HAMi v2.9.0 Deep Dive: Ascend User-Space Partitioning, DRA Production-Ready, and Scheduling Ecosystem Expansion
HAMi v2.9.0 has been officially released! Since v2.8, the project has made significant progress in heterogeneous device virtualization depth, Kubernetes native standards adoption, and scheduler ecosystem expansion. v2.9 brings systematic enhancements in Ascend user-space partitioning, DRA production readiness, pluggable scheduler integration, and observability/security, evolving HAMi from a "GPU sharing tool" into a unified heterogeneous computing management and scheduling infrastructure platform.
Highlights at a Glance
Key feature highlights of the v2.9 release:
- Ascend 910C User-Space Virtualization: Introduces HAMi-core mode with LD_PRELOAD-based user-space interception, enabling fine-grained memory and compute sharing without modifying application code, validated in China Merchants Bank's production environment.
- HAMi-DRA Production-Ready: HAMi-DRA, the independent implementation based on Kubernetes DRA standards, bumps to v0.2.0, officially reaching production-ready status across NVIDIA / Ascend / Enflame platforms.
- Security & Stability Enhancements: Scheduler routes add DoS protection, NodeLock optimizes to exponential backoff, Webhook adds resource quota checking, with fixes for multiple critical production stability issues.
- Heterogeneous Device Coverage Expansion: New Vastai (Hanbo Semiconductor) device support further enriches the domestic heterogeneous computing management landscape.
Ascend 910C User-Space Partitioning — HAMi-core Mode (Key Feature)
Huawei Ascend 910C is one of the primary domestic AI computing chips. In production environments, users have long faced a critical question: How can multiple inference/training tasks share a single Ascend card?
Traditional device management approaches have two extremes:
- Exclusive mode: One Pod occupies the entire card, resulting in extremely low resource utilization
- SR-IOV hardware partitioning: Requires specific hardware support, fixed partitioning granularity, insufficient flexibility
HAMi v2.9.0 introduces HAMi-core mode, implementing user-space soft partitioning of memory and compute without modifying application code or requiring specific hardware support. This is the most important feature in this release.
Why User-Space Partitioning?
Before HAMi-core, Ascend device sharing primarily relied on SR-IOV hardware virtualization, which had several fundamental limitations:
- Coarse granularity: SR-IOV splits a physical card into fixed Virtual Functions (VFs), typically only supporting fixed ratios like 1/2, 1/4 of the entire card
- Inflexible: Partitioning ratios are preset at the hardware level and cannot be dynamically adjusted based on actual workloads
- Hardware dependency: Not all Ascend hardware versions support SR-IOV, and firmware coordination is required
HAMi-core fundamentally changes this landscape — through pure software interception and management of ACL calls in user space, it achieves MB-level memory and percentage-level compute fine-grained partitioning. A single Ascend 910C can simultaneously serve multiple inference or training tasks with different specifications.
Technical Architecture
How HAMi-core works:
- LD_PRELOAD Interception: At container startup, an interception library is injected via
LD_PRELOAD, intercepting the application's calls to Ascend Computing Language (ACL) - Memory Isolation: Each Pod's memory allocation is strictly limited to its declared quota at MB-level granularity, preventing one task from exhausting the entire card's memory
- Compute Throttling: Based on the Pod's declared compute quota, ACL compute calls are scheduled via time-slice round-robin, ensuring fair compute resource access for all tasks
- Passthrough Execution: Calls within quota limits are passed directly to the hardware driver without additional latency, ensuring near-native performance
Partitioning Granularity Comparison
Comparison of HAMi-core with traditional approaches:
| Dimension | Exclusive Mode | SR-IOV | HAMi-core (v2.9) |
|---|---|---|---|
| Memory Partitioning | Not partitionable | Fixed per VF allocation | MB-level precise control |
| Compute Partitioning | Not partitionable | Proportional per VF | Percentage-level flexible configuration |
| Number of Partitions | 1 Pod/card | Usually 2-4 VF/card | 10+ Pods/card |
| Hardware Support Required | No | Yes | No |
| Application Code Changes Required | No | No | No |
| Dynamic Adjustment | Not supported | Not supported | Supported |
For example, a 64GB Ascend 910C can be allocated to multiple tasks as follows:
# Task 1: Large model inference, 32GB memory + 50% compute
resources:
limits:
hami.io/vnpu-core: "50"
hami.io/vnpu-core-memory: "32768" # 32GB = 32768MB
# Task 2: Model fine-tuning, 16GB memory + 30% compute
resources:
limits:
hami.io/vnpu-core: "30"
hami.io/vnpu-core-memory: "16384" # 16GB = 16384MB
# Task 3: Lightweight inference, 8GB memory + 20% compute
resources:
limits:
hami.io/vnpu-core: "20"
hami.io/vnpu-core-memory: "8192" # 8GB = 8192MB
Core Capabilities
Ascend 910C SuperPod Support
For SuperPod environments, HAMi implements module-pair level resource allocation. In distributed training scenarios, multiple Ascend chips are interconnected via HCCS/RoCE to form super nodes. HAMi can identify and manage this topology structure, fully leveraging the hardware advantages of super nodes.
vNPU-Core Virtualization
A new hami-vnpu-core resource type supports more flexible compute partitioning strategies:
apiVersion: v1
kind: Pod
metadata:
name: ascend-inference
annotations:
hami.io/vnpu-core: "ascend910c"
spec:
containers:
- name: inference
image: ascend-inference:latest
resources:
limits:
hami.io/vnpu-core: "1"
hami.io/vnpu-core-memory: "16384"
Annotation-based node filtering and multi-device request capabilities:
# Node filtering: Only schedule on nodes with specific annotations
metadata:
annotations:
hami.io/vnpu-core-node-filter: "ascend910c-module-0"
Enabling HAMi-core
Set ascend.hamiVnpuCore to true in Helm values to enable this feature:
# values.yaml
ascend:
hamiVnpuCore: true
It can also be enabled individually in ascend-device-plugin node configuration, supporting partial node enablement within the same cluster.
Important: In v2.9, Pods must explicitly declare
huawei.com/vnpu-mode: 'hami-core'in annotations to use HAMi-core mode:
apiVersion: v1
kind: Pod
metadata:
name: ascend-inference
annotations:
huawei.com/vnpu-mode: "hami-core"
spec:
containers:
- name: inference
image: ascend-inference:latest
resources:
limits:
hami.io/vnpu-core: "1"
hami.io/vnpu-core-memory: "16384"
Pods without this annotation will continue using the legacy template-based vNPU partitioning. If no suitable nodes are available, the task will remain in pending state.
Production Validation
This feature has been validated in China Merchants Bank's production environment. Based on the HAMi-vNPU-Core soft partitioning solution, China Merchants Bank achieved 100% resource pooling of Ascend 910C computing power and high-performance communication for large models, significantly improving domestic computing resource utilization.
Thanks to Huawei Cloud Canada Lab and China Merchants Bank @ashergaga for their contributions to this feature.
This release also updates the HAMi-core performance benchmark data. For detailed benchmark procedures, refer to the project documentation.
HAMi-DRA — Lightweight HAMi Based on Kubernetes Standards
In HAMi v2.9.0, HAMi-DRA officially reaches production-ready status. HAMi-DRA is an independent implementation project based on Kubernetes Dynamic Resource Assignment (DRA) standards, positioned as a "lightweight HAMi".
From Device Plugin to DRA
DRA is the next-generation device resource declaration and allocation mechanism being advanced by the Kubernetes community. The traditional Device Plugin model has the following limitations:
- Inflexible resource declaration: Device resources are hard-coded via
limits[nvidia.com/gpu], unable to express complex requirements like memory/compute separation or topology constraints - Scattered scheduling logic: Each device plugin needs to implement its own scheduling logic, making unified management difficult
- Difficult resource composition: Cannot express compound requirements like "multiple GPUs with specific topology"
DRA standardizes device resource declaration, allocation, and management by introducing new APIs like ResourceClaim and DeviceClass.
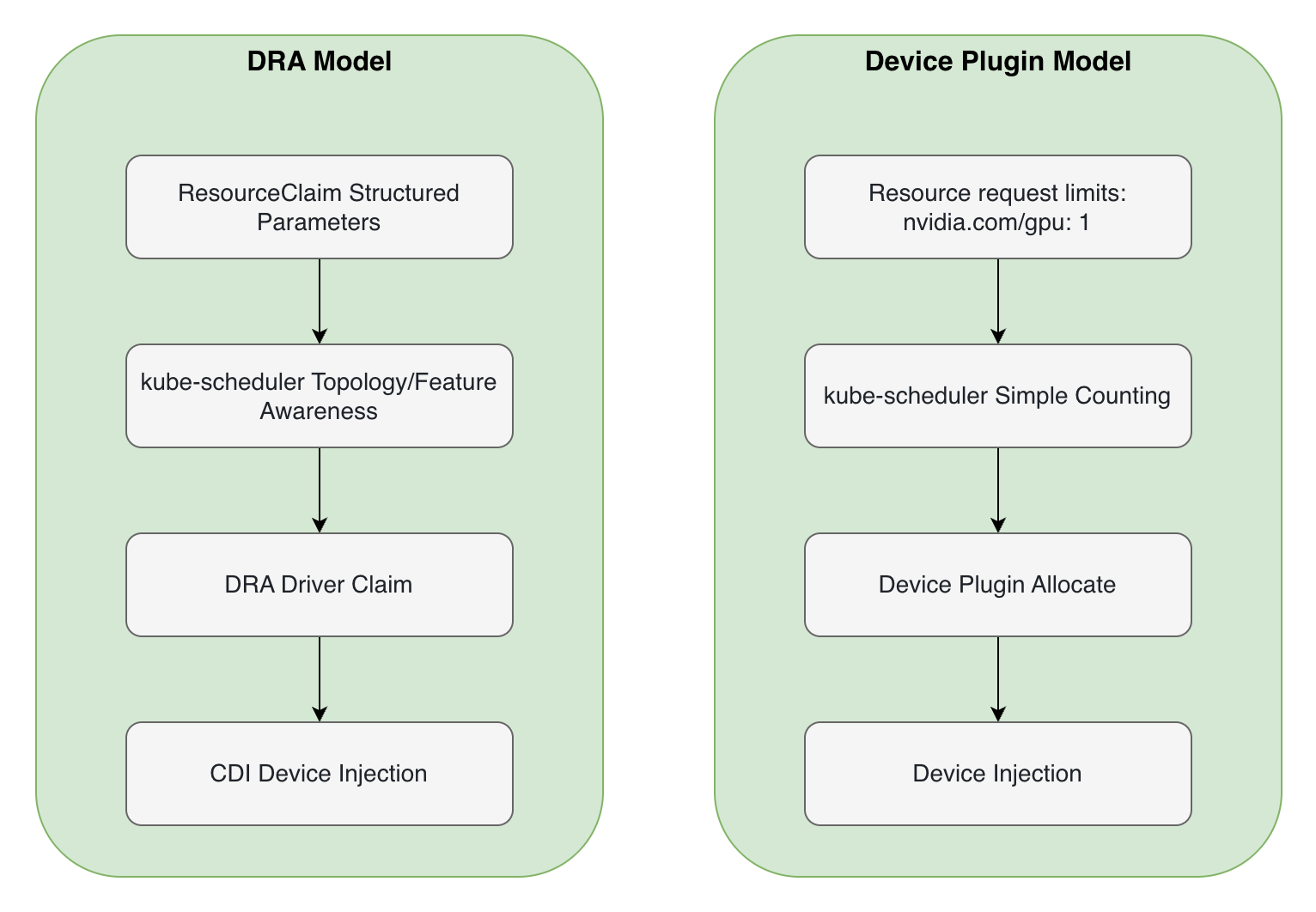
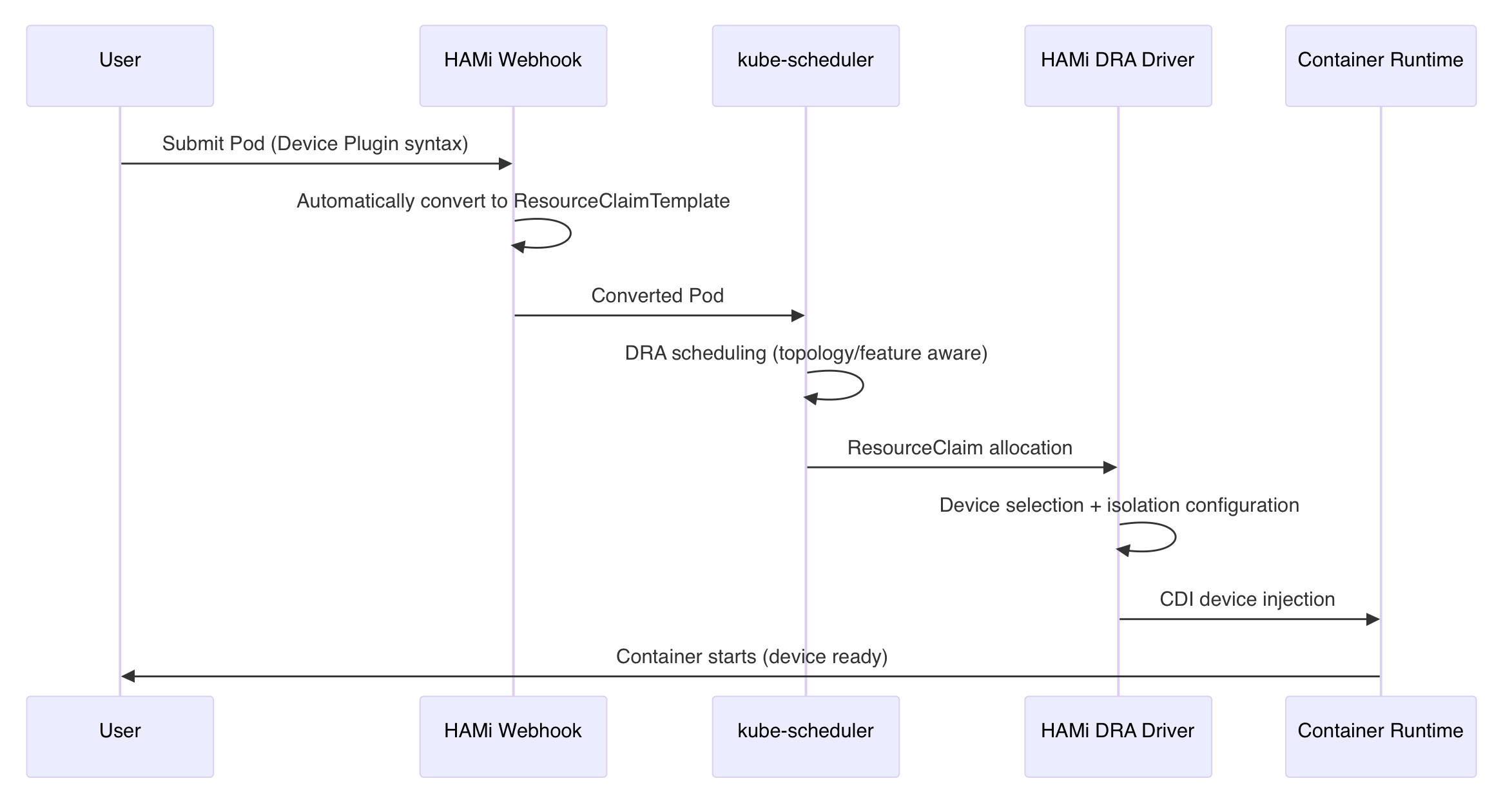
HAMi-DRA Design Philosophy
HAMi-DRA adopts a Mutating Webhook architecture. The core philosophy can be summarized in three points:
- Don't change user habits: Continue using Device Plugin syntax, automatically converting to DRA resource models underneath
- Internalize complexity: Webhook, Driver, and lifecycle management are all handled by the system
- Drive evolution through community collaboration: Contributors from different companies validate solutions in real production environments
Platform Support
HAMi-DRA has bumped to v0.2.0, supporting three major platforms:
| Platform | Virtualization Method | Status |
|---|---|---|
| NVIDIA | HAMi-core time-slicing + memory soft limits | Production-ready |
| Ascend | vNPU-Core user-space partitioning | Production-ready |
| Enflame | Compute/memory partitioning | Production-ready |
Installing HAMi-DRA:
Prerequisites:
- Kubernetes >= 1.34 with DRA Consumable Capacity featuregate enabled
- Container runtime with CDI (Container Device Interface) enabled
- NVIDIA GPU Driver 440+
- cert-manager installed
# Clone the repository and install
git clone https://github.com/Project-HAMi/HAMi-DRA.git
cd HAMi-DRA
helm install hami-dra ./charts/hami-dra
# If not using gpu-operator's containerd driver:
helm install hami-dra ./charts/hami-dra --set drivers.nvidia.containerDriver=false
# If monitoring components are not needed:
helm install hami-dra ./charts/hami-dra --set monitor.enabled=false
After installation, usage is the same as HAMi.
Submitting workloads (automatically converted from Device Plugin syntax):
apiVersion: v1
kind: Pod
metadata:
name: gpu-inference
annotations:
hami.io/gpu-memory: "4096"
hami.io/gpu-core: "50"
spec:
containers:
- name: inference
image: pytorch:latest
resources:
limits:
nvidia.com/gpu: "1"
HAMi-DRA Project: https://github.com/Project-HAMi/HAMi-DRA
Volcano vGPU Upgraded to v0.19 + CDI
HAMi v2.9.0 synchronizes the built-in Volcano vGPU Device Plugin to v0.19, maintaining consistency with the Volcano upstream.
CDI Mode Support
Container Device Interface (CDI) is the standard device injection interface for container runtimes defined by the CNCF CDI specification. Compared to traditional approaches:
| Dimension | Traditional Approach | CDI Approach |
|---|---|---|
| Device Injection | Manual /dev mounts, environment variable setup | Declarative CDI device list |
| Runtime Coupling | Tightly coupled | Loosely coupled |
| Multi-device Support | Manual management required | Automatic aggregation |
| MIG Support | Complex configuration management | Standardized declaration |
Enable CDI mode:
# values.yaml
devicePlugin:
cdIEnabled: true
nvidia:
cdIEnabled: true
This upgrade also fixes MIG allocation issues under CDI mode, further enhancing NVIDIA GPU flexible partitioning capabilities.
Observability Enhancements
v2.9.0 includes multiple observability improvements:
- vGPU Monitor adds
--metrics-bind-addressparameter for custom metrics exposure address - Helm Chart adds Prometheus ServiceMonitor covering scheduler and device plugin
- Prometheus metrics and label naming aligned with community best practices
- New device type label support in metrics
- Optimized log level control with related unit tests added
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: hami-scheduler
namespace: hami-system
spec:
selector:
matchLabels:
app.kubernetes.io/name: hami-scheduler
endpoints:
- port: metrics
interval: 15s
Security & Stability
Security Hardening
DoS Protection
Scheduler routes add io.LimitReader to limit HTTP request body size, preventing OOM caused by malicious or abnormally large request bodies.
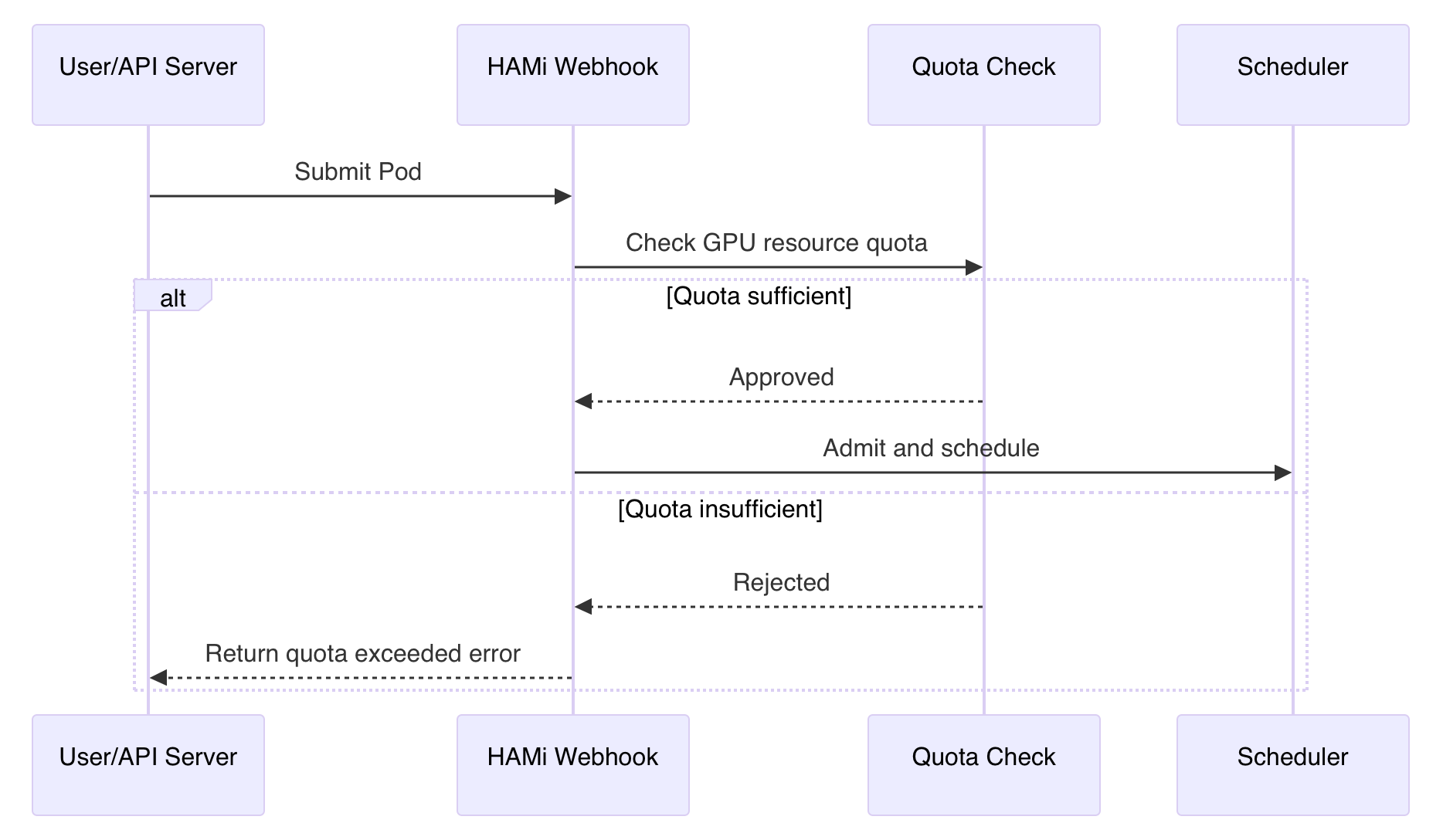
Webhook Resource Quota Checking
v2.9.0 adds Resource Quota checking capability in the Webhook. GPU resource requests can be validated against quota limits at the Pod submission stage, avoiding post-scheduling rollbacks and improving overall scheduling efficiency.
Critical Bug Fixes
v2.9.0 fixes multiple critical issues affecting production stability:
| Issue | Impact | Fix |
|---|---|---|
| NodeLock contention | Large-scale cluster scheduling performance degradation | Exponential backoff strategy |
| Leader election nil pointer | HA deployment occasional crashes | Null check |
| Scheduler score division by zero | Scoring anomalies | Safe division |
| Multi-container Pod device allocation | Init container device allocation conflicts | Lifecycle-aware allocation |
| Kernel 6.17 NVIDIA health check | GPU status check handshake failure | Boundary condition handling |
| Global image tag override | Component-level image tags ignored | Tag priority fix |
| Stale Deleted handshake | Node scheduling interruption | State cleanup |
| Device filter ineffective | filter device config not working | Filter logic fix |
| Device Plugin/Scheduler annotation mismatch | Device allocation anomalies | Annotation alignment |
Heterogeneous Device Ecosystem Expansion
New Vastai (Hanbo Semiconductor) Device Support
Vastai Technologies is a leading domestic general-purpose GPU chip design company, with chips widely used in AI inference, graphics rendering, video processing, and other scenarios. HAMi v2.9.0 adds support for Vastai devices, further expanding HAMi's heterogeneous computing management into the domestic GPU space.
Two Allocation Modes
Vastai devices support two resource allocation modes:
| Mode | Description | Use Case |
|---|---|---|
| Full-Card Mode | Each Pod exclusively occupies an entire GPU | Large model training, performance-sensitive inference |
| Die Mode | Partitioned by chip Die, supports topology-aware scheduling | Multi-task sharing, resource utilization optimization |
In Die mode, the scheduler is aware of the AIC (Accelerator Interface Card) topology, attempting to allocate multiple resources requested by the same Pod to the same AIC, reducing cross-Die communication overhead.
Configuration and Usage
Node Labeling:
Before installing HAMi, label nodes with Vastai devices:
kubectl label node <node-name> vastai=on
Helm values configuration:
vastai:
enabled: true
customresources:
- vastaitech.com/va
Full-Card mode example:
apiVersion: v1
kind: Pod
metadata:
name: vastai-inference
spec:
containers:
- name: inference
image: vastai-inference:latest
resources:
limits:
vastaitech.com/va: "1"
Die mode example:
Specify device selection strategy via annotations:
apiVersion: v1
kind: Pod
metadata:
name: vastai-die-inference
annotations:
vastaitech.com/use-va: "0"
vastaitech.com/nouse-va: "1"
spec:
containers:
- name: inference
image: vastai-inference:latest
resources:
limits:
vastaitech.com/va: "2"
With Vastai device support, HAMi now covers NVIDIA, Huawei Ascend, Cambricon, Hygon DCU, Biren, Enflame, MetaX, Kunlunxin, AMD, Iluvatar, AWS Neuron, and Vastai — over a dozen heterogeneous computing devices, making it one of the most broadly covering heterogeneous device virtualization and scheduling projects in the Kubernetes ecosystem.
DRA Ecosystem Alliance
DRA is becoming the next-generation device management model for Kubernetes, but there are implementation uncertainties on the vendor side and high usage barriers on the user side. To address this, the HAMi community announced the launch of the DRA Ecosystem Alliance at the 3rd HAMi Meetup in Shenzhen.
Goals of the DRA Ecosystem Alliance:
- Connect device vendors with users to drive DRA adoption in real-world scenarios
- Promote DRA standards evolution to reduce the engineering cost of heterogeneous device integration
- Unify the scheduling layer to abstract underlying hardware differences, enabling unified heterogeneous computing management
Upgrade Guide
Upgrade to v2.9.0 via Helm:
helm repo add hami-charts https://project-hami.github.io/HAMi/
helm repo update
helm upgrade hami hami-charts/hami -n hami-system
For complete installation documentation, visit: https://project-hami.io/docs/usage/install
Upgrade Notes:
- If using Volcano vGPU mode, note the CDI-related configuration changes
- If using Ascend devices and want to enable HAMi-core mode, refer to the Ascend configuration section in the latest documentation
- It's recommended to verify compatibility in a test environment before upgrading
Community Updates
During the v2.9.0 release cycle, the HAMi community remained active in technical advocacy, product ecosystem, and user practices. Here are the noteworthy community developments.
Community Events
- KubeCon EU 2026: HAMi appeared in Amsterdam as a CNCF Sandbox project, setting up a Project Pavilion booth and taking the main stage Keynote Demo to showcase the latest Kubernetes GPU virtualization advancements to developers worldwide. Read recap
- KCD Beijing 2026: Over 1,000 registrations, breaking KCD Beijing records. The HAMi community was invited to share "From Device Plugin to DRA: GPU Scheduling Paradigm Upgrade and HAMi-DRA Practice." Read recap
- 3rd HAMi Meetup Shenzhen: Seven experts from CNCF, SF Technology, China Merchants Bank, Enflame Technology, and others shared insights on the future of AI computing cloud-native. Read recap
- HAMi WebUI Official Release: The HAMi community launched the open-source GPU monitoring dashboard HAMi WebUI v1.1.0, presenting the entire GPU cluster in a single visual interface, achieving a complete closed loop from GPU scheduling to visual observability. Read blog post
Website and Documentation Overhaul
Since the v2.8.0 release, the HAMi website and documentation have undergone the largest-scale restructuring in project history. Approximately 195 PRs were merged into the website repository, covering the following major areas:
- Website Redesign: Homepage redesign, architecture diagram redraws, unified blog styling, mobile optimization, enhanced footer, migration from external search to built-in search
- New Documentation: GPU virtualization principles page, HAMi quick start guide, real-time GPU monitoring guide, upgrade and uninstallation guide, HAMi WebUI user and developer guides, Vastai device documentation
- i18n Sync: Continuous Chinese-English documentation alignment, sidebar label localization, announcement banner multilingual support
- Community Content: New blog posts including KubeCon EU 2026 recap, KCD Beijing 2026 DRA sharing, HAMi WebUI release, Meetup Shenzhen recap; adopter information updates for Keike, NIO, SNOW Corp., Bovi Wisdom
- Quality Governance: Site-wide copy de-marketing, grammar corrections, code block language annotations, format standardization, contributor guide and governance documentation improvements
Thanks to @mesutoezdil for contributions to HAMi official documentation optimization.
Website: https://project-hami.io
CNCF Case Studies
An increasing number of enterprises are using HAMi in production environments to build GPU virtualization and heterogeneous computing scheduling capabilities. The following case studies have been published on the CNCF website:
- Keike Holdings: Built AIStudio intelligent computing platform based on Kubernetes + HAMi, improving GPU utilization from 13% to 37% (nearly 3x), supporting 10,000+ concurrent Pods, processing tens of millions of daily business requests. Read full article
- NIO: Adopted HAMi hybrid GPU sharing strategy for autonomous driving workloads, improving CI pipeline GPU utilization by approximately 10x, reducing simulation workload GPU time by approximately 30%, covering a production cluster of approximately 600 GPUs. Read full article
- SNOW Corp.: Korea's NAVER subsidiary SNOW Corp. manages 1,000+ A100 GPUs, achieving GPU sharing through HAMi to handle 700% traffic spikes, halving GPU requirements with estimated savings of $17.4 million. Read full article
New Contributors
The v2.9.0 release welcomed 19 new contributors to the HAMi project from different countries and organizations:
@maishivamhoo123, @hoteye, @jsl9208, @ashergaga, @Atroxgod, @MyoungHaSong, @charford, @jcustenborder, @Nov11, @ilia-medvedev, @Yonsun-w, @CFH2436, @kenwoodjw, @anandj91, @ManishSharma1609, @maverick123123, @almazkhalikov, @lin121291, @mesutoezdil
Thank you to every contributor!
Related Links:
- GitHub Release: https://github.com/Project-HAMi/HAMi/releases/tag/v2.9.0
- HAMi-DRA: https://github.com/Project-HAMi/HAMi-DRA
- Volcano vGPU Device Plugin: https://github.com/Project-HAMi/volcano-vgpu-device-plugin
- Project Documentation: https://project-hami.io
- Community Portal: https://project-hami.io/community
- Community Discord (recommended): https://discord.gg/Amhy7XmbNq
- Community CNCF Slack: https://cloud-native.slack.com/archives/C08844T5WBQ