DaoCloud: Building a More Flexible GPU Cloud Platform with HAMi
Against the backdrop of sustained growth in AI training and inference demand, how to improve GPU utilization, reduce compute costs, and simultaneously accommodate diverse business scenarios has become a core challenge facing cloud platforms.
「DaoCloud」 addresses this issue by using CNCF Sandbox open-source project HAMi in its public and private GPU cloud platforms to build a more flexible, cloud-native GPU resource management approach. Based on DaoCloud's practical experience in real production environments, this article outlines its overall approach, landing process, and actual results in introducing HAMi during GPU cloud platform construction.
Company and Product Background: GPU Platform with Parallel Public and Private Cloud
DaoCloud operates two core product lines for different types of users, both carrying large amounts of AI training and inference workloads.
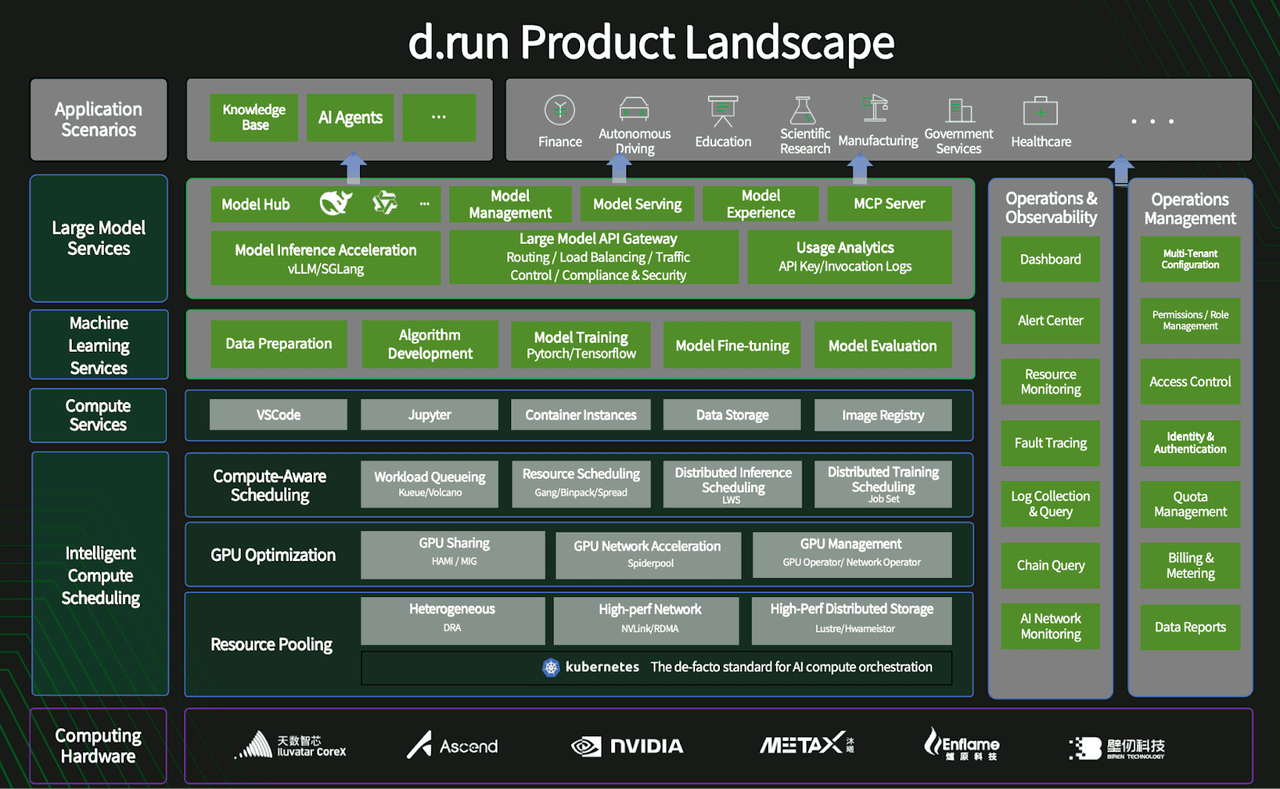
Compute Cloud (d.run) is DaoCloud's public GPU cloud service for individual developers and small and micro enterprises. Users can purchase GPU computing power on demand for AI training and inference. To meet self-service purchase and fast delivery needs, Compute Cloud adopts a relatively lightweight permission model and provides computing resources through a unified SKU system.
DaoCloud Enterprise (DCE) is a private cloud container platform for enterprise customers. After enterprises purchase and deploy GPU resources in their own environments, they need a unified platform to manage and allocate this computing power. DCE is built based on a standardized Kubernetes platform, supporting multi-tenant isolation, department and queue-level quota management, and combined with a role permission system, providing a unified computing resource pool and algorithm development platform for internal AI training and inference.
Engineering Background: Dual Challenges of GPU Utilization and Management Complexity
Before introducing HAMi, DaoCloud faced a series of common problems in the actual operation of its GPU cloud platform.
In the compute cloud scenario, GPUs are mainly allocated as whole cards. Inference and lightweight tasks often only use part of the GPU's computing power and video memory, resulting in low overall resource utilization and limiting flexible GPU SKU design.
In the enterprise private cloud (DCE) scenario, GPU resources need to be shared among multiple departments, projects, and queues. How to achieve unified scheduling and efficient use while ensuring isolation and quota constraints poses higher requirements for the platform.
In addition, as the platform gradually introduces different models of NVIDIA GPUs and domestic GPUs, accelerator types are becoming increasingly diverse, and the complexity of unified management and scheduling of heterogeneous hardware continues to increase.
Why Choose HAMi: Cloud-Native, Vendor-Agnostic GPU Abstraction Layer
When building the GPU training platform, DaoCloud started from the problems users truly care about:
-
Whether training tasks are stable and performance is predictable
-
Whether code needs to be changed when switching GPUs or clusters
-
Whether the platform can provide clear explanations when performance issues occur
Around these requirements, the platform needs a GPU abstraction layer that shields hardware differences from above while maintaining sufficient transparency from below.
HAMi provides a vendor-agnostic GPU abstraction method that enables the same set of training tasks to maintain consistent user experience in both NVIDIA and domestic GPU environments, avoiding users being bound by underlying hardware and authorization models, thereby significantly reducing migration and expansion costs.
At the same time, HAMi's cloud-native design enables GPUs to integrate into the Kubernetes scheduling system like CPUs and memory.
For users, this means:
-
No need to understand GPU virtualization details
-
More consistent training behavior across different scales and nodes
-
Platform upgrades won't break existing training workflows
Solution: Actual Landing of HAMi in DaoCloud Platform
In Compute Cloud (d.run), DaoCloud integrates HAMi into each region's Kubernetes cluster to achieve GPU vGPU segmentation and controlled over-allocation. Physical GPUs are divided into vGPU resources of different specifications and provided through a unified SKU system. Users can choose appropriate computing specifications according to actual needs without paying for whole-card GPUs.
In DaoCloud Enterprise (DCE), HAMi serves as a unified GPU abstraction layer, integrating scattered GPU resources within the enterprise into a shared computing pool. vGPU resources are deeply integrated with the platform's existing quota system and RBAC permission model to achieve department and queue-level GPU quota control, while shielding underlying hardware differences from algorithm engineers to simplify the user experience.
During the actual landing process, DaoCloud continuously feeds back GPU over-allocation, scheduling boundaries, and heterogeneous hardware adaptation problems exposed in real production environments to the community, and promotes the continuous evolution of HAMi's related capabilities through code and practical verification.
Data and Quantified Results: Higher Utilization and Lower Costs
Currently, d.run has deployed 7 active regions in mainland China and Hong Kong, covering 10+ data centers.
After introducing HAMi, through vGPU segmentation and controlled over-allocation mechanisms, GPU resource usage efficiency has been significantly improved. Combining the overall practical experience of Compute Cloud (d.run) and Enterprise Private Cloud (DCE):
-
Average GPU utilization increased to over 80%;
-
GPU-related comprehensive operating costs reduced by approximately 20%–30%;
-
HAMi's modular and cloud-native architecture significantly shortened delivery cycles for new regions and clusters, and the definition and launch process of GPU SKUs is more standardized.
There are certain differences in specific improvement ranges under different regional scales and load structures. From an engineering operation perspective, in most production scenarios, the platform can achieve stable GPU utilization levels of 70%–80% or above, and as the proportion of inference and lightweight tasks increases, cost optimization effects further appear.
Recent Updates
At the recent HAMi Meetup Shanghai Station, DaoCloud Product Head Lu Chuanjia shared:
"In the SaaS GPU cloud scenario, the biggest challenge is not just 'using GPUs,' but how to continuously release the value of each card under high volatility and high concurrency. The vGPU slicing, computing power ratio, and scheduling capabilities provided by HAMi allow us to truly pool and finely operate GPUs in a cloud-native way.
For d.run, HAMi is not just a scheduling component, but one of the foundational capabilities that enables the compute cloud to operate at scale. It allows us to achieve higher resource reuse rates while guaranteeing SLA, and also provides sufficient flexibility for platform expansion across multiple regions and hardware types."