Open Source Exploration in Compute Virtualization: How to View Flex:ai and Why Engineering Delivery Matters
AI inference and training are rapidly moving toward a new normal of "multi-model co-location and fragmented concurrency." Consequently, compute virtualization is rising from "local engineering optimization" to become a critical capability of AI infrastructure: it must not only partition resources, but also schedule, govern, and operate stably over the long term.
The recent open source project Flex:ai has attracted significant attention. We believe such exploration deserves serious consideration: more participants entering this field indicates that industry consensus is forming and requirements are becoming clearer. At the same time, there's a long-standing principle in the infrastructure domain—users don't pay for concepts, but for verifiable, reproducible, and operable engineering delivery.
Based on public repositories and community-visible information, this article discusses three questions from an engineering perspective:
-
What are the current "verifiable" delivery boundaries;
-
What typically separates "working demos" from "dependable infrastructure";
-
What actionable engineering facts we believe industry discussions should return to.
This article discusses 'verifiable delivery boundaries' based solely on public code and reproducible practices, without targeting any vendor strategy or commercial judgment.
From Public Repositories: Where Are the Current "Verifiable" Delivery Boundaries?
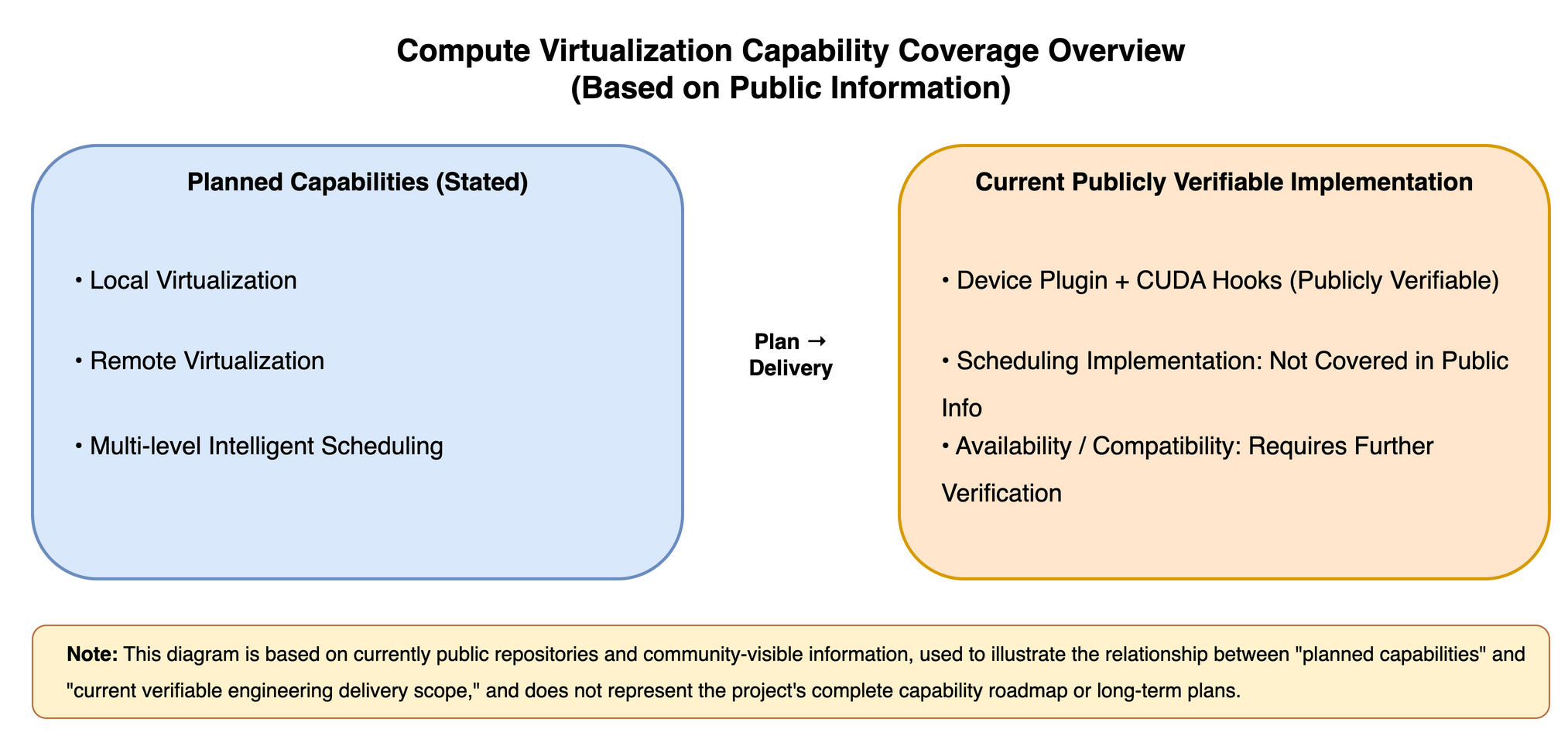
From the current public scope, Flex:ai's open source implementation primarily focuses on two areas:
-
Virtualization-related device-plugin (GPU side)
-
Runtime interception / CUDA hijacking (hooks)
In other words, it currently focuses more on the "resource exposure and in-container limit/isolation" layer—this is a critical component in the compute virtualization technology stack, but typically only part of the full-stack closed loop.
At the same time, from externally visible information:
-
Scheduling strategy level: Currently lacks auditable open source implementation and reproducible results support (at least at the public repository level, it's difficult to form a complete closed loop).
-
Cross-node/remote-related capabilities: If included as part of the external narrative, these still need to be fulfilled at the code and reproducible experiment level.
-
NPU-related: Currently presented more in binary (so) form, making auditability and verifiability relatively limited for the community, with specific capabilities more dependent on subsequent feedback and verification.
These judgments are not value assessments of any team, but factual descriptions of "current public delivery boundaries": the prerequisite for open source projects to be trusted is clear capability boundaries and reproducible evidence chains.

The maturity of infrastructure projects typically depends on whether the upper-layer closed loop (scheduling, observability, governance) is reproducible and operable.
From a principled perspective, the engineering value of compute virtualization doesn't come from a single interception point or plugin itself, but from the end-to-end maintenance of "device semantics and resource commitments": the same compute and memory quota must hold consistently across different drivers, runtimes, and concurrent loads. This creates a natural gap between the commonly seen "open source visible parts" and "engineering-dependable capabilities" in the industry, as the latter often relies on the system closed loop formed by scheduling, governance, and runtime coordination, making it difficult to verify directly through scattered code.
From "Concept" to "Dependable": Common Engineering Gaps in Infrastructure Projects
In the infrastructure domain, there's often an engineering chasm between "can be implemented" and "can be depended upon." Based on currently available information, we see three typical gaps (directions any project must fill to reach maturity):
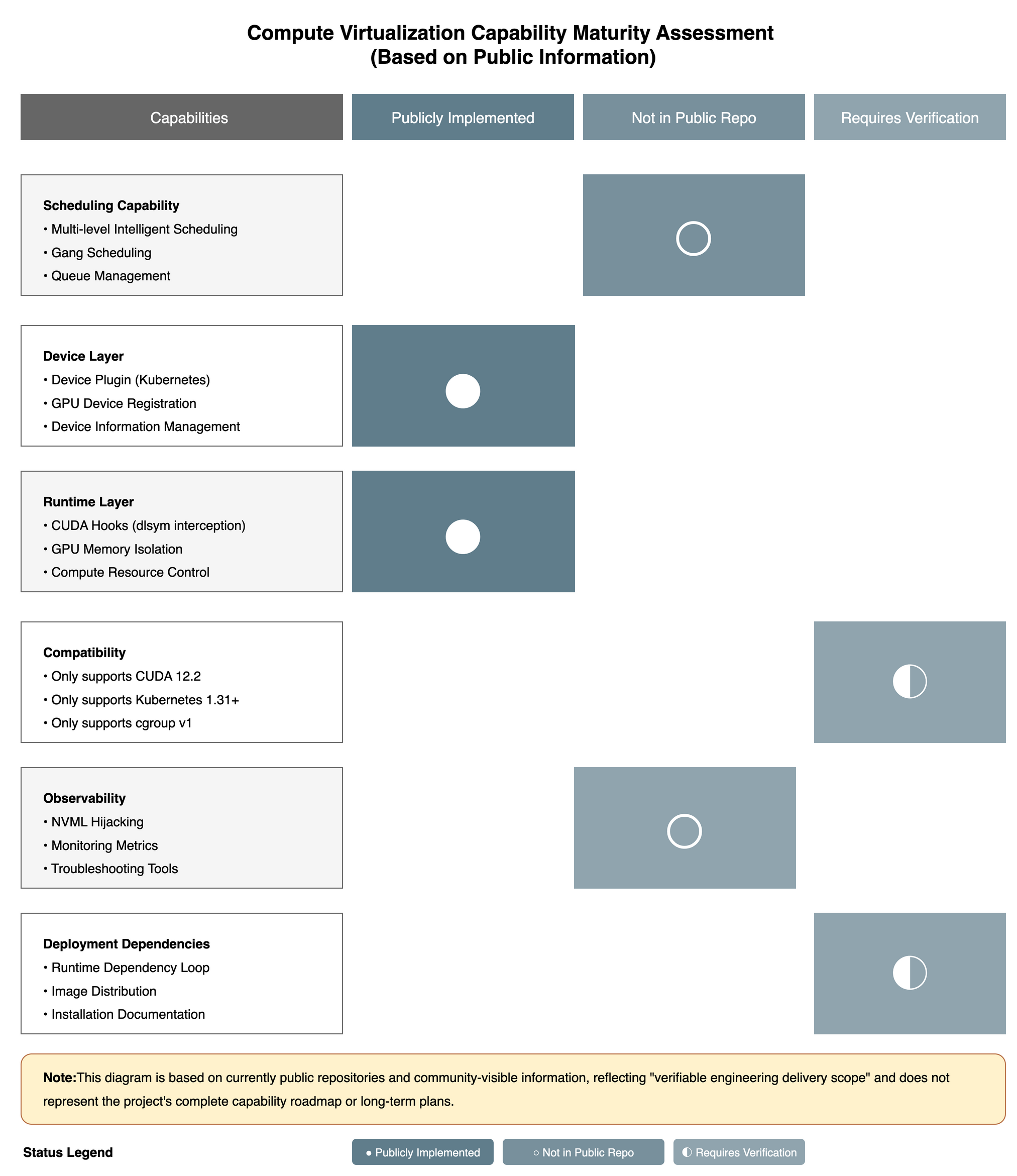
Scheduling: If Emphasizing "Intelligent Scheduling," You Need Auditable, Reproducible Delivery
Scheduling is not a slogan; it requires at least three types of evidence chains:
-
Strategy implementation is auditable (even if it's a minimum viable strategy)
-
Results are reproducible (benchmarks, stress tests, comparison methods are public)
-
Boundaries are explainable (what scenarios work, what scenarios make no commitments)
Without these, external users find it difficult to form reliable expectations, and it's also difficult to precipitate transferable practices at the community level.
Compatibility: Tighter Constraints Mean Higher Adoption Barriers
In currently visible information, there are certain environmental constraints (such as CUDA/Kubernetes/cgroup requirements). Such constraints are not "wrong," but they directly determine the cost curve from "trial to production":
-
More constraints make PoC harder to scale;
-
Clearer compatibility matrices make users more confident to use and expand.
Observability: Without Closed Loop, Partitioning is Hard to Transform into Governance
In production environments, the real value of virtualization capabilities usually comes from "governability":
-
Are quotas and actual usage observable
-
Are jitter and contention explainable
-
Is resource efficiency quantifiable
-
Are faults and troubleshooting systematic
If these closed loops are incomplete, solutions often remain at "can partition" and struggle to enter the "governable, operable, scalable" stage.
A Community-Visible Small Example: Dependency Closed Loops Often Determine "Whether It Can Run"
Community issue has already reported users encountering runtime blocking due to missing dynamic library dependencies in certain environments (e.g., missing libacl_server.so causing loading failures). Such problems usually point not to "compute capability itself," but whether the delivery closed loop is self-consistent:
-
How dependencies are distributed with images or installation packages
-
Whether deployment manifests are complete
-
Whether common errors are solidified into troubleshooting manuals and toolchains
For infrastructure projects, these "seemingly detailed" engineering details are often the adoption threshold.
Conclusion: Return Discussions to Engineering Facts, Let Standards Precipitate in Practice
The value of open source lies in collaboration and co-evolution. It's normal for different teams to be at different stages and choose different paths; what's truly important is that industry discussions always advance around verifiable delivery and engineering facts: clear capability boundaries, reproducible evidence chains, and dependable operation closed loops.
Dynamia and the HAMi community will continue focusing on advancing compute virtualization from "partitionable" to "governable," and promoting the formation of interoperable, sustainably evolving de facto standards through open collaboration.
Discussions are welcome to be conducted publicly; engineering welcomes working together to truly solve complex problems; standards also welcome being advanced together based on practice and evidence.