Deep Dive: HAMi Extended ResourceQuota | Precise GPU Resource Quota Management Implementation
In HAMi v2.7.0, the community introduced an extended ResourceQuota mechanism to address the limitations of native Kubernetes ResourceQuota in GPU and heterogeneous computing scenarios. This feature aims to solve two major pain points that native quota management cannot handle: "resource correlation" and "dynamic resources," providing more precise and reliable control capabilities for GPU resource governance in multi-tenant environments.
Building on the feature introduction, this article dives deep into the code implementation, providing a detailed analysis of the specific design and implementation principles of HAMi's extended ResourceQuota.
Core Pain Points: Two Major Limitations of Native ResourceQuota
1. Cannot Understand Resource Correlation
Native ResourceQuota calculates each resource independently and cannot understand their internal relationships. For example, when a Pod requests 2 GPUs with 2000MB memory each (nvidia.com/gpu: 2, nvidia.com/gpumem: 2000), native Quota incorrectly records the total memory requirement as 2000MB instead of the correct 2 * 2000MB = 4000MB. This leads to seriously distorted quota management.
2. Cannot Handle Dynamic Resources
For memory requests specified as percentages (e.g., gpumem-percentage: 50), the actual memory consumption can only be calculated after the scheduling decision is complete (i.e., when the specific physical GPU to be allocated is determined). Native ResourceQuota performs checks before scheduling and cannot handle such dynamic resource values that require "schedule first, deduct later."
Solution: Enhanced ResourceQuota
HAMi's solution does not replace or rewrite native ResourceQuota, but rather builds a lightweight, non-intrusive enhancement layer on top of it in the HAMi scheduler. The core working principle is: the HAMi scheduler monitors standard ResourceQuota objects, and when it discovers resources managed by HAMi with the limits. prefix (e.g., limits.nvidia.com/gpumem), it performs quota checks on these resources within its own scheduling cycle, thereby applying its more refined calculation rules.
Implementation Principles: Deep Code Analysis
HAMi's handling of extended ResourceQuota is divided into two core stages: "Quota Synchronization" and "Scheduling-Time Checks."
1. Stage 1: Quota Synchronization - Listening and Caching
The goal of this stage is to synchronize ResourceQuota objects with the limits. prefix from the K8s cluster into a local cache maintained by the HAMi scheduler itself.
Listening and Recognition
The HAMi scheduler listens to add/delete/update events of ResourceQuota objects in the cluster through the Informer mechanism. When events occur, event handlers like onAddQuota are triggered.
Prefix Filtering and Caching
In the AddQuota function, the code iterates through all resource items defined in the ResourceQuota object's spec.hard. Only resource items with the limits. prefix are recognized and processed. Subsequently, the resource name is stripped of its prefix and, along with its limit value, is stored in a global QuotaManager cache.
The core implementation is located in pkg/device/quota.go:
// File: pkg/device/quota.go
// AddQuota synchronizes extended resources from K8s ResourceQuota objects to local cache
func (q *QuotaManager) AddQuota(quota *corev1.ResourceQuota) {
q.mutex.Lock()
defer q.mutex.Unlock()
for idx, val := range quota.Spec.Hard {
value, ok := val.AsInt64()
if ok {
// 1. Check for "limits." prefix
if !strings.HasPrefix(idx.String(), "limits.") {
continue
}
// 2. Strip prefix to get the real resource name
dn := strings.TrimPrefix(idx.String(), "limits.")
if !IsManagedQuota(dn) { // Check if it's a resource type managed by HAMi
continue
}
// ...
// 3. Write resource and its Limit value to local cache
(*dp)[dn].Limit = value
// ...
}
}
}
2. Stage 2: Scheduling-Time Checks - Iterative Per-Card Verification
This is the core of HAMi's extended ResourceQuota implementation of its intelligent calculation capabilities. When a Pod enters the scheduling process, its quota check is not a one-time "total amount" calculation, but is completed in the device-side Fit() function in a loop-iterative, per-card verification manner, accompanying the process of finding suitable physical cards for the Pod.
The decision flow is illustrated in the following diagram:
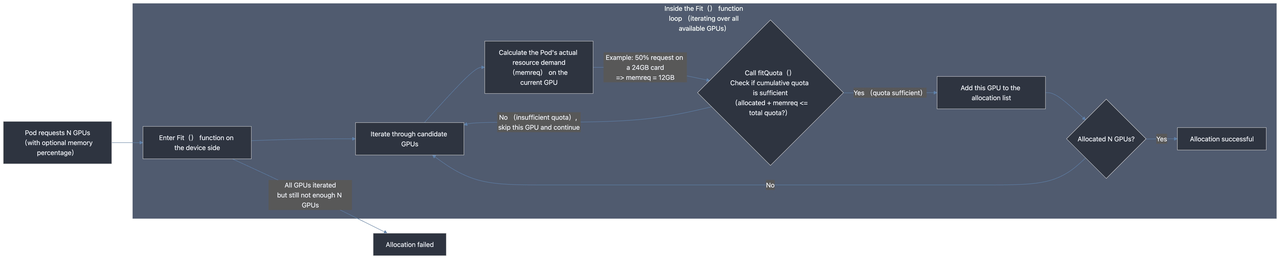
This process solves the two major challenges of "resource correlation" and "dynamic resources" through the following methods:
Dynamic Resource Calculation
Inside the Fit() function's loop, when checking each specific physical card, the code calculates the specific numerical value that the Pod's dynamic resource request (such as percentage-based memory) should be converted to, based on that card's actual hardware specifications (e.g., dev.Totalmem).
Resource Correlation Calculation
The fitQuota function, when checking, considers the sum of cards already selected for allocation within the current Pod (tmpDevs) and the new card being attempted for allocation. This ensures that when a Pod requests multiple devices, its correlated resources (such as total memory) are calculated cumulatively.
The core implementation is located in pkg/device/nvidia/device.go:
// File: pkg/device/nvidia/device.go
// Fit function (simplified logic)
func (nv *NvidiaGPUDevices) Fit(...) (bool, map[string]device.ContainerDevices, string) {
// ...
// Loop through all available GPU devices on the node
for i := len(devices) - 1; i >= 0; i-- {
dev := devices[i]
memreq := int32(0)
// 1. Dynamic resource calculation:
// If percentage-based memory is requested, calculate based on the current dev card's actual total memory
if k.MemPercentagereq != 101 && k.Memreq == 0 {
memreq = dev.Totalmem * k.MemPercentagereq / 100
}
// 2. Correlated resource check (call fitQuota):
// Check if "resources already allocated for this Pod + resources of the current card" exceed quota
if !fitQuota(tmpDevs, pod.Namespace, int64(memreq), int64(k.Coresreq)) {
continue // Insufficient quota, skip this card
}
// ... (other checks) ...
// If checks pass, add this card to the allocation list tmpDevs
tmpDevs[k.Type] = append(tmpDevs[k.Type], ...)
if k.Nums == 0 {
return true, tmpDevs, "" // Satisfied Pod's requested card count, allocation successful
}
}
// ...
}
// fitQuota handles the core quota check logic
func fitQuota(tmpDevs map[string]device.ContainerDevices, ns string, memreq int64, coresreq int64) bool {
mem := memreq
core := coresreq
// Accumulate resources in the allocation list
for _, val := range tmpDevs[NvidiaGPUDevice] {
mem += int64(val.Usedmem)
core += int64(val.Usedcores)
}
// Call QuotaManager's cache for final check
return device.GetLocalCache().FitQuota(ns, mem, core, NvidiaGPUDevice)
}
3. Behavioral Differences and Implementation Notes
It should be noted that HAMi's extended ResourceQuota mechanism has two key differences from native ResourceQuota in terms of implementation and behavior:
Independent Internal State
HAMi's quota calculation (e.g., 2 * 2000MB = 4000MB) and usage statistics are entirely performed in the QuotaManager cache internal to its scheduler, and are not written back to the status field of the native Kubernetes ResourceQuota object. This means that the used field viewed through kubectl describe resourcequota cannot reflect the actual usage of extended resources managed by HAMi.
Scheduling Failure Behavior
When a Pod's resource request exceeds the quota managed by HAMi, its behavior differs from native ResourceQuota. Under the native mechanism, over-quota Pods are directly rejected by the API Server at creation time. Under HAMi's mechanism, the Pod object is successfully created, but is judged as unschedulable by the HAMi scheduler, keeping it in a Pending state until the quota is released or adjusted.
Usage
Users only need to add the limits. prefix to resource names they wish HAMi to manage with fine-grained control in the standard ResourceQuota object.
apiVersion: v1
kind: ResourceQuota
metadata:
name: gpu-quota
namespace: default
spec:
hard:
limits.nvidia.com/gpu: "2"
limits.nvidia.com/gpumem: "4000"
Summary
HAMi's extended ResourceQuota design does not modify the native controller, but extends functionality through independent check logic implemented in the HAMi scheduler. Its core is to calculate dynamic resources and perform cumulative verification for each candidate device when screening physical devices for Pods, solving the problem of native mechanisms being unable to handle dynamic and correlated resources.
References
- User Guide: NVIDIA Extended ResourceQuota Guide
- Related PR: https://github.com/Project-HAMi/HAMi/pull/1359
Once again, sincere thanks to community developer @FouoF for the contribution to this feature!