Beyond GPU Exclusive Access: Unified Training and Inference with HAMi — Boardware's GPU Virtualization in Practice
GPU management in research labs has always been a tough challenge: diverse model types, shared resources across teams, mixed training and inference workloads, and ever-rising hardware costs. Over three years, Boardware evolved from VM-exclusive GPU access to a Kubernetes + HAMi cloud-native solution, ultimately achieving physical isolation of Agent RL training and inference on a 12-GPU cluster.
This is the seventh article in the "Efficiency Over Raw Power | HAMi Community Meetup" Shenzhen recap series. On April 25, 2026, Boardware researcher Ou Binkai shared this complete evolution journey.
Key Highlights:
- From VM-exclusive to K8s + HAMi: 70% of research GPUs transformed from idle to efficient utilization
- 12 GPUs achieving physical isolation for Agent RL training and inference
- HAMi Core fine-grained partitioning supporting 1.2-1.3x memory overcommit
- Infiniband + RDMA optimization delivering significant RPS improvement at 200 concurrent inference requests
- "Compute management granularity is getting finer, while the usage barrier is getting lower"
Speaker: Ou Binkai (Researcher, Boardware)

Ou Binkai holds a Master of Science degree and is currently a researcher at Boardware, focusing on large language models and multimodal model research and engineering applications. He also serves as the Director of the Brain-Computer Digital Fusion Laboratory at the Guangdong Institute of Intelligent Science and Technology, and as PI leads multiple innovation R&D projects funded by the Macau Science and Technology Development Fund. He has extensive industry-academia experience in AI, IoT, and wireless communications, with multiple publications and patents. He holds Baidu Chief AI Architect and PaddlePaddle Technical Expert certifications, along with expert-level certifications from several cloud providers.
Video Replay & Slides
- Bilibili: Boardware x HAMi: GPU Virtualization and Cluster Management R&D Experience Sharing - Ou Binkai
- Download PPT: boardware-gpu-virtualization-oubinkai.pdf
1. The Pain of GPU Management in Research Labs
GPU usage scenarios in research labs differ significantly from enterprise production environments:
- Diverse model types with varying parameter scales
- Multiple research teams sharing limited GPU resources
- Training, inference, and debugging tasks running simultaneously
- Need to balance research efficiency with hardware cost control
Boardware has deep experience in research and university scenarios, accumulating rich AI compute management expertise. In field research, they discovered that over 70% of research GPU resources are idle or underutilized — not because no tasks are running, but because resource allocation granularity is too coarse, resulting in significant memory waste.

2. Architecture Evolution: From VMs to Containerization
Early Approach: VM-Exclusive + VPC Partitioning
The team initially used VM-exclusive access or VPC partitioning for GPU resource management, but encountered several pain points:
- No dynamic memory adjustment: Allocation was fixed after assignment, with no elastic scaling on demand
- Limited cross-GPU scheduling: Virtualization layer restrictions made multi-GPU task scheduling inflexible
- Fragmented environments: CPU and GPU environments were separated, increasing operational complexity
Evolved Solution: Full Kubernetes + HAMi Adoption
The team fully embraced Kubernetes, achieving lightweight compute and flexible scheduling through containerization, and introduced HAMi as the GPU virtualization and scheduling layer. HAMi (Heterogeneous AI Computing Virtualization Middleware) is a CNCF incubating project that provides fine-grained GPU memory isolation and compute partitioning, enabling multiple containers to safely share the same physical GPU.

3. Custom Scheduling Platform: One Click Deployment Platform
To address customers' "out-of-the-box" localized deployment needs, Boardware developed the "One Click Deployment Platform" — an AI compute management platform designed for research and university scenarios. It abstracts away the complexity of underlying K8s and HAMi, enabling researchers to quickly launch training tasks without operational knowledge. Core capabilities include:
- Multi-cluster management: Unified management of GPU resources across multiple K8s clusters
- Multi-region deployment: Cross-region compute resource scheduling support
- RDMA network optimization: Deep optimization of Infiniband networks for improved distributed training efficiency
- Simplified deployment: One-click algorithm environment deployment, lowering the usage barrier
Performance Validation: Infiniband vs Ethernet
Under the Qwen 3 model inference scenario, the team conducted comparative testing between Infiniband and traditional Ethernet networks:
- Test conditions: 200 concurrent users
- Results: Using Infiniband + RDMA technology, total request volume and RPS (requests per second) showed significant improvement compared to traditional Ethernet
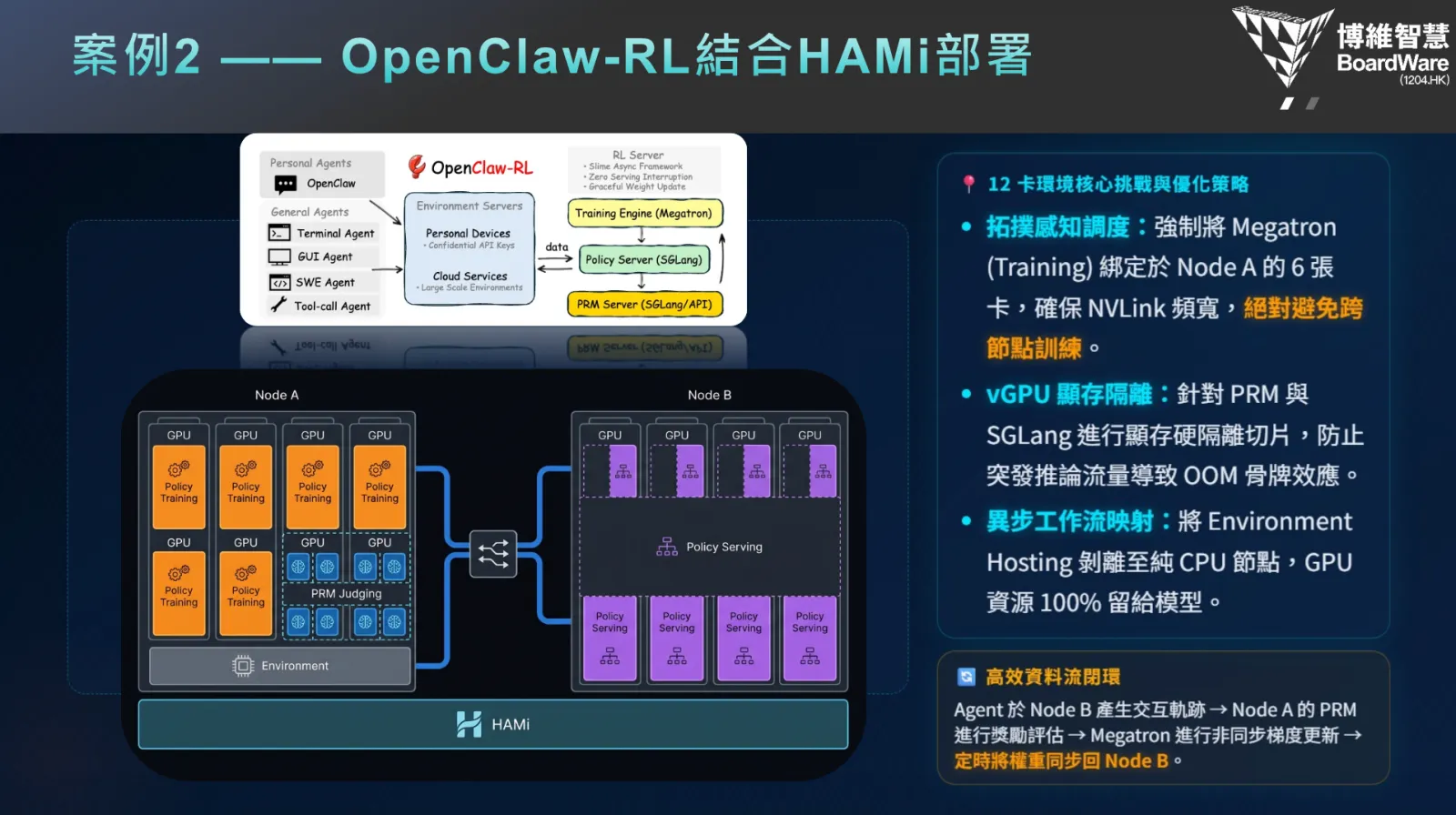
4. Agent RL Practice: Physical Isolation of Training and Inference
This was the most technically in-depth part of the presentation. With the rise of the Agent paradigm, reinforcement learning (RL) has become a key pathway for improving large model reasoning capabilities. However, in practical engineering, Agent RL workflows present unprecedented challenges for GPU resources.
Core Challenge
In Agent RL (reinforcement learning) workflows, training and inference are two tightly coupled yet vastly different in resource requirements. How to support both simultaneously with limited GPU resources?
HAMi Solution
Under the OpenRL framework, HAMi was used to partition the 12-GPU cluster into:
- Node A (Training Node): Handling model training tasks
- Node B (Inference Node): Handling environment interaction and inference evaluation tasks
This achieved physical isolation of training, evaluation, and inference without mutual interference. This means gradient updates during training don't affect inference service response latency, and environment interaction results from the inference side can be fed back to the training side in real-time, forming an efficient RL loop.
Key Technical Metrics
- Supports memory overcommit of 1.2-1.3x, further improving resource utilization
- Completed small-scale validation with 9B models
- Fine-grained GPU partitioning through HAMi Core
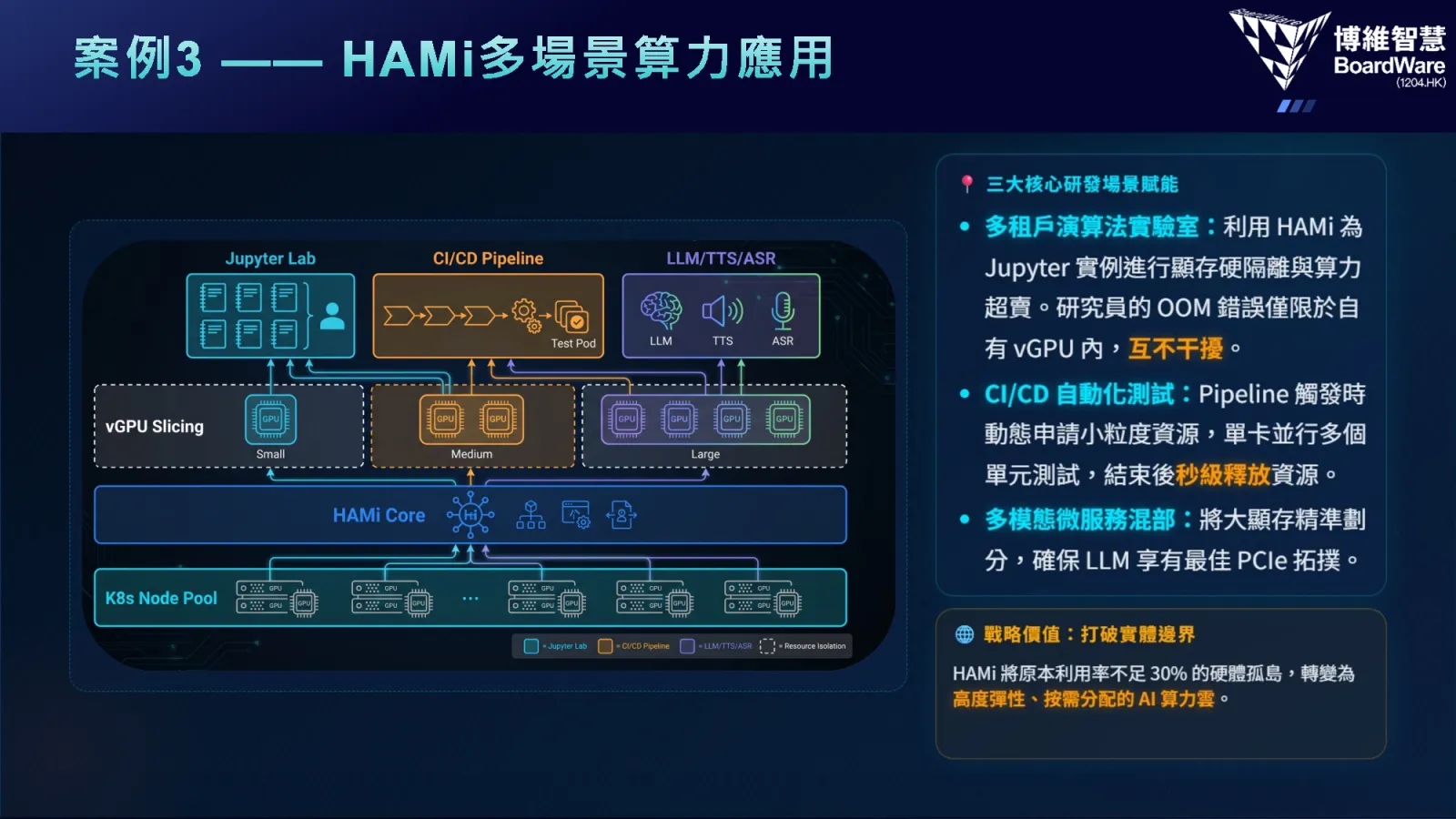
5. Multi-Scenario Compute Support for Universities
In university scenarios, the same cluster needs to handle multiple workload types:
- Jupyter Lab: Interactive development environment for teaching and research
- ML Applications: Machine learning training and inference tasks
- Voice & Digital Humans: AI multimodal applications
Through HAMi Core, multiple workloads run in a mixed mode on the same cluster, solving the fragmentation between CPU and GPU environments and providing universities with a one-stop AI compute platform. This solution has been deployed at multiple universities and research institutions, significantly lowering the operational barrier for AI infrastructure.
Conclusion
From VM-exclusive access to Kubernetes containerization, and then to HAMi-based GPU virtualization scheduling, Boardware's evolution path reflects a universal trend in research computing infrastructure: compute management granularity is getting finer, while the usage barrier is getting lower.
The most valuable takeaway from this presentation is not any single technical detail, but the systematic thinking behind the entire solution. Boardware didn't stop at "assigning GPUs to containers" — they built a complete scheduling platform on top, delved into Infiniband network optimization underneath, and horizontally bridged the isolation of Agent RL training and inference. This combination enables a 12-GPU cluster to handle training, inference, teaching, and other diverse workloads, dramatically improving GPU resource utilization.
For teams facing similar GPU utilization challenges, here are some actionable takeaways: HAMi's memory overcommit capability has been validated in production environments at 1.2-1.3x; Infiniband + RDMA delivers tangible benefits for large model inference; and the training-inference physical isolation approach is worth prioritizing for teams exploring Agent RL.