How China Merchants Bank Built a Heterogeneous Compute Infrastructure with HAMi: 100% GPU Pooling Rate, 30% Reduction in Cross-Node Scheduling
The HAMi Community Meetup Shenzhen, organized by the HAMi community and hosted by Dynamia AI, concluded successfully on April 25, 2026. This is the fourth article in the Shenzhen Meetup recap series. Su Xi from China Merchants Bank shared an in-depth look at building a heterogeneous compute infrastructure for the financial industry, focusing on super-node hardware adaptation, vNPU-Core software partitioning, and network topology-aware scheduling algorithms.
Key Highlights:
- Super-node dual-chip module adaptation achieving 100% GPU pooling rate, eliminating cross-module driver failures
- vNPU-Core software partitioning: fine-grained allocation at 1 GB VRAM / 1% compute level
- Three-tier topology-aware scheduling reducing cross-node scheduling probability by 30%
- Deterministic hashing to prevent concurrent task scattering, significantly reducing task fragmentation
- Solutions contributed back to the HAMi open-source community, evolving from "usable" to "efficiently usable"
Speaker: Su Xi (R&D Engineer, China Merchants Bank)

Video Recording & Slides
- Bilibili: Heterogeneous AI Compute Scheduling Optimization with HAMi - Su Xi
- Download Slides: GitHub
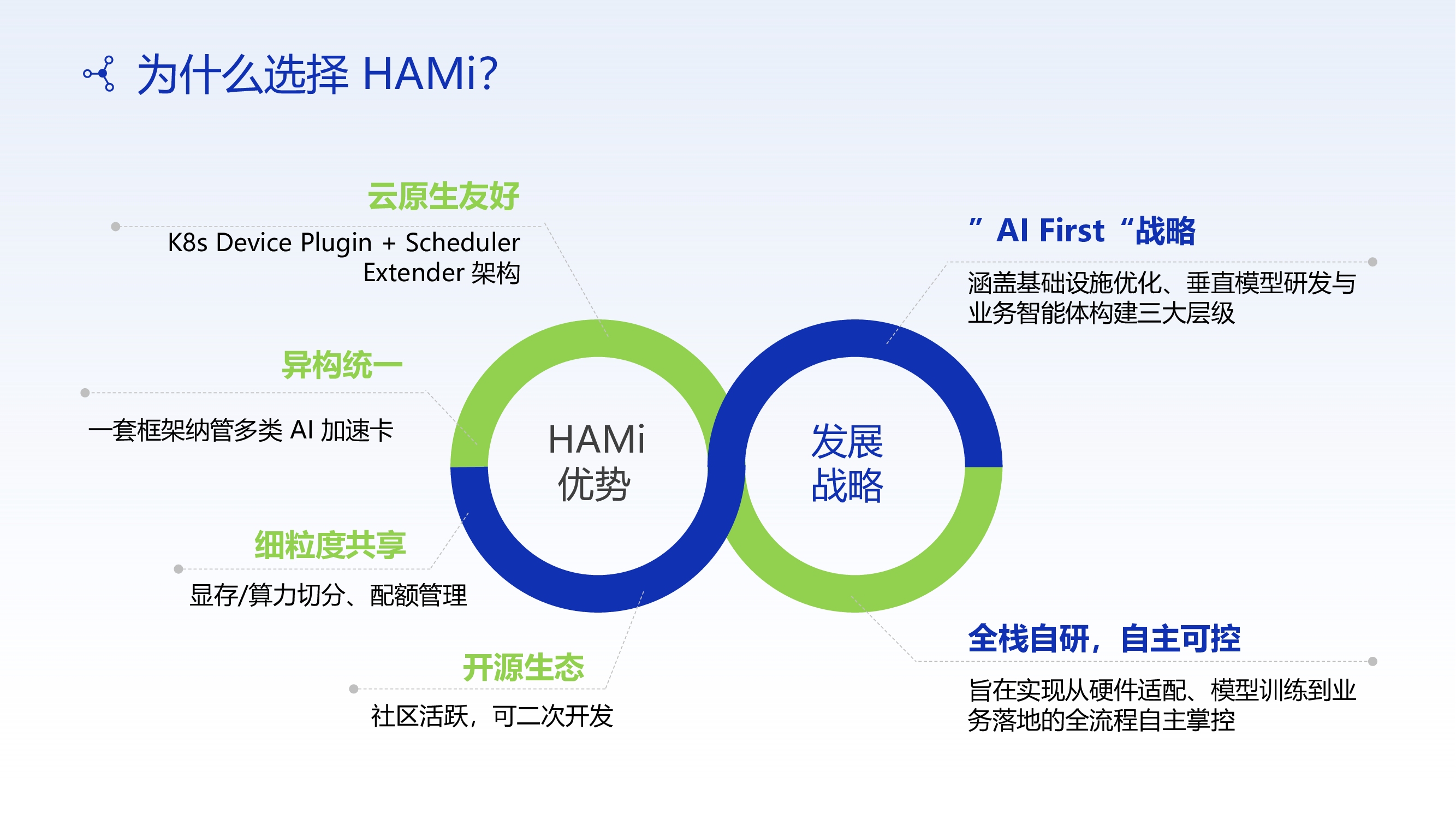
1. The Unique Challenges of Heterogeneous Compute in Financial Services
China Merchants Bank's core challenge is compute pool diversification:
- Multiple GPU/NPU models coexist, leading to severe resource fragmentation
- Different business lines (risk management, customer service, investment research) have vastly different compute requirements
- Financial workloads demand the highest levels of stability and security isolation
- Operational costs escalate rapidly as heterogeneous infrastructure scales
Based on HAMi, CMB built a unified heterogeneous compute infrastructure, enabling unified management and scheduling optimization across multiple chip types.
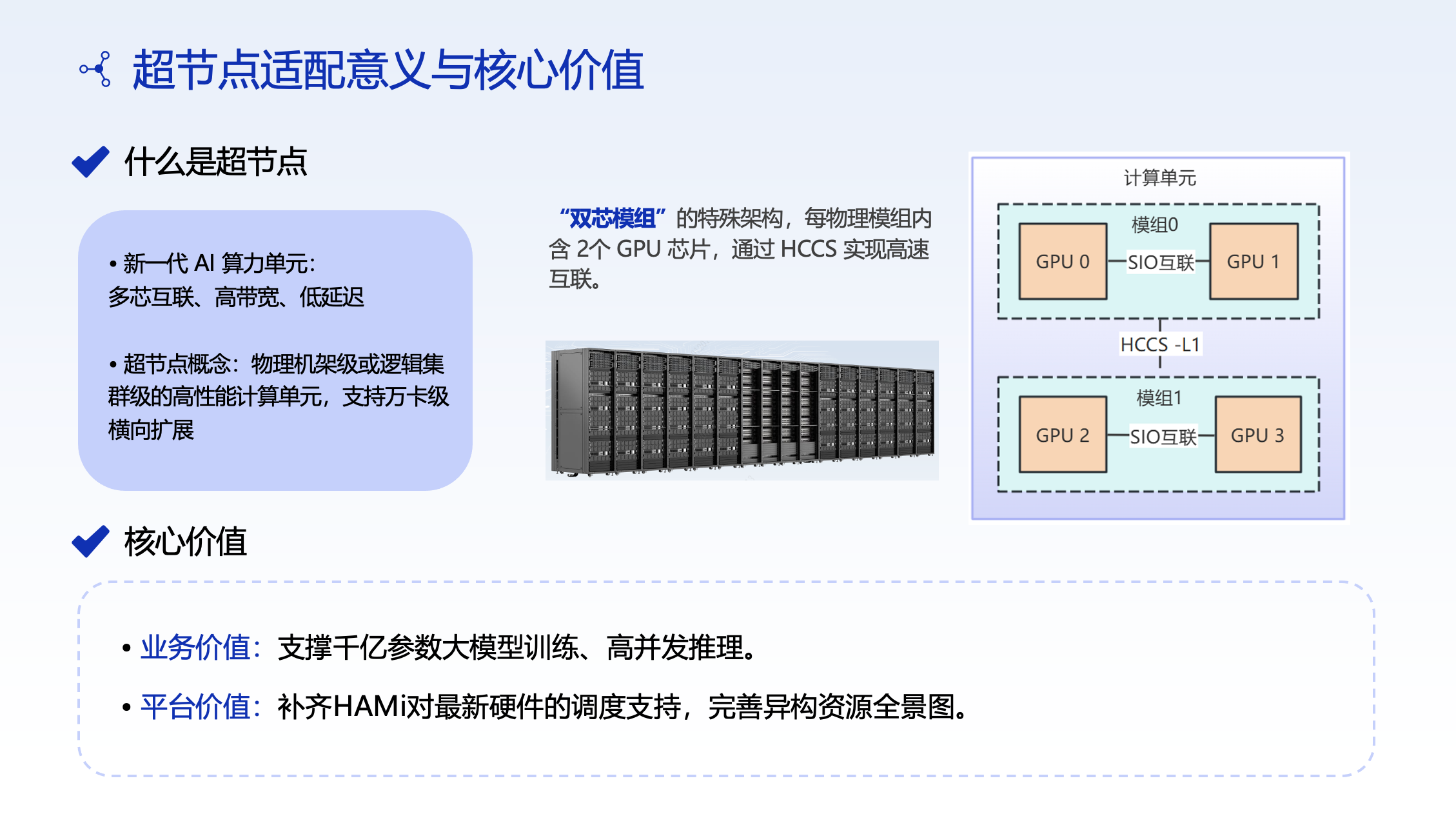
2. Super-Node Hardware Adaptation: The Dual-Chip Module Challenge
What Is a Super-Node?
A super-node is a hardware architecture that combines multiple chips into a single logical unit through high-speed interconnects. CMB adopted a Dual-Chip Module (DCM) architecture, where each module contains multiple compute cards interconnected via a high-speed bus.
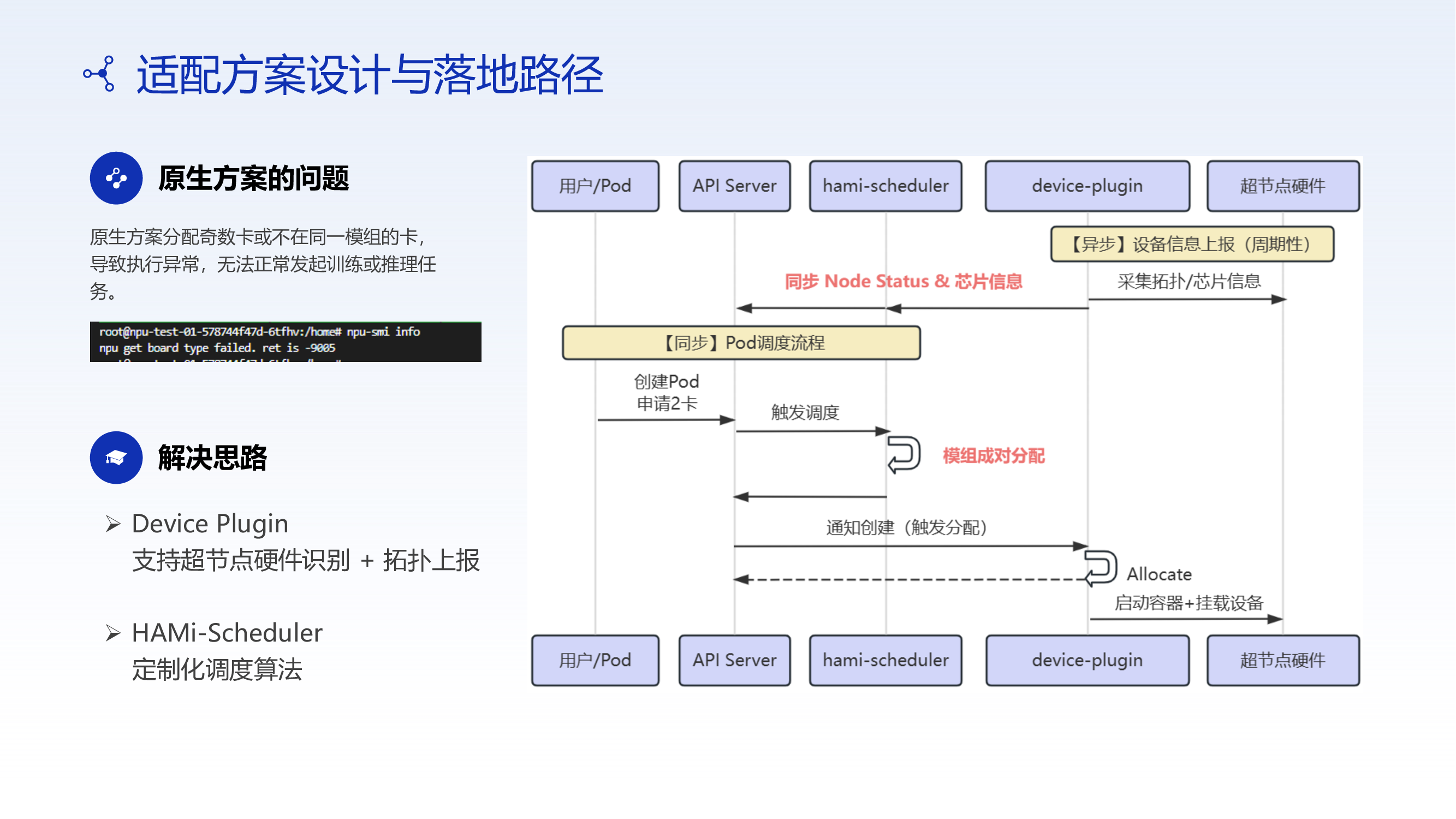
Problems with the Native Approach
When using the native Kubernetes scheduler, the super-node architecture exposed serious issues:
- Odd-card allocation: Allocating an odd number of cards could span two modules, causing driver failures
- Cross-module communication: Communication latency across modules is significantly higher than within-module communication
- Low hardware pooling rate: Due to misaligned allocation, some hardware cannot be used normally
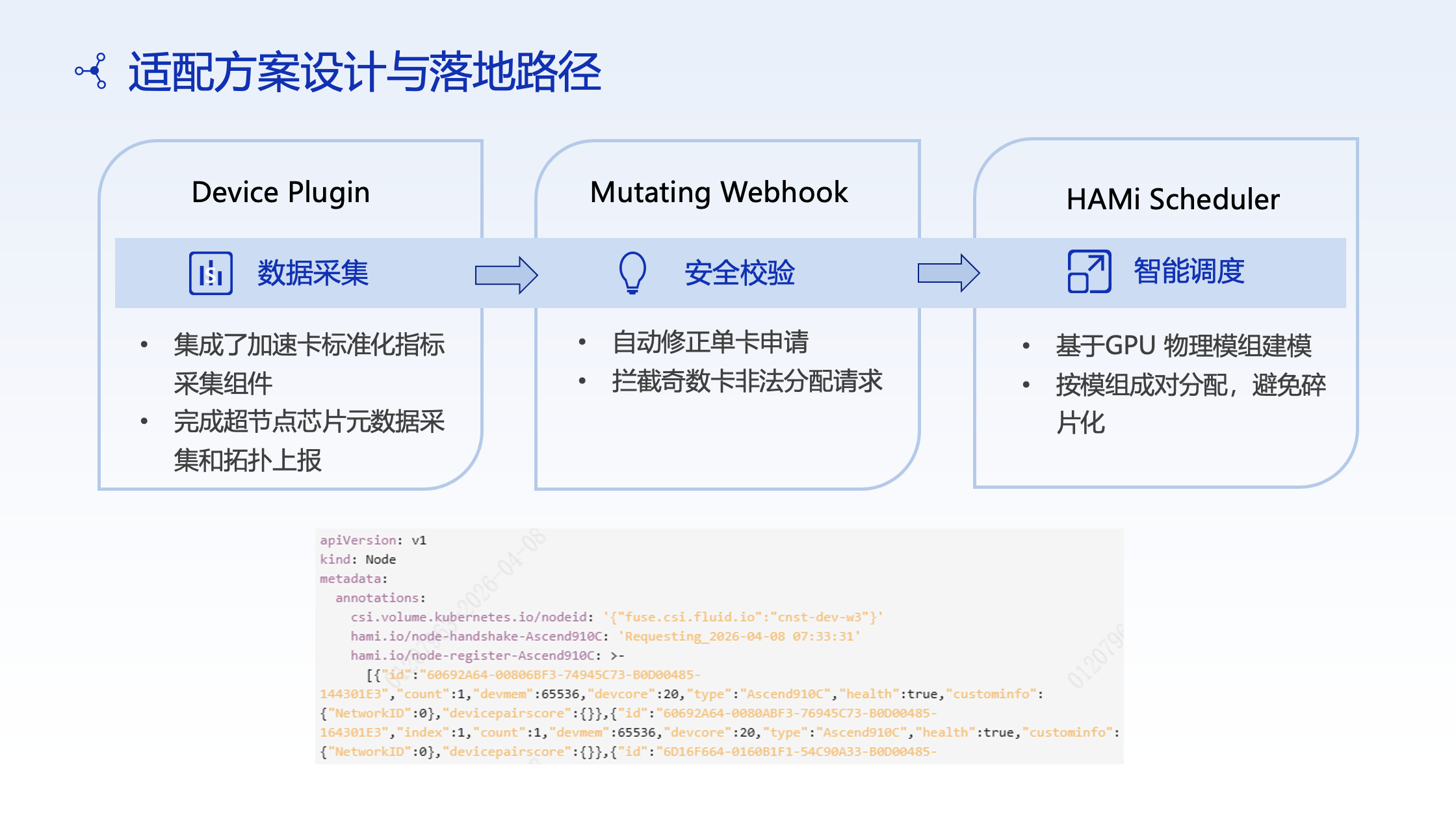
The HAMi Solution
By enhancing the Device Plugin and scheduler, CMB achieved physical module identification and paired allocation:
- The scheduler is aware of module topology, ensuring cards are allocated within the same module
- Driver failures caused by odd-card cross-module allocation are eliminated
- Hardware pooling rate increased to 100%
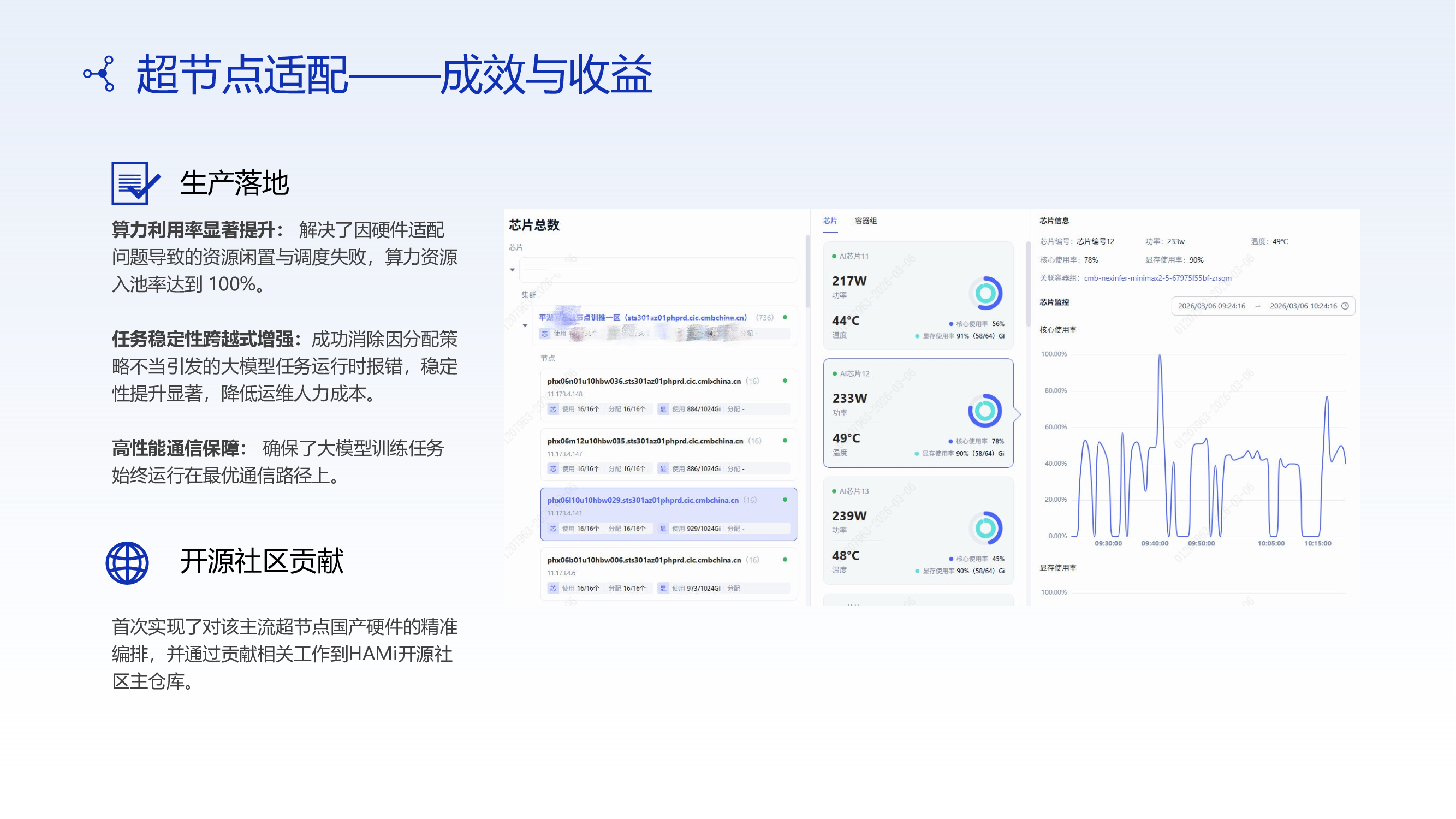
Results and Benefits
Production Deployment
Under the dual-chip module architecture, the native Kubernetes scheduler lacks awareness of GPU physical topology, causing resource allocation to be mismatched with actual hardware structure. The HAMi-based super-node adaptation solution introduces module-level awareness and scheduling constraints, transitioning from "logical resource allocation" to "physical consistency scheduling."
Core results include:
- Significantly improved compute utilization
Through module-aligned allocation strategies, cross-module resource fragmentation and unusable resource remnants are eliminated. The overall GPU pooling rate reached 100%, effectively releasing dormant compute capacity. - Greatly enhanced task stability
Driver failures and training crashes caused by odd-card cross-module allocation are eliminated. The success rate and stability of large-scale training tasks improved significantly, reducing manual intervention and operational costs. - Communication efficiency optimization (a key implicit benefit)
Scheduling policies ensure tasks run within the same module or on optimal topology paths whenever possible, reducing bandwidth contention and latency amplification from cross-module communication, providing a more stable performance foundation for distributed training.
Open-Source Community Contributions
This solution was not only validated in CMB's production environment but also contributed back to the HAMi open-source community as reusable capabilities:
- First implementation of fine-grained scheduling for domestic AI accelerator cards under a "super-node architecture"
- Established a module-aware scheduling model (Topology-aware Scheduling Primitive)
- Advanced heterogeneous compute from "usable" to "efficiently usable"
3. vNPU-Core Software Partitioning: Fine-Grained Splitting at 1 GB VRAM / 1% Compute

For small and medium model fine-tuning and inference tasks, CMB leveraged HAMi's VNPU Core component to achieve compute partitioning at the software level.
Technical Principles
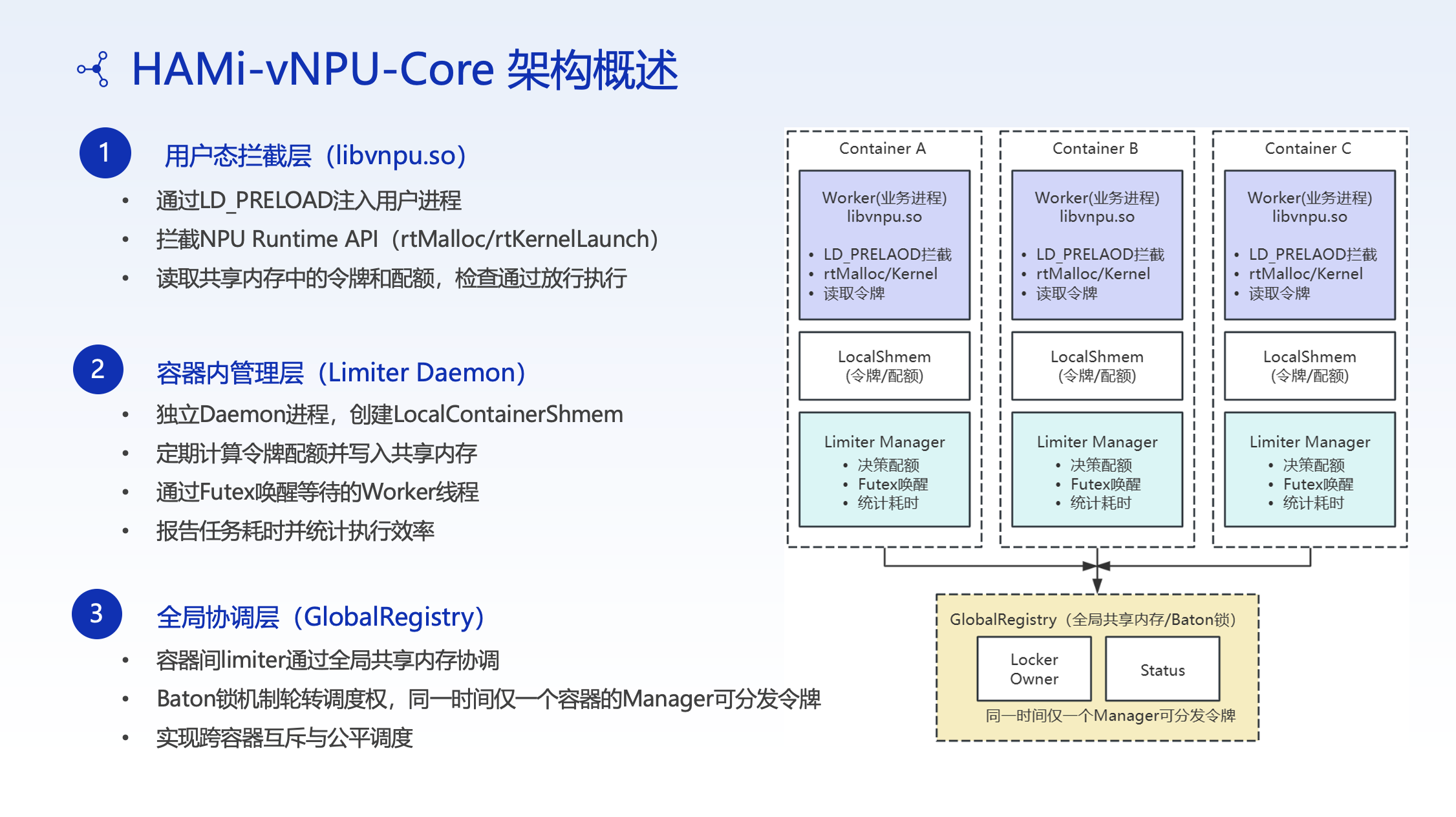
By intercepting operator APIs in user space and using a token bucket mechanism with shared memory, compute resources are proportionally allocated:
- Token bucket mechanism: Controls the compute usage quota per task; tasks exceeding their limit queue and wait
- Shared memory: Manages VRAM allocation in user space, enabling fine-grained memory partitioning
Partitioning Granularity
- Supports a minimum of 1 GB VRAM per partition
- Supports a minimum of 1% compute per partition
- Flexible combinations based on task requirements
This capability is particularly important for banking scenarios: many risk management and customer service models have modest parameter scales that don't require a full GPU card. Fine-grained partitioning significantly improves resource utilization.
4. Network Topology-Aware Scheduling Algorithm
This is the most technically deep section of the presentation. CMB designed a multi-level topology-aware scheduling algorithm specifically to optimize communication efficiency for distributed training tasks.
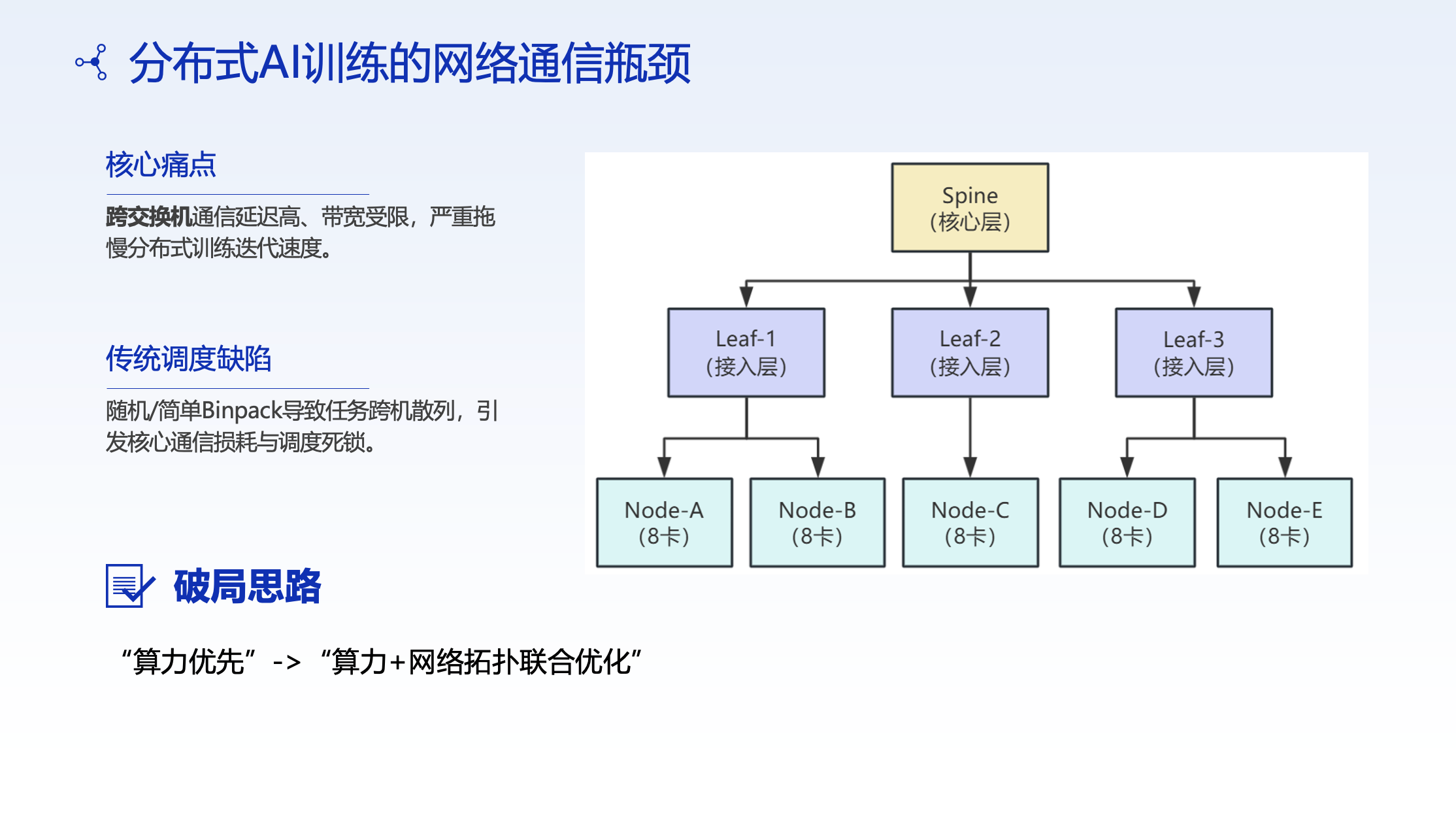
In distributed AI training, tasks randomly distributed across Leaf switches and nodes cause cross-switch communication to become a bottleneck. The shift from compute-first scheduling to compute-and-network-topology co-optimization is essential.
Three-Tier Topology Abstraction
The physical network topology is abstracted into three levels:
Level 1: Same Node — Lowest communication latency
Level 2: Same LEAF Switch — Lower latency
Level 3: Cross LEAF Switch — Highest latency
Multi-Level Topology Scoring
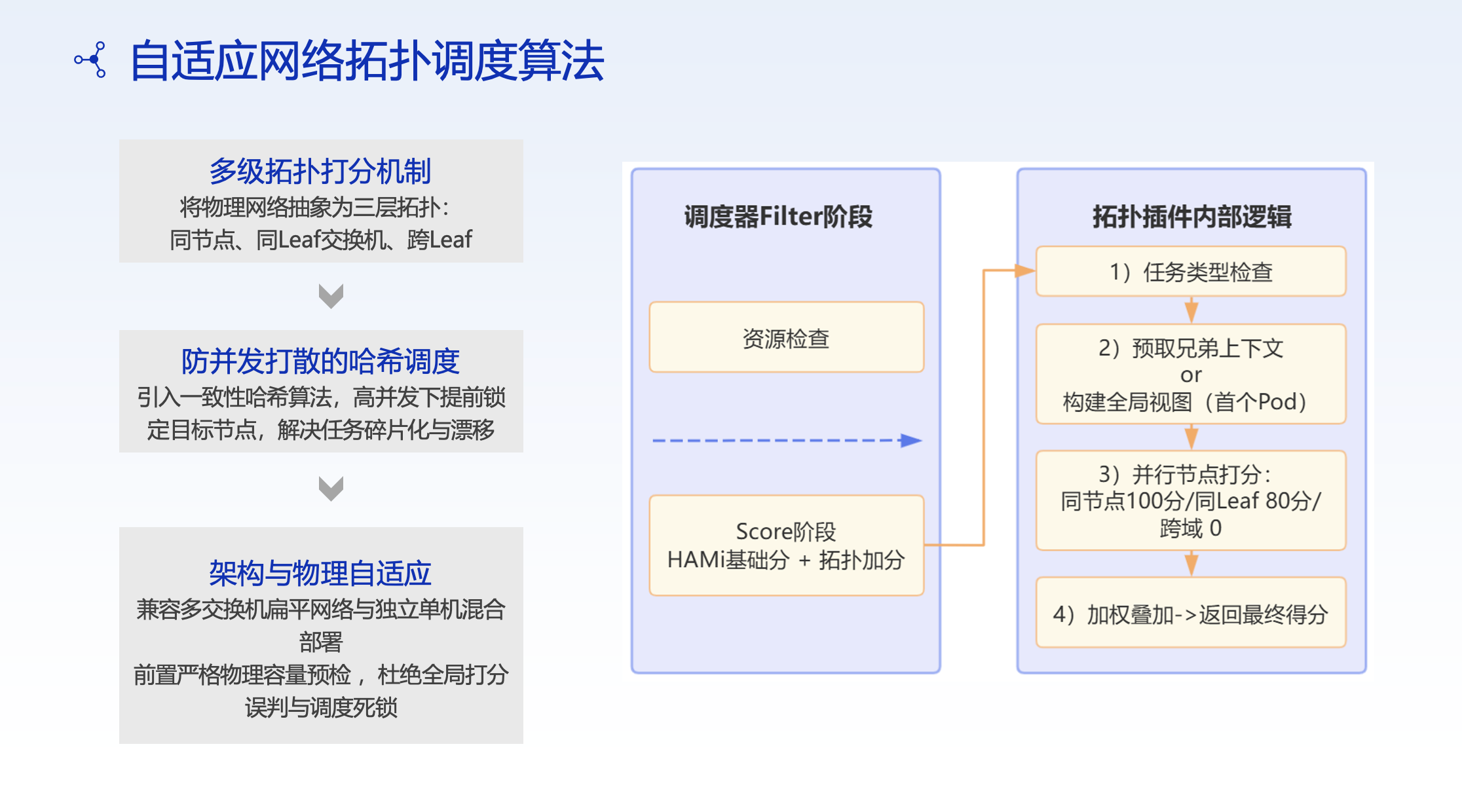
Topology-based scoring is added during the scheduler's scoring phase:
- Allocation within the same node: highest priority
- Allocation within the same LEAF switch: medium priority
- Allocation across LEAF switches: lowest priority
Result: Cross-node scheduling probability reduced by 30%, significantly alleviating communication bottlenecks in distributed training.
Anti-Fragmentation Mechanism
A real production issue: different Pods of the same batch of tasks may be scattered across different nodes by the scheduler, causing task fragmentation.
CMB uses deterministic hashing based on controller UIDs to ensure that different Pods of the same batch are preferentially co-located on the same target node.
Overall Results
- Hardware pooling rate: Increased to 100%
- Cross-node scheduling probability: Reduced by 30%
- Minimum partitioning granularity: 1 GB VRAM / 1% compute
- Task fragmentation: Significantly reduced
5. Summary

Starting from the real pain points of heterogeneous compute in the financial industry, Su Xi's presentation demonstrated China Merchants Bank's practical path to building a unified compute infrastructure on HAMi: through super-node hardware adaptation to solve resource alignment in dual-chip module architectures, achieving a 100% hardware pooling rate; combining vNPU-Core software partitioning for fine-grained resource provisioning at the 1 GB VRAM / 1% compute level on Ascend NPUs; and introducing network topology-aware scheduling through three-tier topology abstraction and multi-level scoring, reducing cross-node scheduling probability by 30% to significantly optimize distributed training communication efficiency.
Overall, this solution bridges the critical chain from hardware adaptation and resource partitioning to scheduling optimization, evolving heterogeneous compute from "usable" to "efficiently usable." It achieves simultaneous improvements in resource utilization and training efficiency for core scenarios such as large model training and batch inference. At the same time, China Merchants Bank's contribution of these capabilities back to the HAMi open-source community reflects the financial industry's transition from "user" to "co-builder" in the AI infrastructure space.
Looking ahead, as AI workloads continue to fragment and diversify, compute scheduling will evolve further toward finer granularity and greater elasticity. On one hand, continued deepening of software partitioning capabilities will improve scheduling flexibility and multi-tenant isolation. On the other hand, leveraging open-source ecosystems like HAMi will drive standardization and the continued accumulation of industry best practices.