Efficiency Over Compute Power: HAMi Meetup Beijing Station Recap

On December 27, "Efficiency Over Compute Power: HAMi Meetup Beijing Station" concluded successfully in Beijing's Haidian District, bringing high-quality exchanges and profound insights, leaving many wonderful moments! As the second stop of HAMi Meetup, the Beijing Station continued to focus on the practical implementation of domestic compute power in real production scenarios and heterogeneous scheduling engineering practices.
Nearly 100 technical partners from various industries and backgrounds gathered to engage in in-depth exchanges around key topics such as heterogeneous compute virtualization, scheduling strategy evolution, and AI business efficiency improvement. The on-site discussions were lively with frequent interactions, and many frontline practical experiences were shared and 沉淀 during the exchanges.
Event Highlights: From "Usable" to "Efficient"
Against the backdrop of rich domestic accelerator types and expanding AI workload scales, the core challenge facing enterprises is no longer "whether compute resources are available," but rather "how to stably and efficiently deliver limited compute power to business through scheduling, virtualization, and platform capabilities."
Focusing on this practical issue, this Beijing Station provided attendees with several clear engineering values:
-
Clarify priorities and boundaries: Through practice comparisons from the community, chip vendors, and business sides, help attendees identify the key engineering issues that truly affect stability and utilization in heterogeneous compute environments.
-
Form reusable paradigms: Systematically present the engineering implementation path for access, virtualization, and scheduling of heterogeneous accelerators in the Kubernetes ecosystem, precipitating sustainable evolution landing paradigms.
-
Evaluate virtualization ROI: Based on large-scale inference and training-inference scenarios, verify the actual improvement effects of virtualization means such as vGPU/vDCU on resource efficiency and delivery capabilities.
-
Establish long-term scheduling abstractions: Combined with the evolution direction of HAMi-Core and DRA, help attendees establish a unified scheduling and resource abstraction perspective for multi-architecture and multi-device scenarios.
-
Output actionable conclusions: Transform "compute efficiency" into observable, evaluable, and sustainable engineering metrics and platform capability goals.
Event Opening: Open Source and Efficiency Are Reshaping AI Infrastructure
At the opening of the conference, Keith Chan, Vice President of the Linux Foundation and CNCF APAC China Chair, shared his recent thoughts: AI development is shifting from the model itself to testing the underlying infrastructure and resource efficiency. High GPU costs and insufficient resource utilization have become global common problems. How to build more elastic and sustainable AI infrastructure through cloud-native and open-source technologies is a topic the entire industry is facing together, and it is also the core value of this project.
Event Core Topics Review
"HAMi New Features and Capability Matrix Standardization"

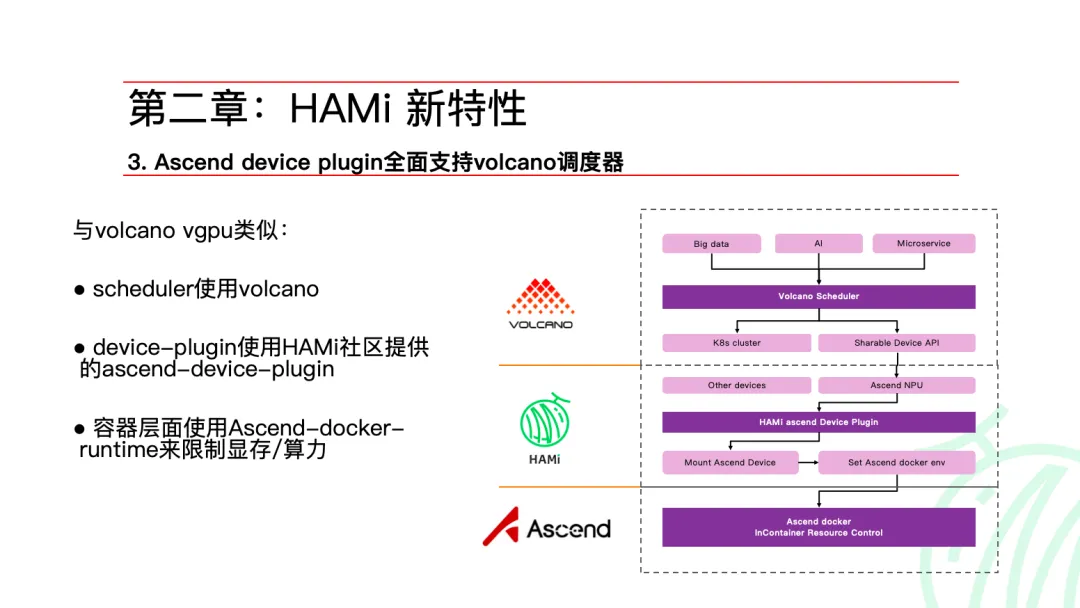
Li Mengxuan, co-founder of Dynamia AI, focused on the technical evolution and community planning of HAMi in the field of heterogeneous compute scheduling. As a CNCF Sandbox project, HAMi has verified its core capabilities such as application non-intrusiveness, strong isolation, and easy deployment in multiple AI accelerator scenarios. In terms of new features, the community introduced CDI support, Mock Device Plugin, and deep adaptation of Ascend Device Plugin with Volcano scheduler, further improving its availability and observability in real production clusters.
Notably, the HAMi community plans to launch a lightweight solution HAMi-DRA in January, which will simplify the complex chain of webhook + scheduler + device-plugin by introducing Kubernetes DRA architecture, achieving seamless integration with existing scheduling frameworks such as Volcano and kai-scheduler. At the same time, focusing on the capability differences gradually emerging in device reuse and heterogeneous compute scenarios, the HAMi community has internally sorted out and formed a capability matrix to evaluate the maturity and support scope of different devices in terms of video memory isolation, computing power control, and scheduling coordination, providing reference for subsequent ecological co-construction and technical evolution. In the future, HAMi will continue to strengthen collaborative co-construction with chip vendors and promote an open, transparent, and sustainable evolution of heterogeneous compute scheduling ecosystem.
"DCU Software Virtualization from Basics to Practice"

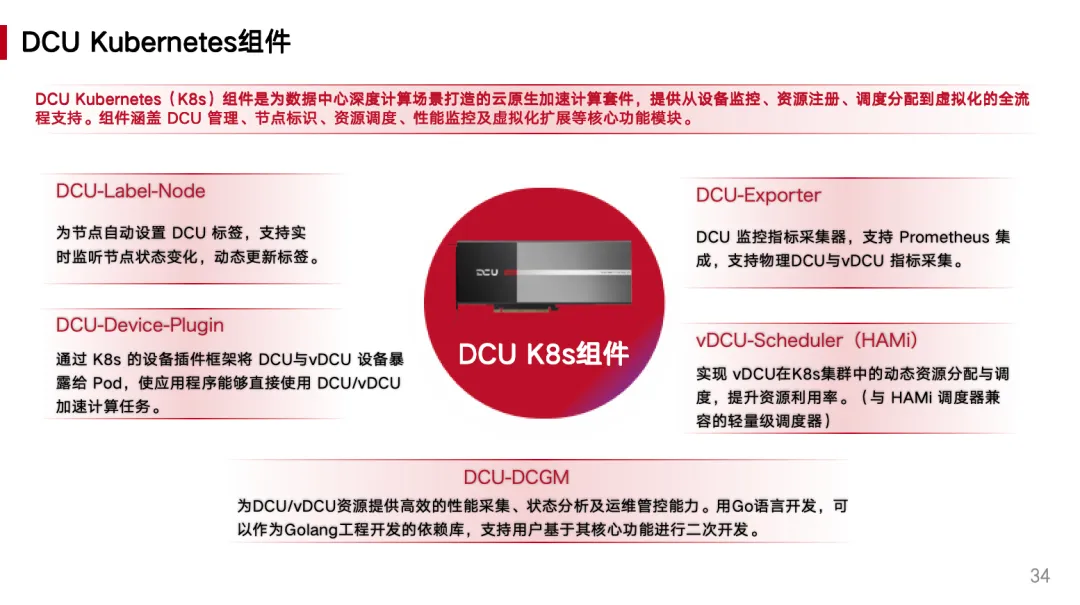
Wang Zhongqin, an R&D engineer from Hygon, systematically reviewed DCU's software virtualization capabilities in cloud-native environments and its complete landing practices in the Kubernetes system. Starting from the DCU driver layer virtualization mechanism, he explained how to achieve fine-grained segmentation and dynamic adjustment of vDCU in computing units and video memory dimensions based on the hy-smi tool, and demonstrated the implementation of vDCU in resource isolation and runtime consistency combined with host and container environment usage examples.
In Kubernetes scenarios, he focused on analyzing the resource registration mechanism with DCU-Device-Plugin as the core, and the overall architecture for achieving vDCU dynamic segmentation and recovery in collaboration with the HAMi scheduler. Through standardized device plugin frameworks and multiple runtime mode support, users can apply for computing power and video memory resources on demand without pre-cutting cards, achieving higher scheduling accuracy and resource utilization. Finally, the sharing introduced the capabilities of the DCU-Exporter component in monitoring physical DCUs and vDCUs, providing basic support for building an observable system for heterogeneous compute.
In terms of planning direction, he also shared the next key points for collaboration with the HAMi community: including supporting a shared mode of "only declaring video memory, computing power sharing," exploring multiple containers sharing the same vDCU, and continuous evolution in resource registration, monitoring metrics, and virtualization forms (such as SR-IOV, Pass-through).
"Bagualu Intelligent Computing Software Stack and Performance Delivery"

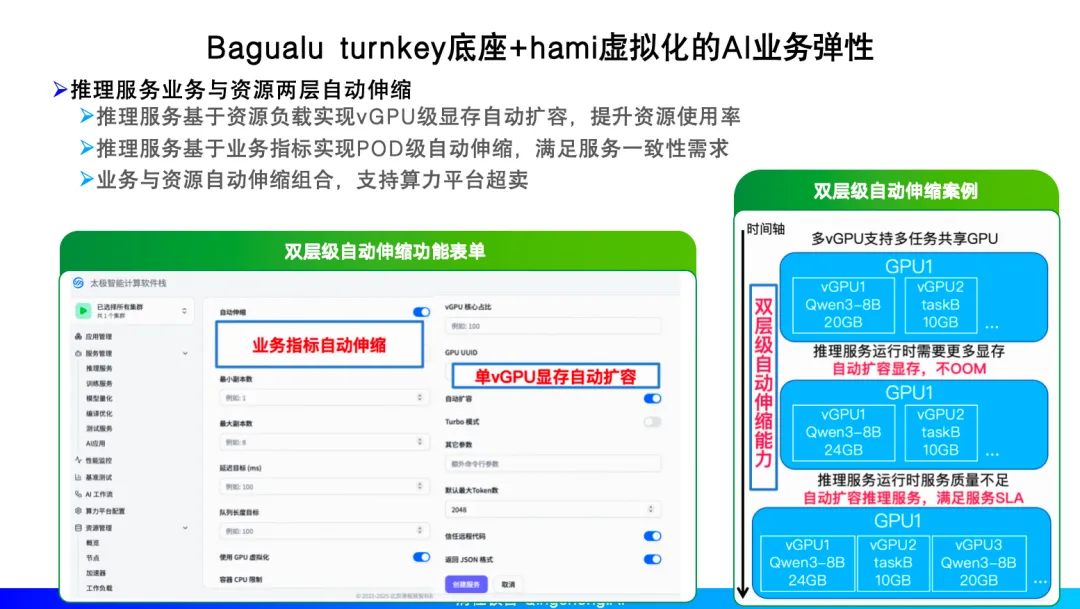
Qingcheng Jizhi Technical Ecology VP and Partner He Wanqing focused on the k types of business × m types of models × n types of AI accelerators combination complexity problem universally existing in domestic large model training and inference scenarios, systematically introducing Qingcheng Jizhi's engineering practices in training and inference software stack optimization and large-scale delivery. The sharing pointed out that in multi-model and multi-chip coexisting environments, relying solely on single-point performance optimization is difficult to support rapid business landing, and a complete software system covering compilation, parallelism, quantization, and inference is urgently needed.
Focusing on the Bagualu multi-layer AI training-inference software stack, he analyzed in detail its key acceleration technologies at the AI compilation, model quantization, parallel training framework, and inference engine levels, and demonstrated the elastic deployment capabilities of Bagualu in the training and inference stages combined with a distributed multi-cloud management platform. On this basis, through collaboration with HAMi GPU virtualization and scheduling capabilities, the Bagualu Turnkey intelligent computing software stack product achieves a dual-elastic model of resource layer vGPU elastic scaling and business workload layer auto-scaling, significantly improving computing power utilization and delivery efficiency without changing business forms, providing a replicable practical path for large model engineering landing in domestic computing power environments.
"Beike × HAMi: Practical Experience of vGPU Inference Cluster"

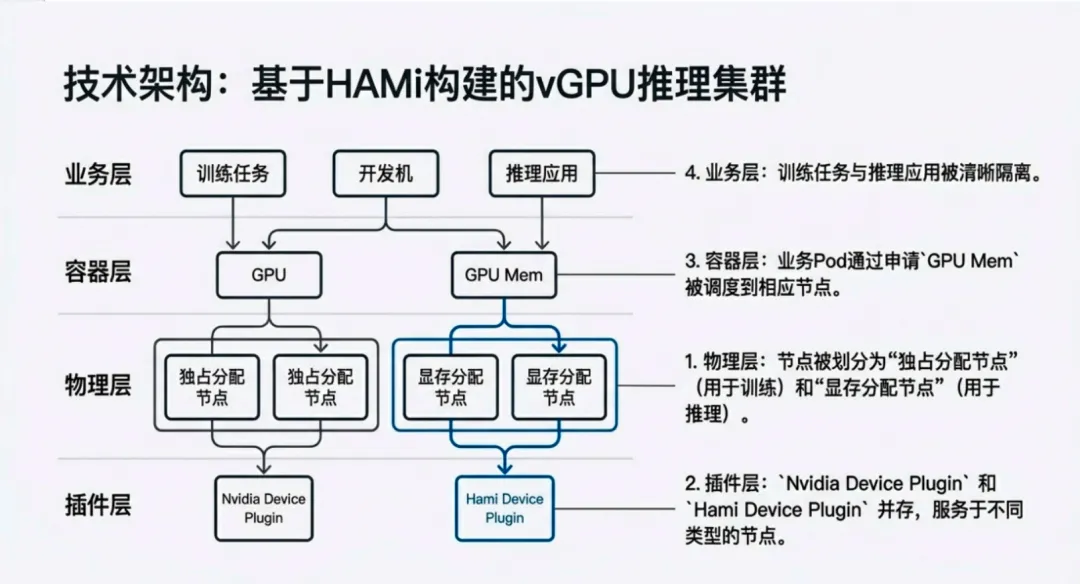
Wang Ni, a computing platform development engineer from Beike, shared HAMi's landing practice in Beike's computing platform, systematically introducing its architecture evolution ideas and key engineering experiences in large-scale GPU management scenarios. The sharing started from Beike's internal inference business actual requirements, analyzing the resource fragmentation and utilization bottlenecks faced by the computing platform under the pressure of multi-model GPU coexistence, multi-cluster unified scheduling, and tens of millions of daily requests.
At the technical implementation level, Beike built vGPU elastic pooling capabilities based on HAMi, providing GPU resources to inference tasks with finer granularity through video memory slicing, enabling TensorFlow inference, small model services, and language models below 32B to run stably on shared GPUs. The video memory limitations and scheduling capabilities provided by HAMi effectively guaranteed resource isolation and stability during multi-task concurrency without transforming application forms. Practical results show that the GPU utilization of the inference cluster based on HAMi achieved approximately three times improvement, providing a replicable reference path for enterprise-level inference platforms in large-scale and low-cost operations.
"HAMi-Core x DRA: Native DRA Driver Practice"


Yang Shouren, an R&D engineer at 4Paradigm & HAMi Approver, shared HAMi's engineering practice under Kubernetes's new generation Dynamic Resource Allocation (DRA) framework, systematically introducing the technical background and implementation path for HAMi-Core's evolution from traditional Device Plugin architecture to native DRA Driver. He pointed out that Device Plugin has natural limitations in container and device information expression and lifecycle management, and HAMi-Core's early capabilities implemented through environment variables and node annotations also gradually exposed maintainability and extensibility issues.
In specific implementation, the sharing deeply analyzed why HAMi-Core DRA Driver chose KEP-5075 (DRA: Consumable Capacity), and how to combine ResourceClaim and ResourceSlice native objects to expose divisible resources such as video memory to the scheduling and runtime system in a standardized manner. By combining CDI mechanism and libvgpu injection capabilities, HAMi-Core achieves a complete closed loop of video memory limitation, resource binding, and runtime cleanup without invading business containers. Finally, the sharing looked forward to HAMi-DRA's planning direction in configuration unification, monitoring enhancement, and heterogeneous device standard attribute alignment, laying the foundation for building a more general heterogeneous compute scheduling framework.
"HAMI Device Plugin New Features Introduction"

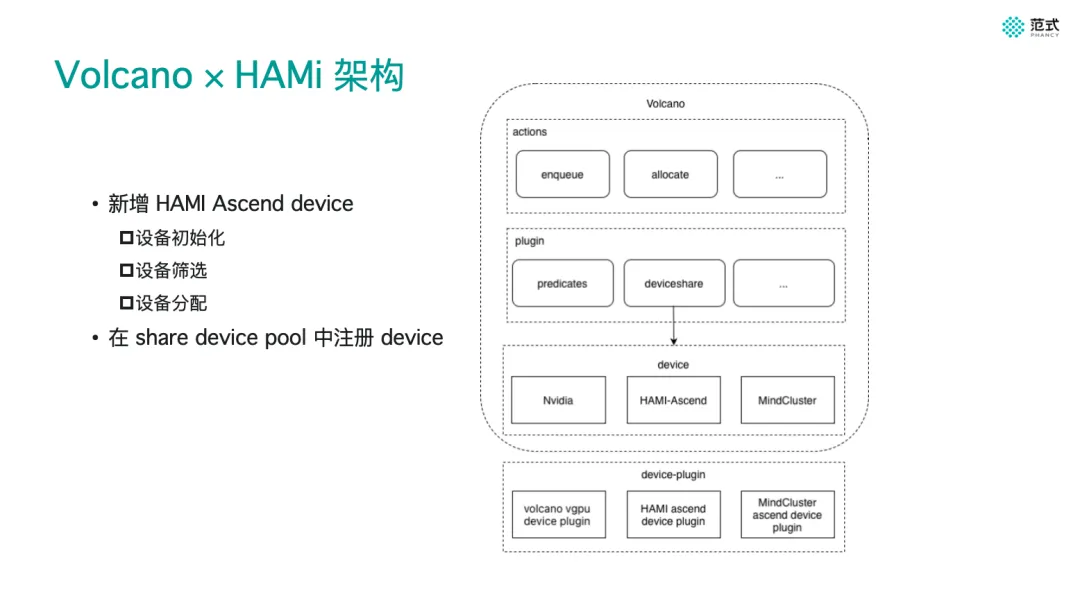
James, a platform engineer at 4Paradigm, focused on the latest functional evolution of the HAMi device plugin, systematically introducing its integration solution with Volcano scheduler in Ascend device scenarios and key engineering improvements. The sharing pointed out that the traditional Kubernetes scheduling model is based on whole-card exclusivity as a premise, and resource abstraction granularity is relatively coarse, making it difficult for heterogeneous devices such as Ascend to be incorporated into a unified, reusable fine-grained scheduling system.
In specific implementation, the sharing focused on analyzing the working mechanism of Ascend Device Plugin in device initialization, filtering, and allocation stages, achieving unified scheduling and on-demand allocation of Ascend devices by Volcano by registering Ascend resources in device-share. At the same time, addressing the problem that device-plugin only registers the number of cards and lacks key resource information such as video memory, the community introduced a Mock Device Plugin solution, automatically completing resource dimensions by parsing node annotations, and standardizing registration of information such as video memory into the Kubernetes resource model. This capability significantly improved resource observability and scheduling accuracy, providing a landing engineering practice for unified management and refined use of heterogeneous devices in multi-scheduler environments.
"HAMi v2.7.0 Accelerating Compatibility with Domestic Compute Power"

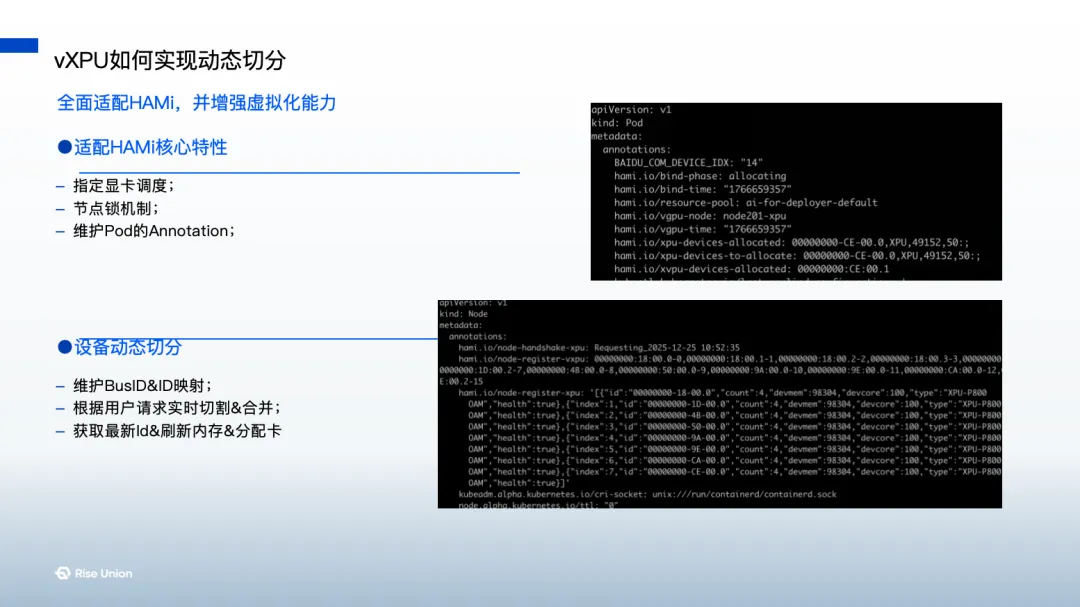
Against the backdrop of continuous accelerated evolution of domestic heterogeneous compute, Ouyang Luwei, an R&D engineer at Ruisi Zhilian & HAMi Reviewer, systematically reviewed Ruisi Zhilian's engineering practice and scheduling capability evolution in Kunlunxin P800 vXPU scenarios. The sharing first started from the XPU-P800 adaptation outline, introducing how to extend virtualization and scheduling capabilities through HAMi based on deep integration of original factory capabilities, achieving vXPU dynamic segmentation and stable delivery.
At the scheduling level, the sharing focused on analyzing the topology awareness capability of HAMi-Scheduler, explaining how to make more reasonable scheduling decisions based on topology information in complex environments with multiple XPUs, multiple nodes, and heterogeneous resource coexistence, to ensure the lowest communication latency and highest application performance. At the same time, addressing the problem location difficulty brought about by the superposition of fine-grained resource segmentation and heterogeneous scheduling, he further introduced improvement ideas for scheduling observability, reducing troubleshooting costs through standardized logs, enriched event information, and visualization means, providing important references for large-scale landing of domestic heterogeneous compute in production environments.
Deep Exchange: Questions Come from the Frontline, Answers Also Come from the Frontline
In the interactive exchange session, the site conducted multiple rounds of discussions around the impacts of GPU/DCU/XPU virtualization, inference and training mixed scheduling strategies, and domestic accelerator adaptation costs. Many attendees continued to exchange details with the speakers after the meeting, discussing how to migrate the experience shared in the sharing to their own business environments.

Conclusion
The Beijing Station HAMi Meetup once again confirmed: Compute efficiency is not a single-point capability, but the result of the joint action of scheduling, virtualization, software stack, and business scenarios.
In the future, Dynamia AI will continue to promote more HAMi real experiences to precipitate, flow, and be reused in practice.
At the next stop, we look forward to seeing you again, and we also welcome more HAMi users and practitioners to share your practice stories and jointly promote the landing of the concept of "efficiency over compute power."