Code as an example — all questions use the top-tier Claude 4.6 Opus model, which is very expensive. In reality, user requests contain a large number of simple questions (like "help me write a security notification") that could easily be handled by lower-cost models. Only complex questions (like "help me refactor this code module to improve performance") truly require top-tier models.
Intelligent Routing Engine Principles
The intelligent routing engine performs decision-based traffic splitting through multi-dimensional feature analysis:
| Feature Dimension | Description |
|---|---|
| Semantic & Representational Features | Analyzes the semantic complexity and expressive intent of requests |
| Syntactic & Structural Features | Evaluates code logic, reasoning chain structural complexity |
| Text & Statistical Features | Assists judgment based on text length, keywords, and other statistical information |
The decision factor synthesizes the above three feature types to output a "complex" or "simple" label, routing to the corresponding model. This engine supports configurable semantic routing and regular routing aggregation, flexible configuration based on business needs — not all requests need to go through semantic analysis.
Routing Results
| Metric | Before Optimization | After Optimization |
|---|---|---|
| Monthly Model Invocation Cost | ¥400K | ¥200K |
| Model Selection | All using Claude Opus | Complex→Claude Opus, Simple→GLM etc. |
| Service Quality | High | High (cost reduction without quality loss) |
| Routing Accuracy | — | High, strong explainability |
Simple questions typically account for 60%-80%, meaning most requests can be handled by lower-cost models, achieving significant cost optimization.
Safety Guardrails: Protecting AI with AI
Sangfor proposes a "Protecting AI with AI" security strategy, building a three-layer defense system including LLM safety guardrails (pre-guardrails + post-guardrails), zero-trust systems, and a risk governance platform.
Pre-Guardrails (Before Request)
Intercepting and inspecting requests before they reach the LLM:
- Sensitive Word Filtering: Intercepts requests containing sensitive information
- Prompt Injection Defense: Detects and blocks prompt injection attacks
- Compliance Checking: Ensures request content meets enterprise security policies
Post-Guardrails (After Response)
Filtering and inspecting results after the LLM returns them:
- Content Safety Detection: Checks whether output contains illegal or harmful information
- Sensitive Data Filtering: Prevents model output from leaking personal sensitive information
- Format Validation: Ensures output conforms to expected formats
Security Architecture Features
- Core capabilities are built on top of LLMs, adopting a professional domain-specific model + large-small model combination architecture
- Optimized inference algorithms for security detection with strong performance and good results
- Built-in safety guardrails, one-click activation, on-demand protection scope selection
- Invocation logs integrated with alerts, risk assessment and handling assisted by Agents
Model Aggregation Routing: High-Availability Computing Supply
To avoid single-point failures from multiple model sources, Sangfor implemented model aggregation routing capabilities, ensuring smooth and stable service with elastic cloud-on-cloud model switching, improving AI business robustness.
| Strategy | Description |
|---|---|
| Cross-Resource-Pool Round-Robin Scheduling | Configures round-robin scheduling across local resource pools and model providers, avoiding single-point model service overload during peak periods |
| Cloud-On-Cloud Priority Strategy | Prioritizes private computing, automatically diverting to cloud models when load thresholds are reached, alleviating peak pressure |
Real-World Results:
- Single-point failure risk significantly reduced, business interruption time during main model failures from 1 hour to under 10 minutes
- Under 3x peak traffic stress testing, using cloud-on-cloud elastic strategy, model invocation success rate maintained at 95%+
Local Computing Governance: Fine-Grained vGPU Operations
Smart Fusion Architecture (SFA)
Sangfor introduced the Smart Fusion Architecture (SFA), shielding the complexity of multi-card, multi-model environments. Core components include:
- Adaptive Hardware Abstraction Layer (Smart HAS): Shields underlying GPU heterogeneous differences, enabling unified scheduling management
- vGPU Partitioning: Supports 1%, 256MB-level memory resource fine-grained partitioning
- Model Repository + API Key Management: Multi-KEY fine-grained operations, efficient model service sharing
vGPU Partitioning Results
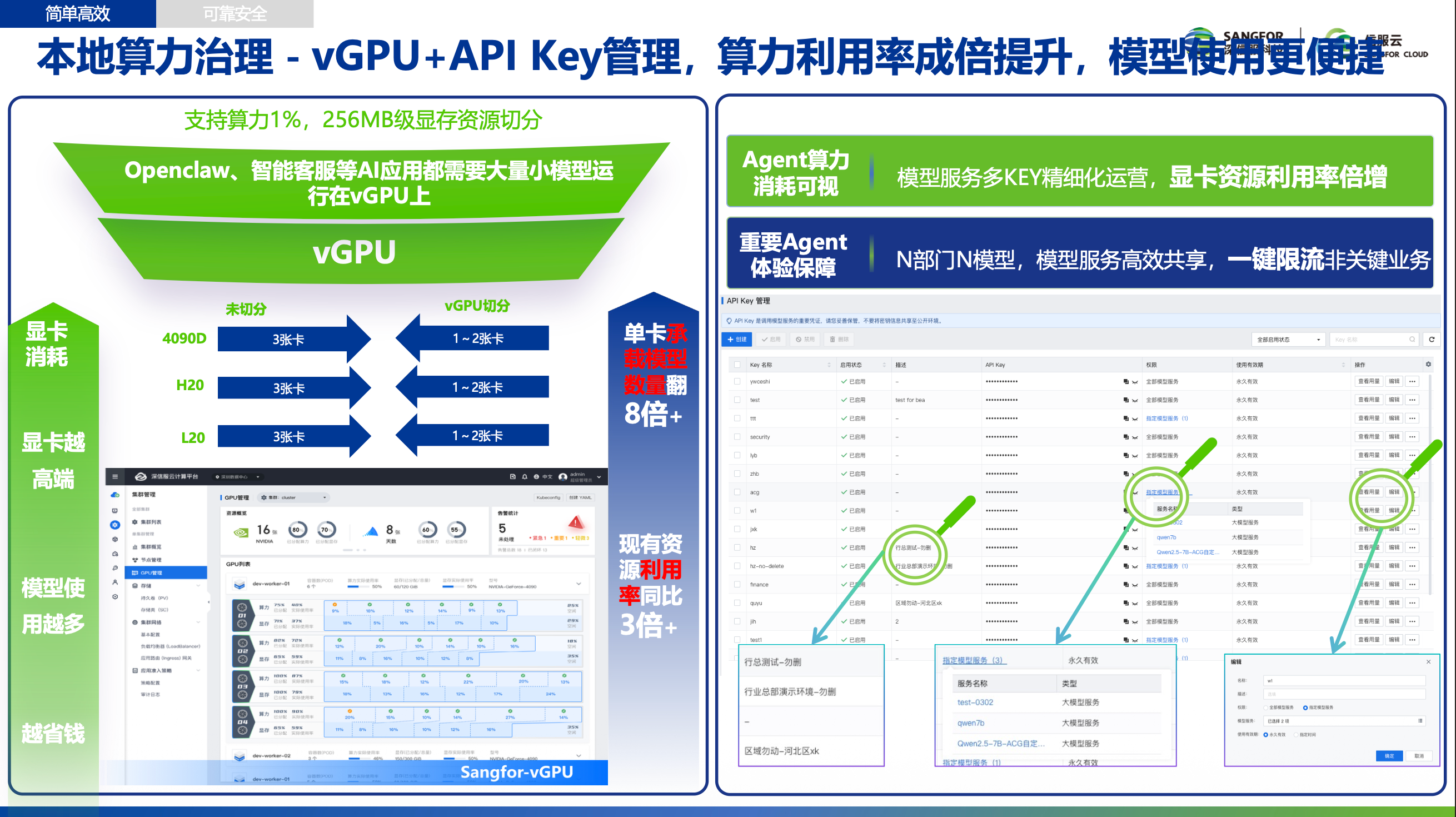
| GPU Model | Without Partitioning | After vGPU Partitioning | Savings |
|---|---|---|---|
| 4090D | 3 cards | 1~2 cards | Saves 1~2 cards |
| H20 | 3 cards | 1~2 cards | Saves 1~2 cards |
| L20 | 3 cards | 1~2 cards | Saves 1~2 cards |
Core Benefits:
- Single-card model capacity increased 8x+
- Existing resource utilization improved 3x+
- N departments, N models, efficient model service sharing, one-click rate limiting for non-critical business
- Important Agent experience guaranteed, more model usage means more cost savings
Adaptive Inference Engine
For heavy-load Agent application deployment, Sangfor built the adaptive inference architecture Smart Arc, including:
- Adaptive Multi-Version Inference Engine: Automatically selects the optimal inference engine version
- One-Click Best Practice Configuration: Auto-tuning based on business scenarios
- Multiple Performance Optimization Atomic Capabilities: Retrieval-based speculative decoding optimization, scenario-based chunked scheduling optimization, inter-GPU/inter-node data transfer optimization, long-input performance optimization, scenario-based semantic-aware Cache intelligent load balancing, etc.
- Dedicated computing ROI improved 2~5x, already deployed across multiple industries including finance, healthcare, government, AI Coding, and sales Agents
Volcano + HAMi: Four Optimizations for Production-Grade vGPU Scheduling

The overall vGPU scheduling approach: Workload Request → Volcano Scheduling Control Plane → HAMi vGPU Device Capability Foundation. Volcano handles job orchestration (batch/gang/LWS), while HAMi handles device sharing and fine-grained partitioning. When shared GPUs enter gang and LWS scenarios, the control plane must simultaneously manage both device-side management and job-side scheduling.
Community Co-Building
Sangfor's practice is not just a single vendor's computing platform optimization case; it also reflects the evolutionary direction of open-source vGPU scheduling capabilities in production environments: combining device sharing, fine-grained resource isolation, heterogeneous device adaptation, and Kubernetes scheduling semantics into reusable infrastructure capabilities.
| Community Focus Area | HAMi-Provided Foundation | Validation Value in Enterprise Practice |
|---|---|---|
| Open Standardization | Carries vGPU semantics through Kubernetes-native resource declarations and scheduling extensions | Avoids binding capabilities to a single platform implementation, reducing migration and integration costs |
| Heterogeneous Device Support | Continuously expanding around NVIDIA, Ascend, Cambricon, Hygon, Metax, and other device types | Enables enterprises to maintain a unified scheduling entry when multi-vendor, multi-generation computing coexists |
| Production-Grade Operability | Improves stability through device state maintenance, resource quotas, monitoring metrics, and scheduling lifecycle coordination | Advances from "can partition GPUs" to "can stably operate shared GPU pools long-term" |
Sangfor's case is a landing sample of HAMi community capabilities in enterprise-grade AI infrastructure: the enterprise side contributed complex scenarios and engineering feedback, while the community side deposits general capabilities, interface semantics, and reusable implementations, jointly advancing vGPU scheduling from functionally usable to production-ready.

Platform Selection: Job-Level Scheduling as the Upper Constraint for Shared GPU Deployment
| Scenario | Scheduling Unit | Scheduling Focus | Key Semantics |
|---|---|---|---|
| Single Pod | Individual Pod | How to partition one card | — |
| Gang jobs | Group of tasks | Members ready simultaneously | PodGroup / queue / topology |
| LWS | leader / worker group | Cross-node inference scheduling and lifecycle | group start / place / lifecycle |
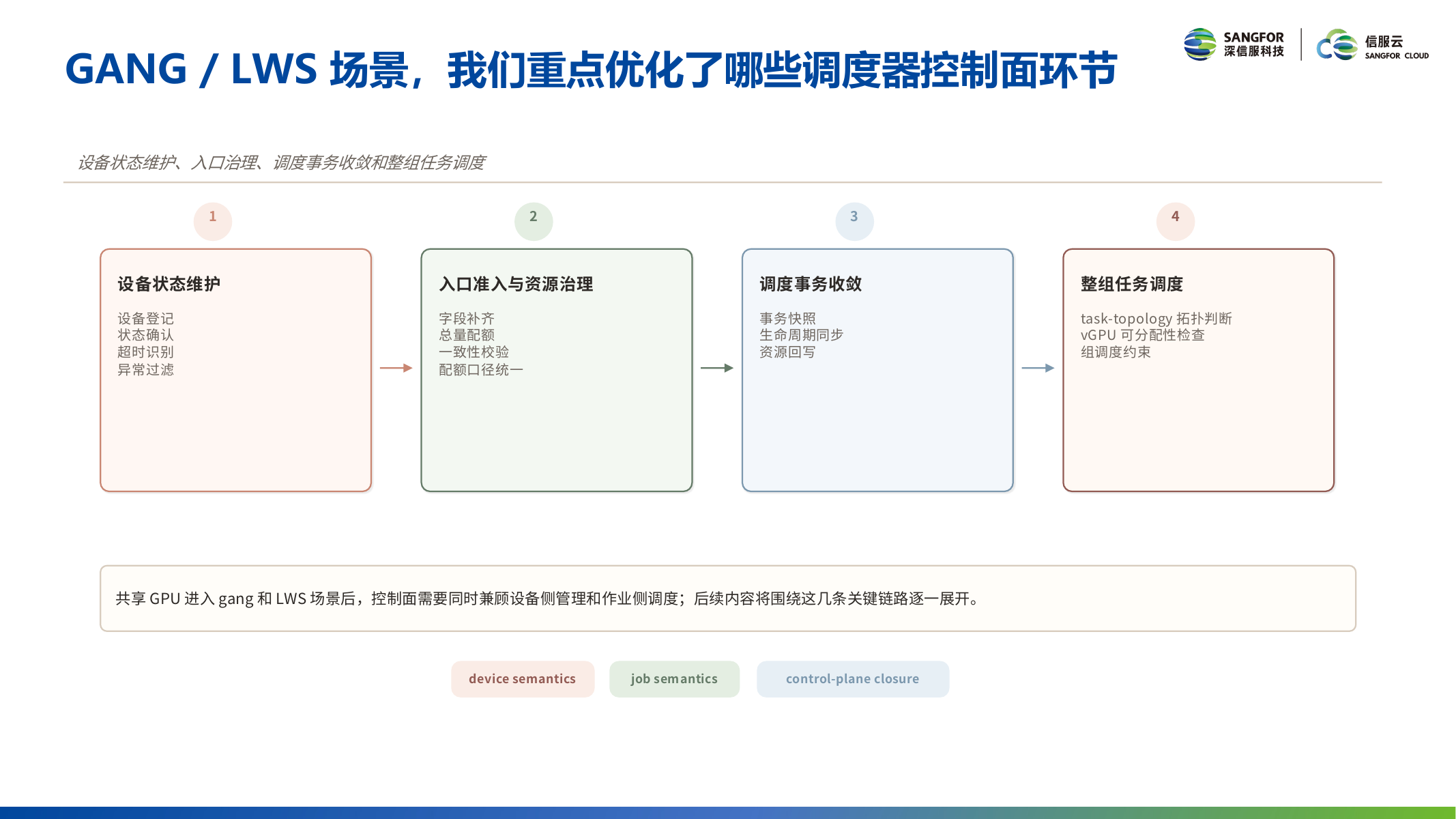
Device State Maintenance: From One-Time Snapshot to Continuous Maintenance
Problem: In the old mode, nodes report device status once, and the scheduler reads passively. Expired handshakes, abnormal devices, and residual metrics remain in the system. The control plane only sees state at the read moment, lacking continuous maintenance actions afterward.
Solution: The maintenance pipeline connects device status to periodic checks and result convergence, including:
- Handshake Timeout Handling: Handshake timeouts enter expiration processing
- Health Check Filtering: Failed cards are removed from the schedulable view
- Monitoring Data Cleanup: Cleans up metric residuals inconsistent with node status
Admission Control & Resource Governance: Unified Shared GPU Resource Semantics
Problem: Incomplete resource declaration fields still enter the scheduling pipeline, and the resource dimensions used by quota and scheduling are inconsistent.
Solution: Complete resource field patching, derived totals, and consistency validation at the entry webhook layer:
- The system automatically patches missing fields (e.g., vgpu-number defaults to 1), generating corresponding derived totals (vgpu-total-memory, vgpu-total-cores) for quota calculation
- Quota governance and scheduling decisions share unified resource dimensions; incomplete resource declarations are rejected outright
- Resource declarations can bind to specific GPUs via UUID pre-selection
Scheduling Transaction Convergence: Isolating Pre-Allocation Computation from Lifecycle Synchronization
Problem: In the old mode, scheduling trial computation and real occupancy share the same state, with pre-allocation computation and runtime phases affecting each other.
Solution: Scheduling trial computation and real occupancy are organized in layers:
- Isolated Pre-Allocation Computation: Creates snapshots based on baseline state, completing node selection and resource allocation computation on the snapshot without polluting real state
- Lifecycle Synchronization: Resource changes occurring during allocation, binding, and release phases are continuously synchronized back to the baseline state, gradually converging both to a unified resource view
Whole-Group Task Placement: Joint Topology and vGPU Allocatability Assessment
Problem: Meeting conventional resource conditions doesn't guarantee that the entire group of tasks can be successfully allocated under the current device layout. For example, a node may have sufficient CPU/memory but, limited by GPU exclusivity, cannot fit the entire group of tasks.
Solution: The judgment unit shifts from individual Pods to entire task groups, with task-multi-dimen multi-dimensional assessment jointly filtering nodes with vGPU allocatability, completing computation within the same scheduling decision round.
Selected Q&A from the Audience
Q1: Does the intelligent routing's semantic judgment apply globally?
This feature is configurable, supporting semantic routing and regular routing aggregation. Not all requests need to go through semantic analysis; it can be flexibly configured based on business needs.
Q2: How much latency does intelligent routing introduce?
The target latency requirement is under 50ms, and optimization is ongoing. Latency mainly comes from the semantic analysis stage, and the choice of underlying technology approach (small model classification or rule engine) affects latency performance.
Q3: Does the inference scenario require topology awareness?
Currently, no dedicated topology awareness optimization has been made for LWS (Leader-Worker) cross-machine deployment. Training scenarios have a strong need for this, but inference scenarios have relatively lower priority due to smaller model and device scales. Currently only pre-studies have been done without production deployment.
Conclusion: Two Dimensions of AI Computing Governance
Sangfor's practice can be understood from three levels: upward governance, making LLM usage safe and cost-effective through intelligent routing and safety guardrails; downward optimization, making GPUs fully utilized and stable through Volcano + HAMi production-grade scheduling; outward contribution, transforming enterprise scenario experience in device sharing, resource isolation, and scheduling coordination into more general open-source capabilities through the HAMi community.
| Dimension | Core Capability | Key Results |
|---|---|---|
| Upward Governance | Intelligent Routing + Safety Guardrails + Model Aggregation | 50% cost reduction, fault recovery from 1h to 10min, AI security closed loop |
| Downward Optimization | Volcano + HAMi + vGPU Partitioning | 8x single-card capacity, 3x resource utilization, production-grade shared GPU pool scheduling |
| Open-Source Community Perspective | HAMi community's device sharing, heterogeneous device adaptation, resource isolation & scheduling extensions | Depositing complex enterprise scenario feedback into reusable, collaboratively evolving open-source infrastructure capabilities |
For enterprises facing AI computing cost spiral, security risks, and scheduling efficiency issues, this practice provides a full-stack reference from gateway governance to hardware scheduling. For the HAMi community, it also provides feedback from real production scenarios: shared GPUs should not stop at single-card partitioning but continue to evolve around heterogeneous devices, job-level scheduling, quota governance, observability, and lifecycle consistency. The core approach is worth learning from: enterprises bring complex scenarios to the community, and the community deposits general capabilities back into the ecosystem, ultimately making every computing dollar count and ensuring every GPU runs at full value.