DRA Alone Isn't Enough: Why HAMi v2.9 Is Building an Ecosystem Alliance
"Maximize Efficiency, Not Compute" — the HAMi Community Meetup Shenzhen was hosted by the HAMi community and organized by Dynamia AI, concluding successfully on April 25, 2026. This is the second article in the HAMi Shenzhen Meetup recap series. HAMi Maintainer Li Mengxuan revealed v2.9 core features for the first time, provided an in-depth analysis of the DRA technology roadmap, and shared the community's vision for unified heterogeneous compute management.
Speaker: Li Mengxuan (Co-founder & CTO of Dynamia AI / HAMi Maintainer)

Key Highlights
- GPU sharing increases cluster utilization from 20% to 70%, more than doubling available resources
- v2.9 introduces kai-resource-isolator, moving from "capable of sharing" to "secure sharing"
- Ascend 910C user-space soft partitioning, achieving MIG-like virtualization without hardware isolation
- DRA's three major challenges — HAMi addresses them with a "lightweight" approach
- Memory expansion and contraction expected to be merged into the mainline in version 2.10
Video Recording & Slides
- Bilibili: HAMi DRA Ecosystem Alliance and v2.9 Preview - Li Mengxuan
- Download Slides: hami-v2.9-dra-ecosystem-limengxuan.pdf
1. HAMi's Core Mission: Making Every Compute Count
As a HAMi Maintainer, Li Mengxuan has a firsthand understanding of GPU resource waste. He opened with a straightforward question: how are GPUs allocated in Kubernetes? The answer is blunt — an entire GPU card is bound to a single Pod, and any unused portion cannot be shared with others. This exclusive allocation model, which he likened to a "communal pot," is particularly painful when AI compute resources are already in short supply.

As a CNCF Sandbox project, HAMi is fundamentally doing one thing: transforming GPUs from "exclusive" to "shared." Specifically, it delivers several key capabilities:
- Multi-task multiplexing: GPU virtualization enables a single physical card to serve multiple tasks simultaneously, breaking the exclusive model
- Utilization leap: Average cluster GPU utilization jumps from 20% to 70%, more than tripling available resources
- Heterogeneous unification: Whether the underlying hardware is NVIDIA, Ascend, or Cambricon, the upper layer provides unified scheduling and monitoring, abstracting away hardware differences
- Topology awareness: Automatically detects physical topology between cards (e.g., which cards are directly connected), optimizing communication efficiency for multi-card workloads
Together, these four capabilities form HAMi's core answer to heterogeneous compute management.
2. v2.9 Core Features
After covering the project's positioning, Li Mengxuan shifted to the upcoming HAMi 2.9 release, which brings significant improvements in ecosystem compatibility and domestic chip support.
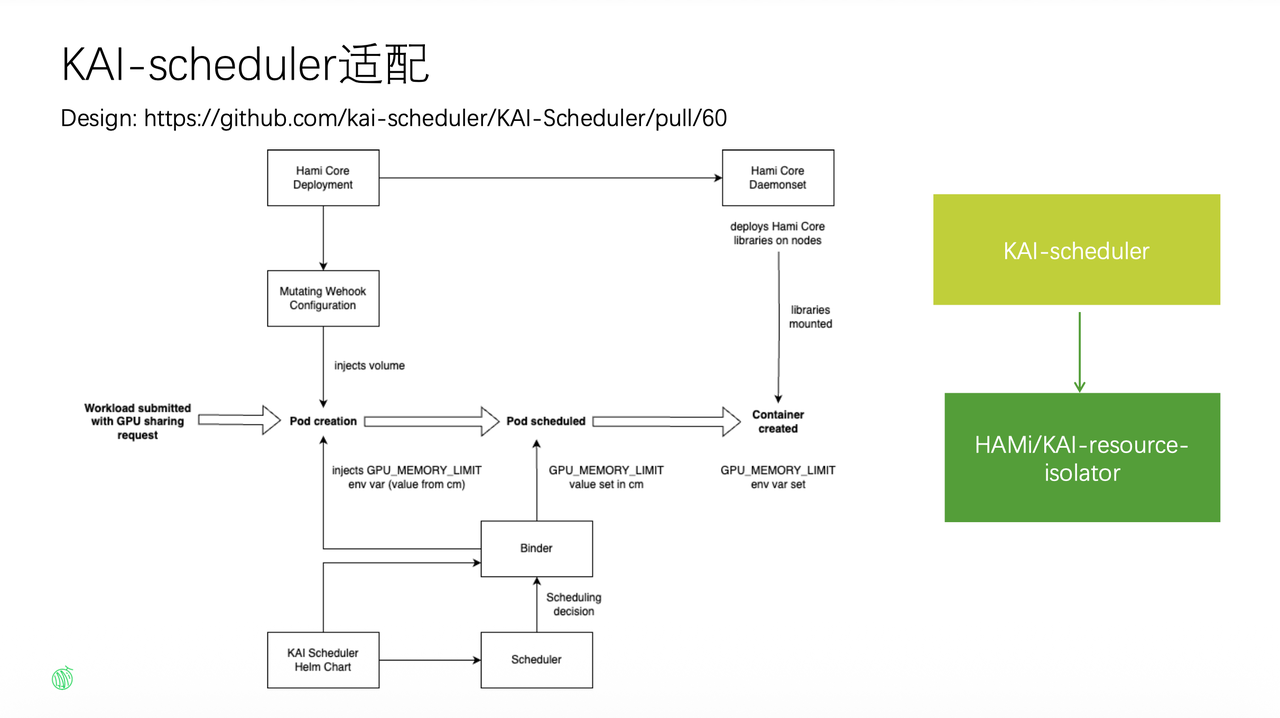
1. KAI-scheduler Resource Isolation
In GPU sharing scenarios, "able to share" and "safely share" are two different things. If two tenants' workloads run on the same card without isolation, resource contention becomes inevitable. v2.9 introduces the kai-resource-isolator component, specifically addressing low-level resource isolation for KAI-Scheduler scenarios. Moving from "able to share" to "safely share" represents a critical step for HAMi in the multi-tenant direction.
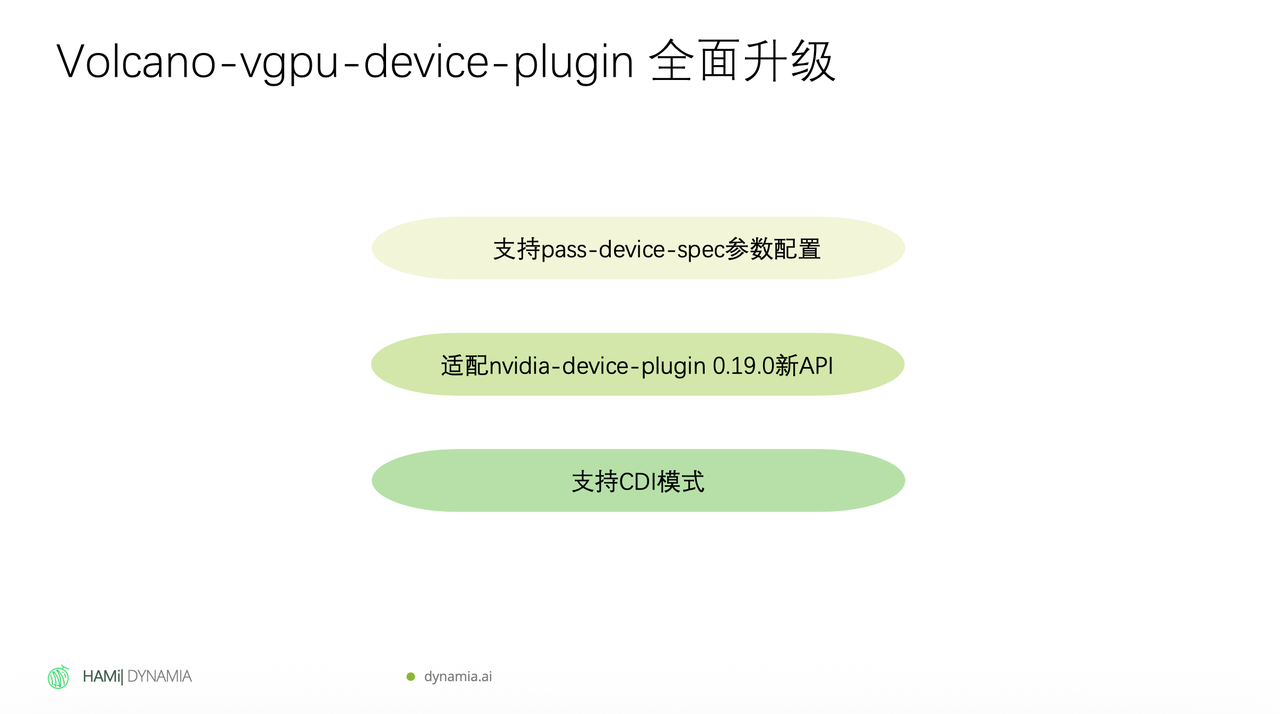
2. Volcano vGPU Version Upgrade
The underlying Device Plugin has been upgraded to version 0.19, with CDI mode support and compatibility with the latest NVIDIA drivers and devices. For teams already running Volcano vGPU in production, this upgrade means improved stability and compatibility.
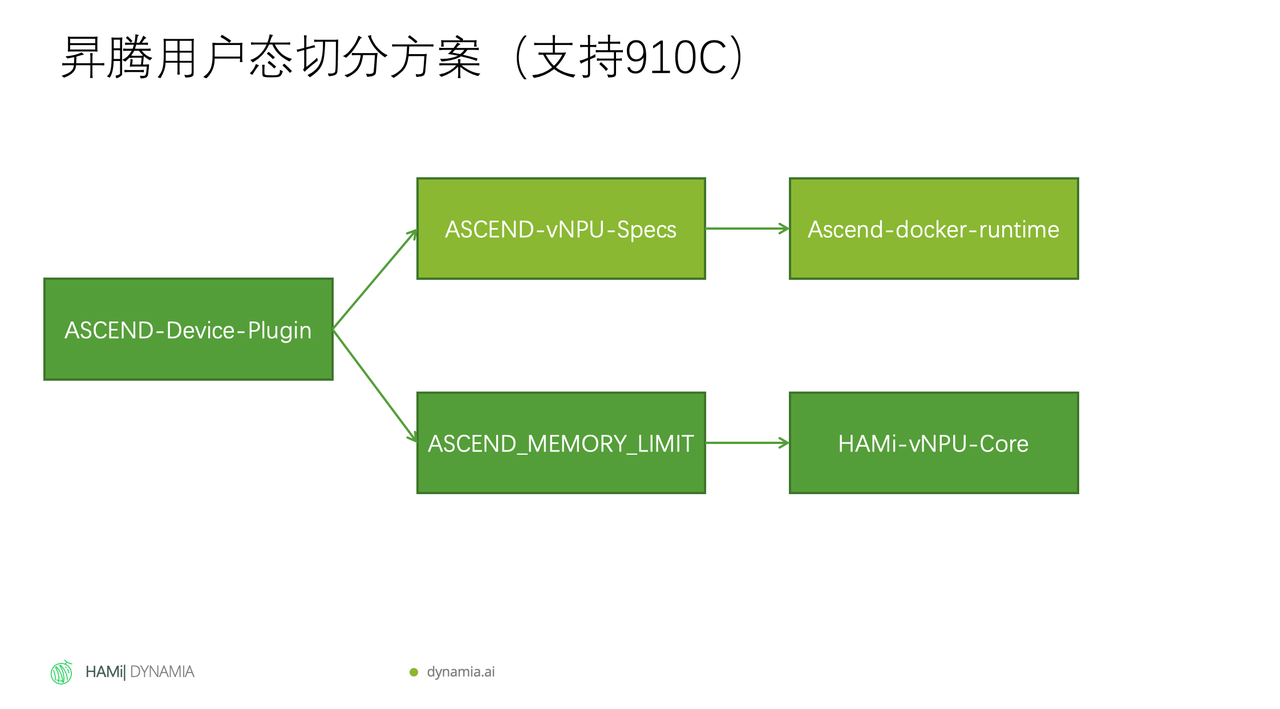
3. Ascend 910C Userspace Partitioning
This is the most notable domestic chip support advancement in v2.9. The Ascend 910C doesn't support hardware-level isolation like NVIDIA's MIG, but HAMi found a software-based solution — using environment variables to control compute and memory allocation limits, achieving MIG-like virtualization through purely software means. For teams heavily using domestic chips, this feature is highly practical.
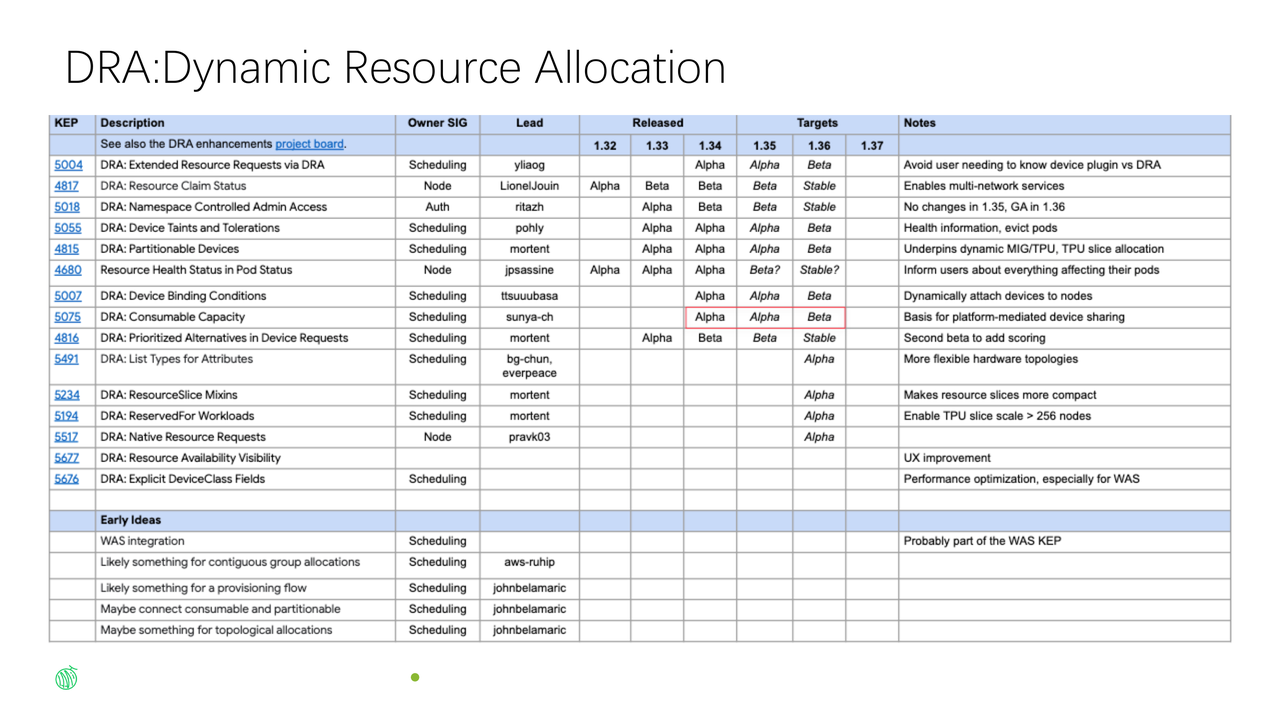
3. DRA: The Next Frontier in Heterogeneous Compute Management
DRA (Dynamic Resource Allocation) is the Kubernetes community's next-generation technology for resource management. Li Mengxuan didn't shy away from DRA's current challenges, instead offering a candid analysis.
Three Major Challenges with DRA Today
DRA currently faces three major challenges:
- API Stability: DRA is still in rapid iteration with frequent API changes, driving high driver development costs and uncertainty for chip vendors
- Missing Ops Capabilities: Lacks cluster-level monitoring, scheduling event observability, and other critical operational capabilities needed for production environments
- Limited Topology Expression: Difficult to express complex physical topologies (e.g., specific inter-card direct connections), constraining scheduling optimization
HAMi's DRA Solution: Lightweight HAMi
Facing these challenges, HAMi's approach is to build a "Lightweight HAMi":
- Upward: Shields users from DRA API complexity and instability with a clean, simple interface
- Downward: Provides a unified resource request entry point connecting to various heterogeneous hardware drivers
- Filling gaps: Native DRA currently lacks cluster monitoring and scheduling event capabilities — HAMi fills these gaps
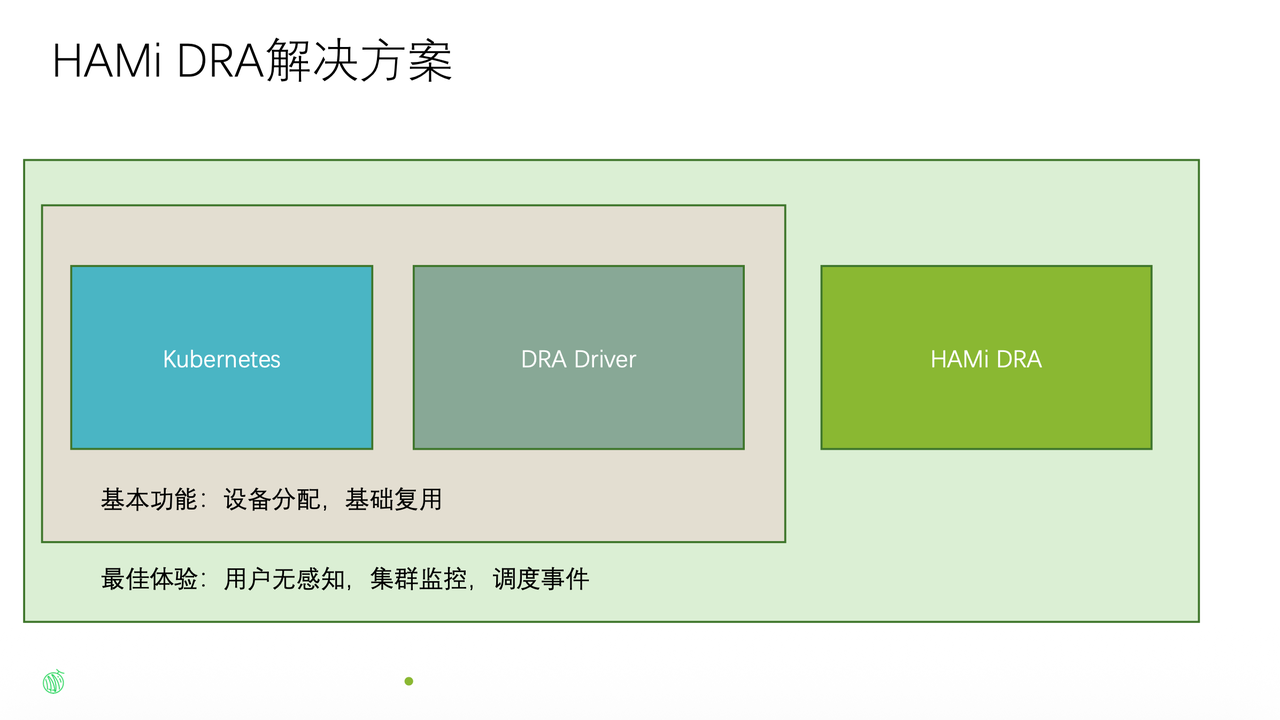
Additionally, HAMi is partnering with NVIDIA, Enflame, Huawei Ascend, and other chip vendors to jointly validate DRA driver compatibility, accelerating DRA adoption in heterogeneous compute scenarios.
4. Selected Q&A

After the presentation, audience members actively asked questions. Here are some of the most representative questions along with Li Mengxuan's responses:
Q1: Does HAMi support dynamic scaling?
Memory scaling is already in development and is expected to land in the 2.10 release. However, hot-plugging GPU cards is not yet feasible — this capability depends on container runtime support and cannot be directly achieved at the Kubernetes layer.
Q2: How does HAMi work with schedulers like Volcano?
Fully compatible. HAMi DRA can serve as a lightweight middleware that works alongside schedulers like Volcano — Volcano handles queue management and batch scheduling, while HAMi handles GPU resource partitioning and multiplexing, each doing what it does best.
Q3: If the GPU utilization bottleneck is in data transfer, what's the point of virtualization?
The premise of this question is correct — in training scenarios, the bottleneck is indeed data transfer. But inference is different. Many inference services exhibit clear peaks and valleys; when there are no requests, the GPU sits idle. The value of virtualization lies in allowing multiple inference workloads to share the same card in a staggered fashion, putting otherwise idle compute to use. This is a classic trade-off between peak performance and utilization.
5. Summary
Li Mengxuan's presentation clearly outlined the full picture of HAMi's development: from the core value of GPU sharing, to the practical progress in resource isolation and domestic chip support in v2.9, and the forward-looking layout toward Kubernetes DRA.
Several key takeaways are worth remembering:
- GPU sharing is not a gimmick — it's a necessity. Cluster utilization jumping from 20% to 70% is not a theoretical number, but a result already validated in production environments.
- Secure multi-tenant sharing is the next critical challenge. The kai-resource-isolator introduced in v2.9 is pushing HAMi from "able to share" toward "safely share."
- Domestic chip adaptation requires software-level innovation. The Ascend 910C userspace partitioning solution proves that GPU virtualization can be achieved through software means even without hardware-level isolation.
- DRA is the direction, but the road ahead is long. HAMi's approach of participating in the DRA ecosystem with a "lightweight" mindset both lowers the barrier to entry for users and provides a viable path for unified heterogeneous compute management.
HAMi is evolving from a GPU sharing tool into a heterogeneous compute management platform covering multiple chips and multi-cloud environments. If you're interested in HAMi, check out the project's GitHub repository and join the community to contribute.