Making GPU as Accessible as Utilities: HAMi-Powered GPU Pooling at SF Technology
"Maximize Efficiency, Not Compute" — the HAMi Community Meetup Shenzhen was hosted by the HAMi community and organized by Dynamia AI, concluding successfully on April 25, 2026. This is the third article in the HAMi Shenzhen Meetup recap series. Chen Junchao from SF Technology shared the complete evolution from bare-metal to a multi-cloud hybrid architecture, providing an in-depth analysis of HAMi-based GPU pooling, memory oversubscription, and mixed deployment scheduling in production.
Thanks to SF Technology for co-hosting this event and providing the venue.
Speaker: Chen Junchao (Senior Backend Engineer, SF Technology)

Key Highlights
- 5 private clouds + 4 public clouds multi-cloud hybrid architecture, scheduler fully switched to Volcano
- GPU model-level resource reporting, eliminating the need for labels and taints in operations
- Sandbox and high-priority inference tasks sharing physical GPUs, resource reuse through staggered scheduling
- Memory oversubscription: up to 200% memory overcommit, zero intrusion
- Production and test clusters saved up to 57% GPU
Video Recording & Slides
- Bilibili: HAMi Multi-Cloud Practice at SF Technology - Chen Junchao
- Download Slides: hami-multi-cloud-practice-sf-tech-chenjunchao.pdf
I. AI Platform Evolution: From Kubeflow to Multi-Cloud Hybrid
The evolution path of SF Technology's AI platform mirrors that of many enterprises building their AI infrastructure.
Starting Out: The Kubeflow Era
The AI platform was initially built on Kubeflow, with core business covering three major modules:
- Sandbox: Developers' daily experimentation environment
- Workflow: Model training and data processing pipelines
- Model Serving: Online inference services
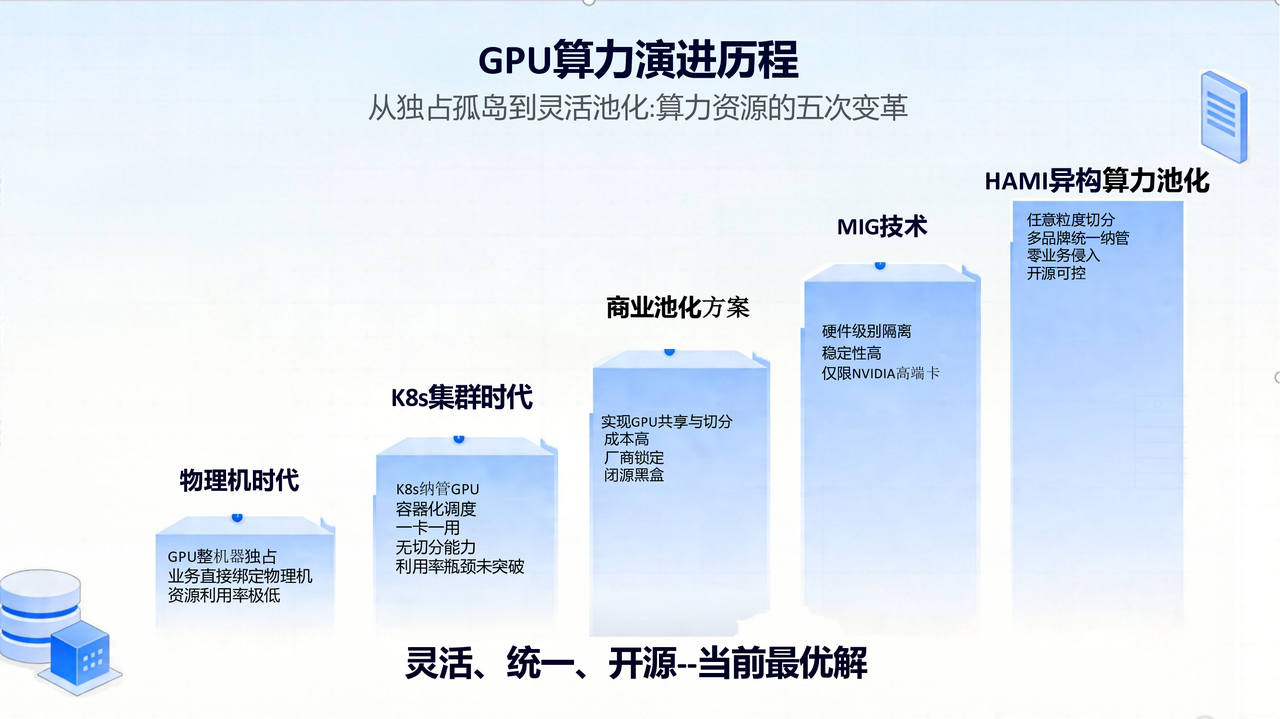
Evolution: Full Scheduler Replacement
As business scale grew, the underlying scheduler was fully replaced from the default Kubernetes scheduler to Volcano to handle large-scale Pod scheduling demands. This decision laid a solid foundation for subsequent GPU pooling.
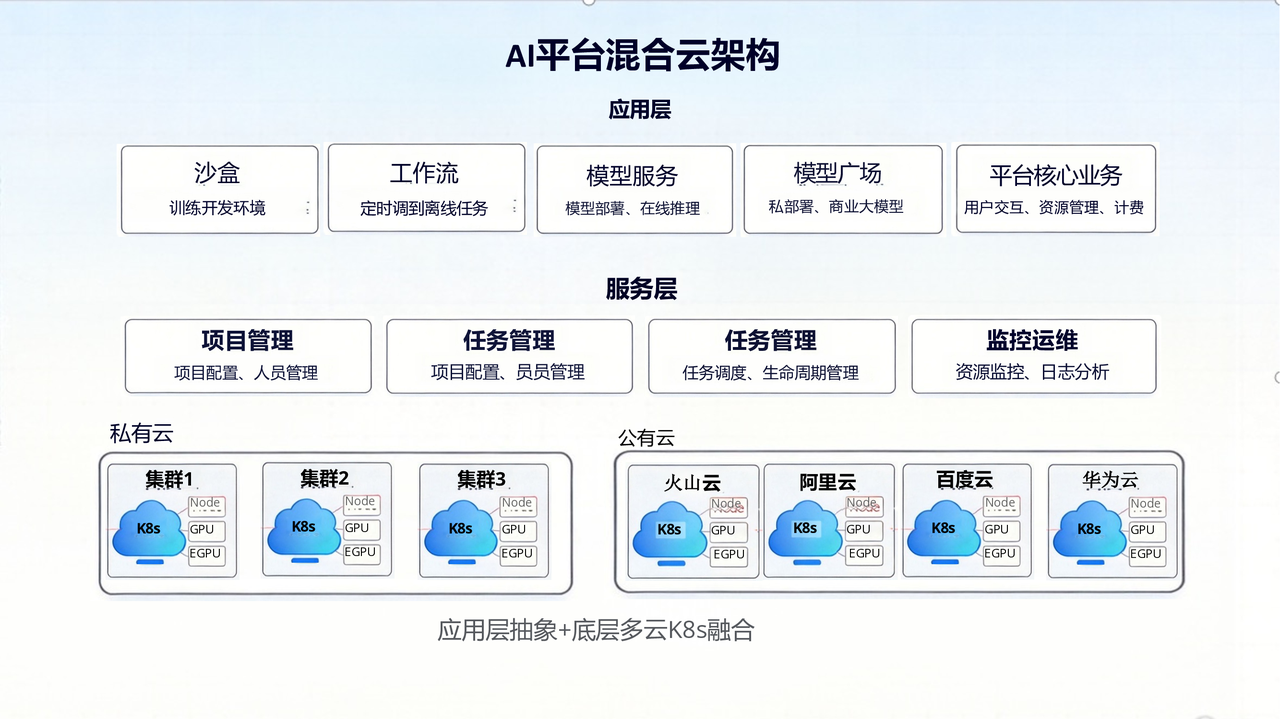
Current State: Multi-Cloud Hybrid Architecture
The platform currently manages 5 private cloud K8s clusters and has integrated with four public cloud providers — Volcengine, Alibaba Cloud, Baidu Cloud, and Huawei Cloud — leveraging public cloud resources to supplement private cloud compute capacity gaps.
Why multi-cloud? On-premises data centers primarily deploy V100, A100, and some H20 GPUs, but procurement costs are high with long lead times. Public cloud resources are mostly procured on monthly or annual subscriptions, used to handle compute shortages and flexible scaling needs.
II. GPU Resource Management: Deep Customization of Device Plugin
From Generic to Fine-Grained: GPU Model-Level Resource Reporting
The native Device Plugin reports all GPUs uniformly as nvidia.com/gpu, making different models indistinguishable. The SF Technology team modified the Device Plugin configuration to refine resource reporting types to:
gpu-a100, gpu-v100, gpu-h20 ...
This enables precise GPU model matching at the scheduling layer.

Simplified Operations: Goodbye Labels and Taints
The team eliminated the dependency on node labels and taints, simplifying operational configuration and achieving unified management of all GPU resources through Volcano.
vGPU Device Plugin Adaptation
Code modifications were made to Volcano's vGPU Device Plugin, enabling it to report specific GPU card models (e.g., vgpu-number-l20) for precise matching at the scheduling layer.
III. Three Key HAMi Use Cases
Use Case 1: GPU Partitioning (Fine-Grained Resource Allocation)
For tasks with low memory and compute utilization, HAMi enables fine-grained GPU partitioning (at the memory/compute level), splitting a physical GPU into multiple independently schedulable resource units, thereby improving resource utilization and reducing fragmentation waste.
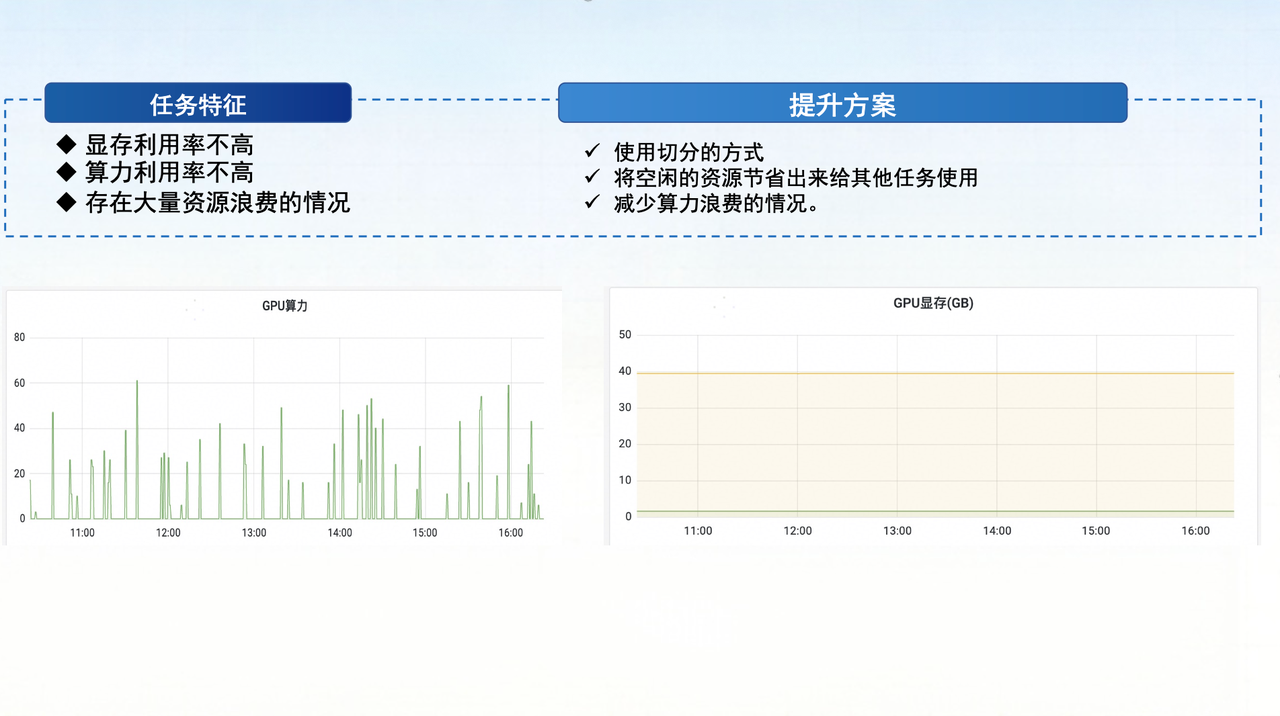
The core of this capability lies in transforming GPUs from "whole-card exclusive" to "allocatable fine-grained resources," enabling low-load tasks to share the same physical card.
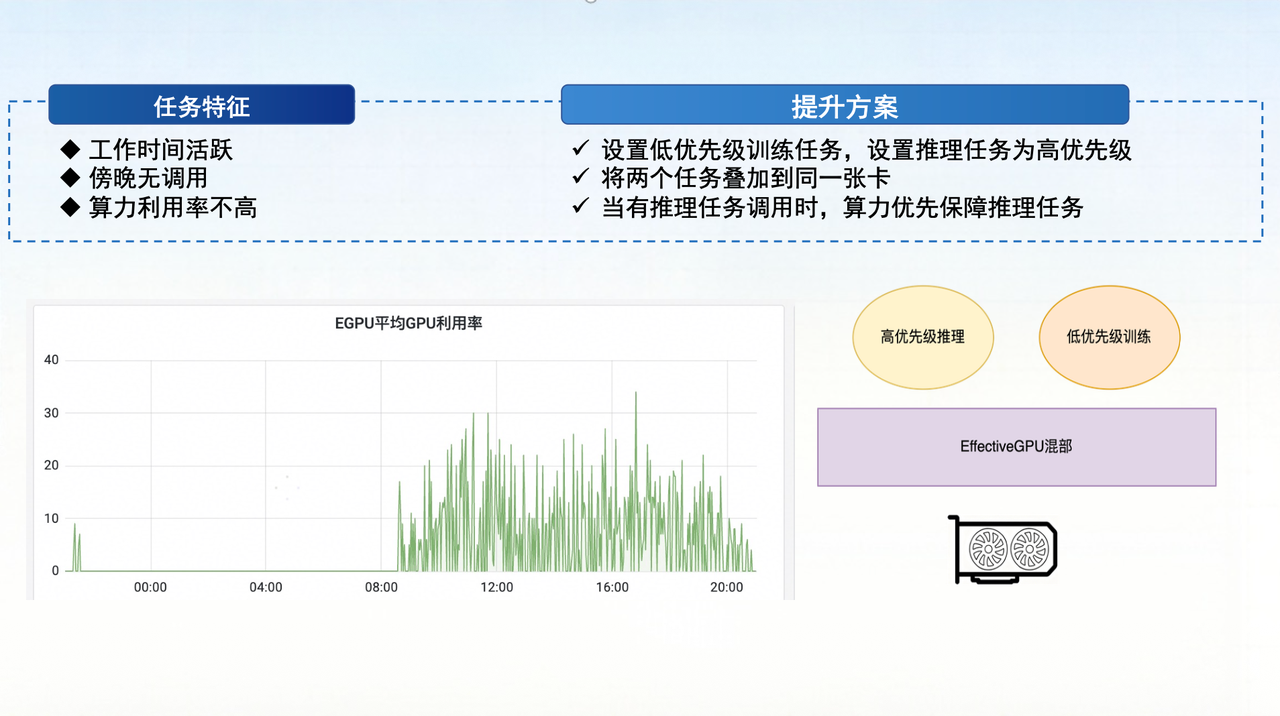
Use Case 2: GPU Colocation (Priority-Based Task Coexistence)
Building on GPU partitioning, development tasks (sandbox/Notebook) are colocated with high-priority inference tasks on the same physical GPU. Through priority scheduling and resource guarantee mechanisms, high-priority task stability is ensured while overall resource utilization improves.
Sandbox and inference tasks have natural temporal staggering — developers tune parameters during the day, inference services scale elastically with business traffic. Scheduling strategies enable resource reuse and dynamic yield.
Use Case 3: Memory Oversubscription
Leveraging task stagger patterns (e.g., customer service scenarios with high concurrency during the day, idle at night), memory oversubscription was implemented, allowing different tasks to share physical GPU memory. Through staggered scheduling, multiple tasks use the same memory space at different times, significantly improving resource utilization.
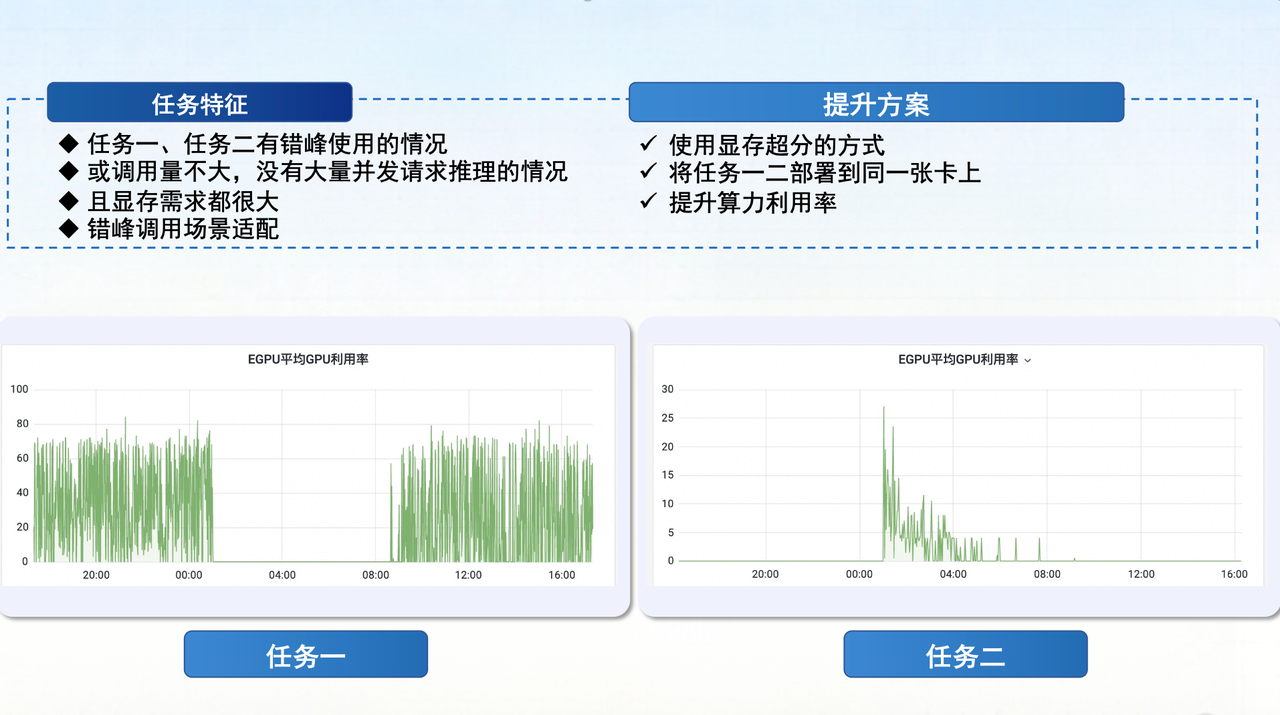
Chen Junchao revealed that the community edition does not yet support memory oversubscription. SF Technology implemented this feature with the help of key community contributors.
IV. Full-Chain Monitoring Loop
The team collects not only physical card monitoring data but also HAMi virtual card memory utilization metrics, writing them to the BDP platform via Prometheus for utilization reporting. This provides data-driven support for resource operation decisions.
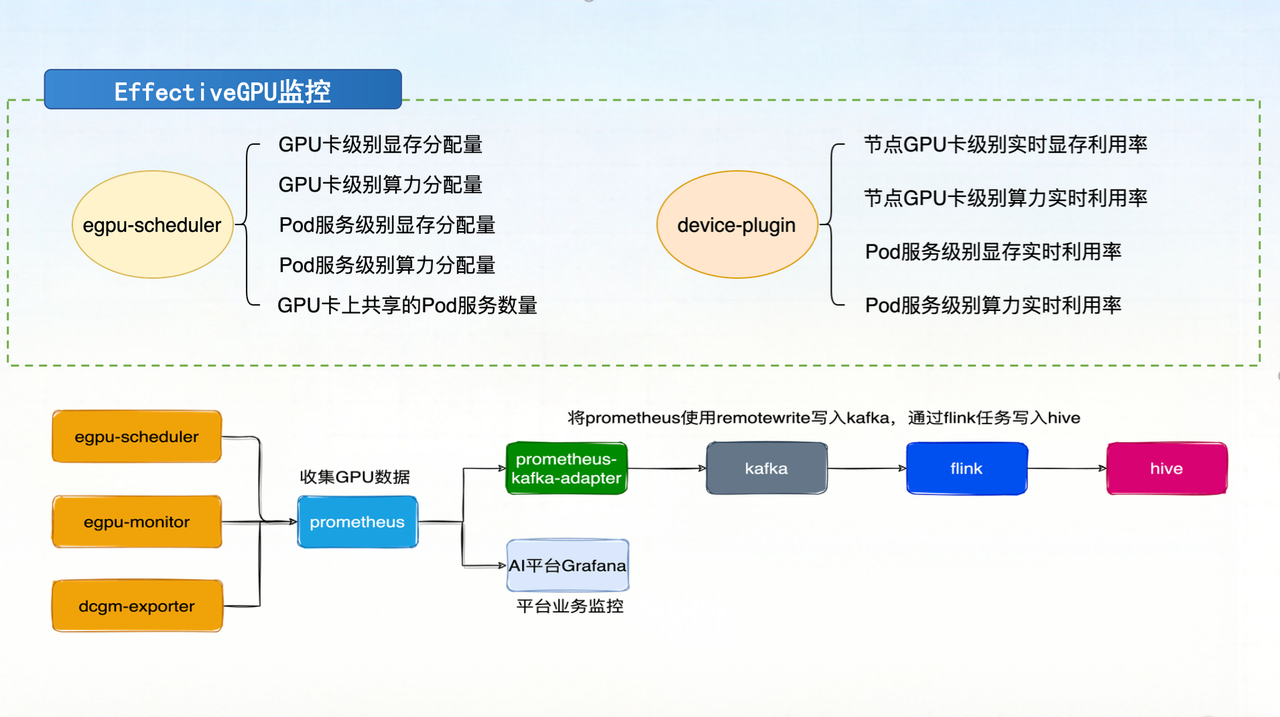
V. Selected Q&A from the Event

Q1: How do low-priority tasks gracefully exit?
Two strategies. First, periodic sandbox utilization monitoring — if continuously idle (e.g., 6-12 hours), automatically commit the image and exit. Second, high-priority task direct preemption — low-priority tasks become blocked (unavailable), with no current degradation plan.
Q2: How do local clusters and public clouds work together?
On-premises data centers primarily run persistent workloads. Compute gaps are supplemented through monthly/annual public cloud resource subscriptions.
VI. Summary
Chen Junchao's presentation provided a complete picture of SF Technology's AI platform evolution from Kubeflow to a multi-cloud hybrid architecture, along with HAMi-based GPU pooling practices. Key takeaways include:
- Architecture: Evolved from a single Kubeflow platform to a multi-cloud hybrid architecture with 5 private clusters + 4 public clouds, with the scheduler fully switched to Volcano, laying the scheduling foundation for GPU pooling.
- Resource Management: Achieved GPU model-level resource reporting through deep customization of the Device Plugin, eliminated the operational burden of labels and taints, and enabled precise scheduling of virtual cards through vGPU Device Plugin adaptation.
- Three Key HAMi Use Cases: GPU partitioning and colocation (development + inference sharing physical cards), memory oversubscription (staggered scheduling for shared memory), and resource pool abstraction with unified scheduling (Volcano queue isolation + gateway traffic distribution).
- Monitoring: Built a full-chain monitoring loop covering physical cards + HAMi virtual cards, writing to the BDP platform via Prometheus for data-driven resource operation decisions.
SF Technology's practices fully demonstrate the production value of HAMi in enterprise GPU pooling scenarios — from scheduler modification and Device Plugin customization to business scenario adaptation, forming a reusable technical path.
VII. Further Reading
Chen Junchao's team at SF Technology previously published the EffectiveGPU Technical White Paper, systematically introducing SF Technology's self-developed GPU pooling technology. This white paper is closely related to the Meetup presentation and serves as an in-depth supplement:
-
EffectiveGPU White Paper: How to Better Improve Compute Efficiency in the LLM Era?
The white paper details the overall architecture and core technologies of the EffectiveGPU (egpu) pooling solution, including heterogeneous device unified management, device sharing and resource isolation (performance overhead controlled within 5%), elastic resource oversubscription (up to 200% memory oversubscription), and priority QoS guarantees.Read more: EffectiveGPU White Paper (Chinese) (Chinese only)
-
CNCF Case Study: SF Technology — Effective GPU
This is SF Technology's official CNCF case study published in English for the global cloud-native community. The case study systematically introduces how EffectiveGPU builds a GPU pooling solution based on the CNCF Sandbox project HAMi, covering device virtualization, hard resource isolation, priority preemption, cross-node cooperative scheduling, and memory oversubscription. Key metrics include: up to 57% GPU savings across production and test clusters, up to 100% utilization improvement from GPU virtualization, and zero intrusion to NVIDIA drivers, Linux kernels, task images, and source code.