Resolving Hami vGPU Scheduling Failures After Thousand-GPU Cluster Upgrade
This article is contributed by Fan Huiyang, a HAMi community developer. It documents the full troubleshooting and resolution process for a mid-to-large GPU cluster (200 nodes) where vGPU scheduling latency degraded from seconds to over ten minutes after upgrading from Volcano 1.7 to Volcano 1.12 + hami-dp. Starting from the node annotation mechanism and handshake protocol, the article traces the root cause chain (API Server throttling → Patch delay → Resource view timeout) and presents a fix that removes the handshake mechanism and optimizes annotation update strategies, verified through multiple rounds of testing.
Problem Description
After upgrading a cloud pool of 200 NVIDIA nodes from Volcano 1.7 + volcano-dp to Volcano 1.12 + hami-dp, scheduling test tasks requesting GPU resources became extremely slow, taking over ten minutes to successfully schedule, severely impacting business efficiency.
Background
Node Annotation Mechanism
In a Volcano + hami-dp environment, the hami-dp Pod scans GPU information on nodes and applies the following annotations:
volcano.sh/node-vgpu-handshake: Handshake annotation for state synchronization between hami-dp and the schedulervolcano.sh/node-vgpu-register: GPU resource registration annotation recording GPU details
Registration annotation format:
GPU-f571c8f8-948a-71b4-3be1-2bf02c7a1b20,10,32768,NVIDIA-Tesla V100S-PCIE-32GB,true,hami-core
| Field | Meaning |
|---|---|
GPU-xxx | GPU UUID |
10 | Number of gpu-number resources per physical GPU, limiting max 10 Pods per physical GPU |
32768 | GPU memory size (MB) |
NVIDIA-Tesla V100S-PCIE-32GB | GPU model |
true | Health status, true means healthy |
hami-core | Partitioning mode, hami-core or mig |
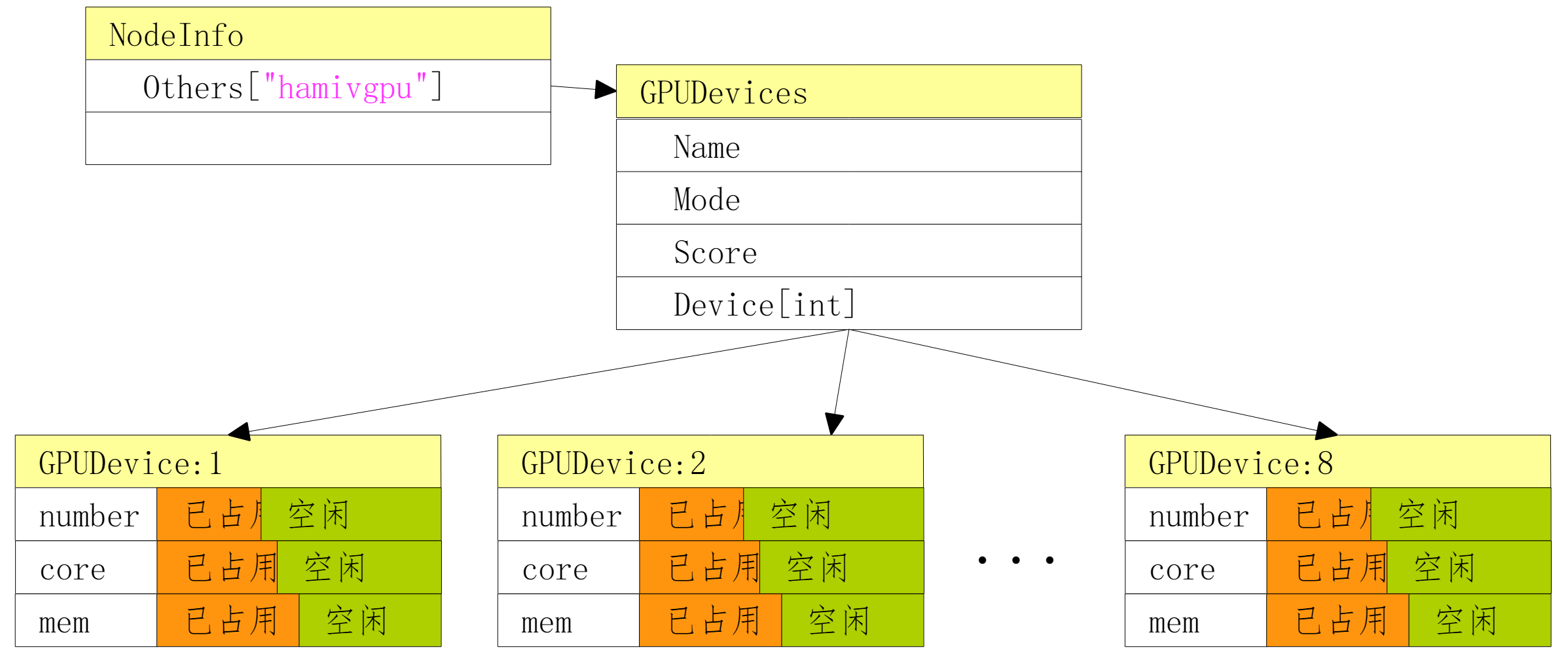
Resource View
Volcano-scheduler generates a hami vGPU resource view based on node annotations, recording the total resources across three dimensions: GPU count per node, gpu-number quantity per GPU, memory amount, and compute percentage.
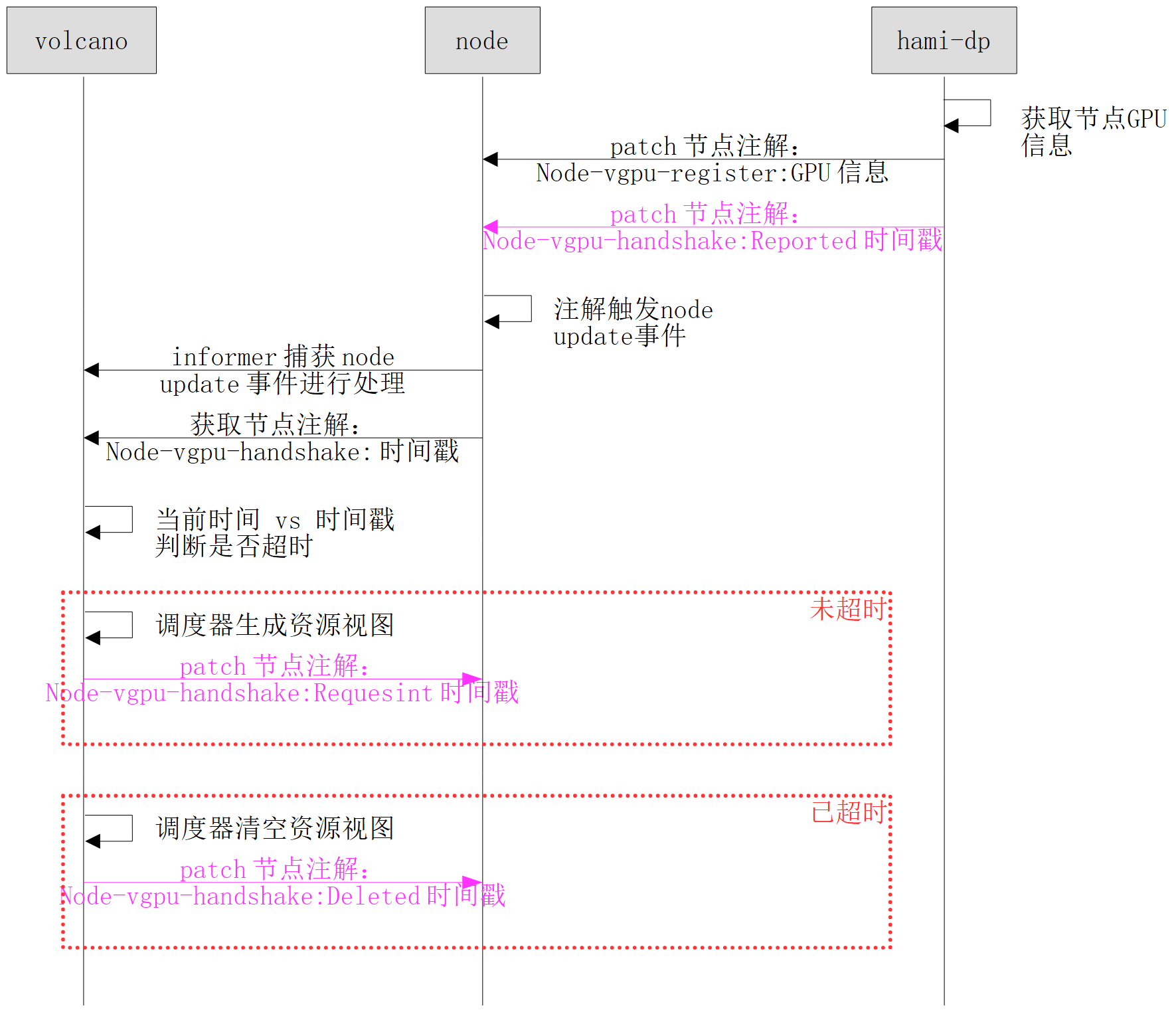
Handshake Mechanism
To ensure that the volcano-scheduler promptly detects GPU resource changes caused by GPU failures or hami-dp Pod hangs, hami-dp and volcano-scheduler implement a handshake mechanism via node annotations:
- hami-dp side: When updating the
node-vgpu-registerannotation, it also patches the handshake annotation and triggers a node update event - volcano-scheduler side: When processing node update events, it evaluates the timestamp in the handshake annotation
Handshake state transitions:
- If the annotation value is
Reported + timestamp, the scheduler changes it toRequesting + timestamp - If the annotation value is
Requesting + timestampand the elapsed time is less than 60s, generate a resource view - If the annotation value is
Requesting + timestampand the elapsed time exceeds 60s, clear the resource view and change the annotation toDeleted + timestamp - If the annotation value is
Deleted + timestamp, clear the resource view
Scheduler handshake code:
if strings.Contains(handshake, "Requesting") {
formertime, _ := time.Parse("2006.01.02 15:04:05", strings.Split(handshake, "_")[1])
if time.Now().After(formertime.Add(time.Second * 60)) {
klog.Infof("node %v device %s leave", node.Name, handshake)
tmppat := make(map[string]string)
tmppat[deviceconfig.VolcanoVGPUHandshake] = "Deleted_" + time.Now().Format("2006.01.02 15:04:05")
patchNodeAnnotations(node, tmppat)
return nil
}
} else if strings.Contains(handshake, "Deleted") {
return nil
} else {
tmppat := make(map[string]string)
tmppat[deviceconfig.VolcanoVGPUHandshake] = "Requesting_" + time.Now().Format("2006.01.02 15:04:05")
patchNodeAnnotations(node, tmppat)
}
Handshake frequency issue: hami-dp updates handshake annotations every 30s. With 200 NVIDIA nodes in the cluster, each dp pod patches node annotations, and the resulting node update events also trigger the scheduler to patch annotations. This means 400 patch node annotation operations every 30 seconds.
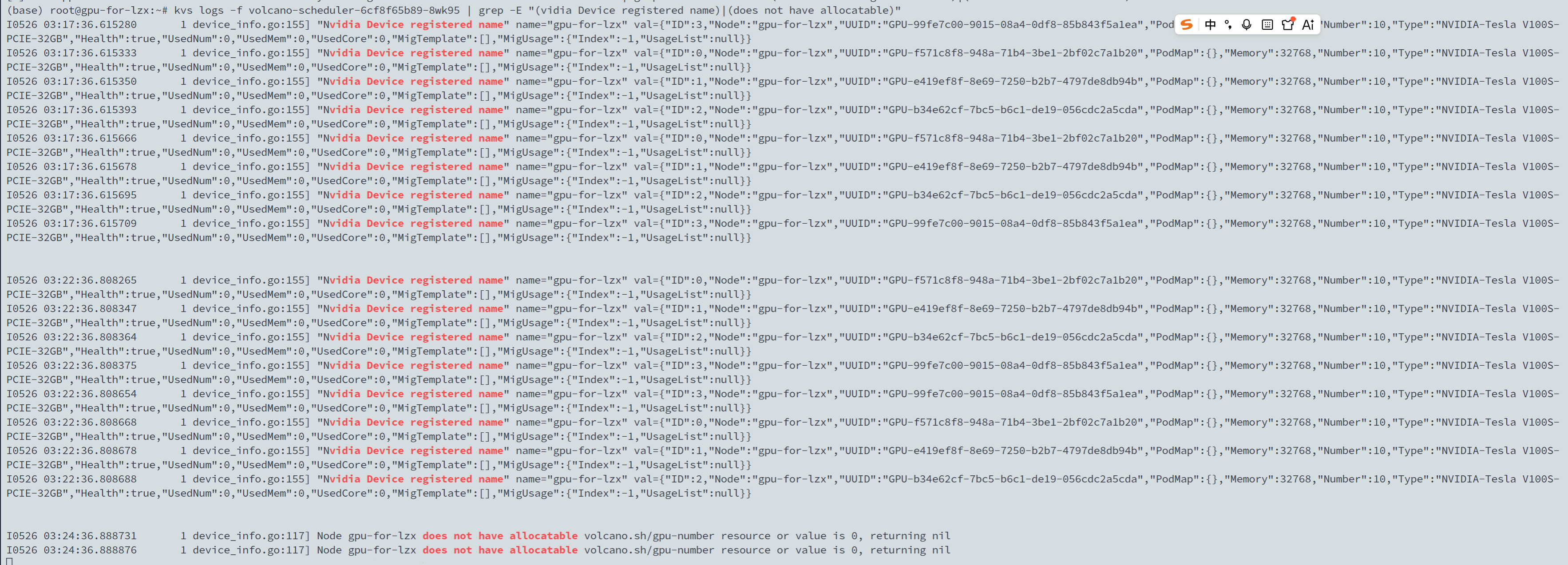
Root Cause Analysis
After investigation, the root cause chain is as follows:
- Excessive annotation operations: With many NVIDIA nodes in the cluster, each running a hami-dp Pod that periodically patches node annotations, the excessive patch operations triggered API Server throttling
- Patch delays: API Server throttling limited the scheduler's ability to patch nodes, with each patch delayed by approximately 200ms
- Resource view generation blocked: Patch delays blocked the generation of hami vGPU resource views
- View timeout and clearing: Since most nodes' GPU resources were nearly fully utilized, only a few nodes were available. These nodes' vGPU views had already timed out and were cleared, causing the current scheduling round to fail. Success only came after multiple rounds, so a test Pod required over ten minutes to be scheduled
Log evidence:
- A single scheduling cycle (Start to End scheduling) took 52 seconds, normally under 1s

- Within one scheduling cycle, patches were delayed 260 times, each nearly 200ms

- Within one scheduling cycle, multiple nodes' vGPU views had already timed out before generation
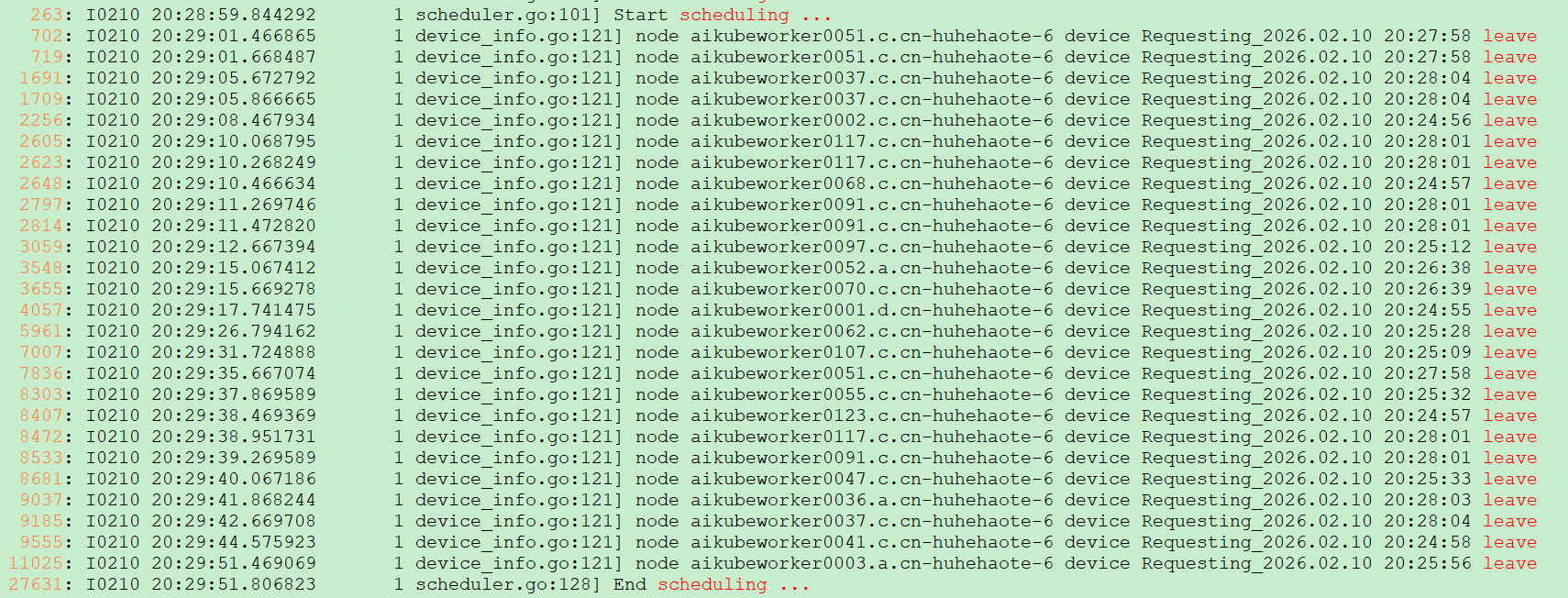
- Within one scheduling cycle, task scheduling only started after 50+ seconds

Solution
Core Approach
Remove the handshake mechanism between volcano-scheduler and hami-dp that operates through patching node annotations. Delete all code related to processing the volcano.sh/node-vgpu-handshake annotation in both the scheduler and hami-dp.
Specific Changes
hami-dp changes:
- Added annotation comparison: compare the real-time device annotation with the existing node annotation, only update the node annotation when they differ
Scheduler changes:
- Added
node.status.allocatablevGPU resource check: if no vGPU resources exist, clear the view directly (to handle the scenario where dp Pod hangs and annotations can't be updated); if resources exist, generate the vGPU resource view based on node annotations
Scheduler optimization:
- Removed the logic that triggers traversing all pods on a node for resource usage statistics on node update events. Reason: In the current code, update events like patching node annotations or labels — which have no effect on resource usage statistics — also trigger traversing all pods on the node for resource usage statistics. This is completely unnecessary and increases scheduling overhead.
GPU conflict fix:
- Delay binding of Pods on the same node requesting the same gpu-number quantity, to avoid Pod confusion caused by kubelet not passing Pod information when calling dp.
Note: The "compatibility with old GPU Pods started by Volcano 1.7" and "hami-vgpu preemption functionality (inter-queue and intra-queue preemption)" mentioned above are internally developed implementations not yet supported in the current community code. Contributing open source code requires company approval, and submission to the community is planned for the future. The solution is currently in the testing and verification stage internally.
Verification
1. Handshake Annotation No Longer Changes
After replacing the images, the handshake annotation on nodes retains the value patched by the previous dp and no longer changes:
volcano.sh/node-vgpu-handshake: Reported 2026-05-25 07:58:20.213111834 +0000 UTC
2. Simulating hami-dp Pod Hang
Result: After the dp Pod hung, starting a GPU Pod failed to schedule, as expected. After dp restarted, the scheduler detected the resource change and scheduling succeeded, as expected.

3. Inter-Queue Full-GPU Preemption Test
Test steps: Start 4 low-priority tasks occupying 4 GPUs, sequentially start high-priority tasks to preempt GPUs, then delete high-priority tasks to reclaim GPUs.
Result: All GPU UUIDs were unique. Preemption and reclaim behavior fully met expectations.
4. Inter-Queue vGPU Preemption Test
Scenario 1: vGPU preempts vGPU
- Start 4-replica low-priority task (4 GPUs per replica, 25% each), start high-priority task (4 GPUs, 60% each)
- High-priority task evicts 3 low-priority tasks; after deleting high-priority task, low-priority tasks resume
Scenario 2: pGPU preempts vGPU
- Start high-priority task requesting 4 full GPUs, all low-priority tasks evicted
- After deleting high-priority task, low-priority tasks resume
Scenario 3: vGPU preempts pGPU
- Start low-priority task (4 replicas, 1 full GPU each), start high-priority task (4 GPUs, 60% each)
- All low-priority tasks evicted; after deleting high-priority task, they resume
Result: All scenarios met expectations with no duplicate GPU UUIDs.
5. Intra-Queue vGPU Preemption Test
Test steps: Start low-priority task (non-gang scheduling), start high-priority task to preempt, reclaim after deleting high-priority task.
Result: Preemption and reclaim behavior met expectations.
6. Old volcano-dp Compatibility Test
Test steps:
- Use old dp to start Pods occupying 2 GPUs
- Switch to hami-dp, update scheduler configuration to use hami-dp resources
- Start 2 more Pods, verify no GPU conflicts
- Delete old Pods, restart using hami vGPU
Result: GPU UUIDs of both new and old Pods were unique, confirming good compatibility.
Conclusion
The root cause of this issue was the handshake mechanism between hami-dp and volcano-scheduler in a large-scale cluster generating excessive patch node annotation operations, causing API Server throttling that blocked vGPU resource view generation. By removing the handshake mechanism, optimizing annotation update strategies, and improving resource view validation logic, the scheduling delay issue was completely resolved. After multiple rounds of verification — including dp hang detection, full-GPU preemption, vGPU preemption, intra-queue preemption, and old dp compatibility — all functionality met expectations.