Global Co-building: vLLM Community Natively Supports HAMi, Inference Efficiency Leap — Contribution from a Spanish Developer
After large model inference entered the production stage, how to maximize GPU resource utilization, achieve multi-model coexistence, and improve deployment flexibility has become the focus of many enterprises and developers. Recently, the vLLM community officially merged PR#579, natively supporting CNCF Sandbox & CNAI Project HAMi. This not only represents HAMi’s capability being accepted by mainstream inference frameworks, but also means that vLLM users can directly split GPU memory and computing power for deployment out of the box with HAMi.
This article takes the PR as an entry point, combined with community Issues and email exchanges, to fully restore a "HAMi × vLLM" landing path from deployment to verification, helping you quickly achieve multi-model deployment and resource reuse in Kubernetes.
I. 1+1>2: The Combination Point of vLLM × HAMi
vLLM is an open-source high-performance inference engine, improving throughput/concurrency with PagedAttention and continuous batching while being compatible with the OpenAI interface; the positioning of vLLM Production Stack is to productize vLLM on Kubernetes, filling in elastic scaling, observability monitoring, traffic routing/gray release, and operations publishing, making it operable and scalable into production environments. HAMi provides fine-grained GPU partitioning and scheduling capabilities, including:
- GPU computing power control (SM Util)
- GPU memory limits (MB / %)
- Node/GPU scheduling policies (Binpack / Spread)
- Topology-aware scheduling (NUMA / NVLink)
Achieving production-level LLM inference optimization is a systematic project that needs to solve both “computation” and “scheduling”. vLLM focuses on the computation layer, pushing single-GPU throughput performance to the limit through innovative memory management; HAMi focuses on the scheduling layer and virtualization, bringing fine-grained GPU partitioning and management capabilities to Kubernetes. The combination perfectly covers the two key links from resource scheduling to performance optimization.
II. Community-driven Integration: PR #579 Originating from Real Needs
The integration of vLLM and HAMi was not a “top-down” plan by the project party, but a community contribution driven by real user needs, “bottom-up”.
It all started with PR #579, contributed by community contributor Andrés Doncel from Spain, working at Empathy.co, a toB e-commerce search and product discovery platform provider. As the company explained in its official blog, its core technical goal is to “bridge the gap between generative AI and factual accuracy” — through an advanced RAG (Retrieval Augmented Generation) framework, ensuring AI answers are evidence-based and eliminating “hallucinations”.
This extreme pursuit of factual accuracy technically means needing to efficiently and cost-effectively deploy multiple AI models in collaboration, such as Embedding (vector recall), Reranking (model re-ranking), and fact-checking. It was precisely from this real and urgent production demand that Andrés contributed vLLM’s support for HAMi, which was recognized and merged by the community, bringing this production-verified cost reduction and efficiency improvement solution to all vLLM users.
To explore the motivation behind this contribution, we communicated with Andrés. He mentioned:
“Our use case is to serve LLM-powered applications while minimizing the dependency from third party providers. We use HAMi and vLLM on top of Kubernetes... using the memory constraints to allow multiple models to reside in the same GPU.”
This confirmed the real scenario demand from community users for the HAMi + vLLM combination.
Rapid Verification of Value: Issue #649 : “Does it support deploying multiple models on a single GPU?”
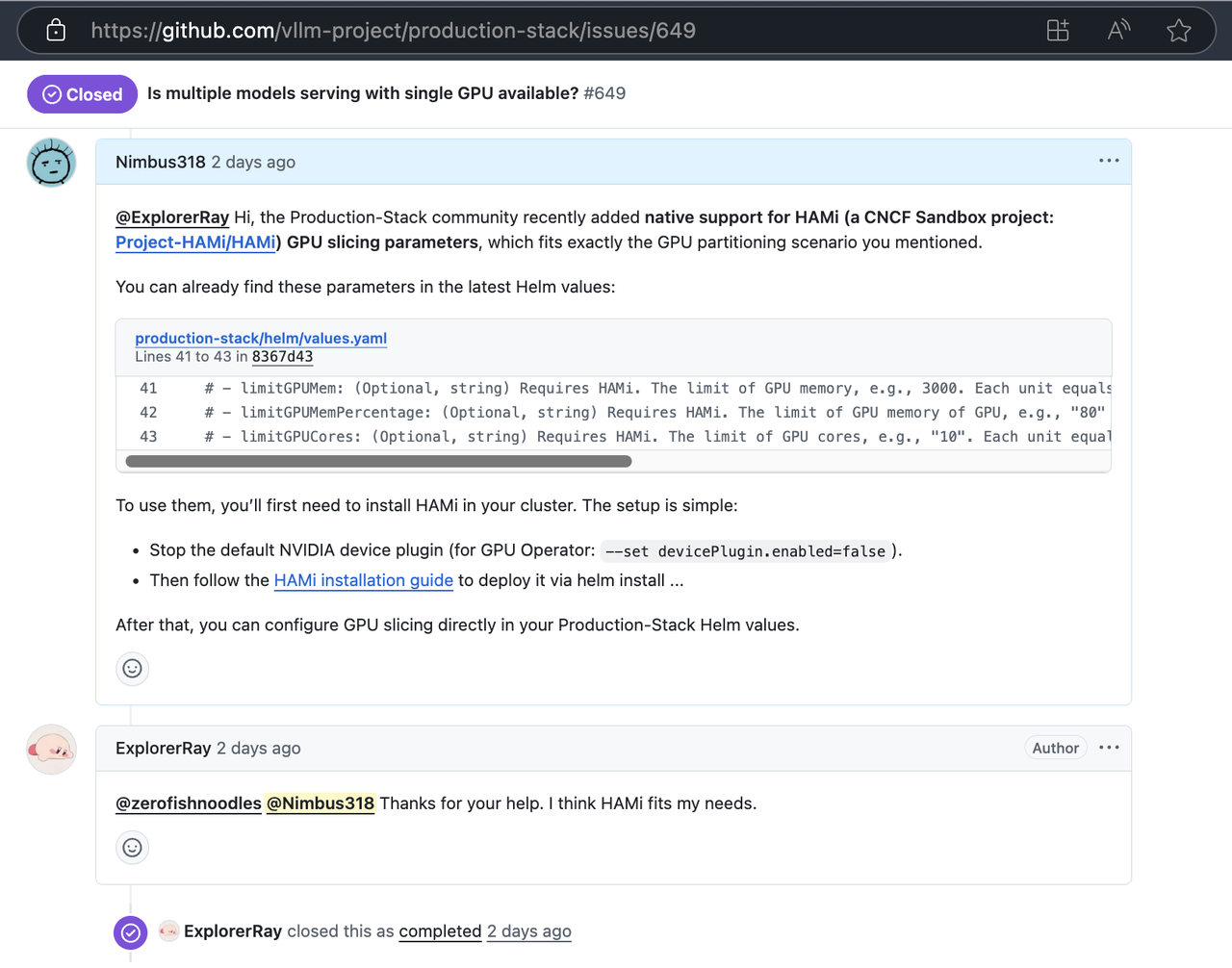
@Nimbus318 replied:
“Production Stack has natively supported HAMi parameters, just install HAMi and configure the split parameters.”
And explained how to enable parameter support, eventually gaining user recognition and closing the Issue:
“Thanks for your help. I think HAMi fits my needs.”
From a real-need PR contribution to a perfect solution to a community problem, this formed a textbook-style positive open-source community cycle.
III. Complete Practice: From Installation and Deployment to Testing and Monitoring
3.1 Preparation: Install HAMi and Take Over GPU Scheduling and Allocation
# 1. If using NVIDIA GPU Operator, disable its default devicePlugin via Helm
helm upgrade --install gpu-operator nvidia/gpu-operator \
-n gpu-operator \
--set devicePlugin.enabled=false \
--set dcgmExporter.serviceMonitor.enabled=true \
--version=v25.3.1
# 2. Label nodes requiring GPU sharing
kubectl label nodes <your-gpu-node-name> gpu=on
# 3. Install HAMi
helm repo add hami-charts https://project-hami.github.io/HAMi/
helm install hami hami-charts/hami -n kube-system
After execution, HAMi officially takes over GPU scheduling and allocation in the cluster, and the basic environment is ready.
3.2 Core Step: Deploy Multiple Models via Production Stack
Since the native support feature has been merged into the main branch but not yet included in the official release, we need to directly install from the latest Helm Chart in the vLLM Production Stack GitHub repository.
- Pull the latest source code and create a custom configuration file
Enter thehelmdirectory of theproduction-stackproject, and create thevalues-hami-demo.yamlfile:
git clone https://github.com/vllm-project/production-stack.git
cd production-stack/helm
touch values-hami-demo.yaml
Write the following content into values-hami-demo.yaml. This configuration defines our deployment blueprint: on a single L4 card, using the binpack strategy to deploy one Embedding model requesting 14GB memory and one Reranker model requesting 8GB memory.
servingEngineSpec:
modelSpec:
# BAAI/bge-m3 Embedding Model
- name: "bge-m3-embed"
repository: "vllm/vllm-openai"
tag: "latest"
modelURL: "BAAI/bge-m3"
replicaCount: 1
requestCPU: 2
requestMemory: "6Gi"
requestGPU: 1
limitGPU: 1
requestGPUMem: "14000"
limitGPUMem: "14000"
podAnnotations:
nvidia.com/use-gputype: "L4"
hami.io/gpu-scheduler-policy: "binpack"
pvcStorage: "10Gi"
vllmConfig:
dtype: "auto"
maxModelLen: 8192
maxNumSeqs: 32
gpuMemoryUtilization: 0.85
extraArgs: ["--task", "embed"]
# BAAI/bge-reranker-v2-m3 Reranker Model
- name: "bge-reranker-v2-m3"
repository: "vllm/vllm-openai"
tag: "latest"
modelURL: "BAAI/bge-reranker-v2-m3"
replicaCount: 1
requestCPU: 2
requestMemory: "4Gi"
requestGPU: 1
limitGPU: 1
requestGPUMem: "8000"
limitGPUMem: "8000"
podAnnotations:
nvidia.com/use-gputype: "L4"
hami.io/gpu-scheduler-policy: "binpack"
pvcStorage: "5Gi"
vllmConfig:
dtype: "auto"
maxModelLen: 512
maxNumSeqs: 8
gpuMemoryUtilization: 0.85
extraArgs: ["--task", "score"]
- Deploy from local source
In the helm directory, run the following command. Note the final.means using the current directory Chart:
helm upgrade --install vllm -f values-hami-demo.yaml .

3.3 Resource Verification and Function Testing
1. Resource Allocation Verification: Check GPU Sharing Status
... (keep all original command outputs and nvidia-smi results translated minimally where needed) ...
2. Collaborative Function Test: Simulate Real RAG Call Chain
... (keep script rag_bench.py unchanged except comments translated) ...
3.4 Test Results and Monitoring Dashboard
... (translated log outputs) ...
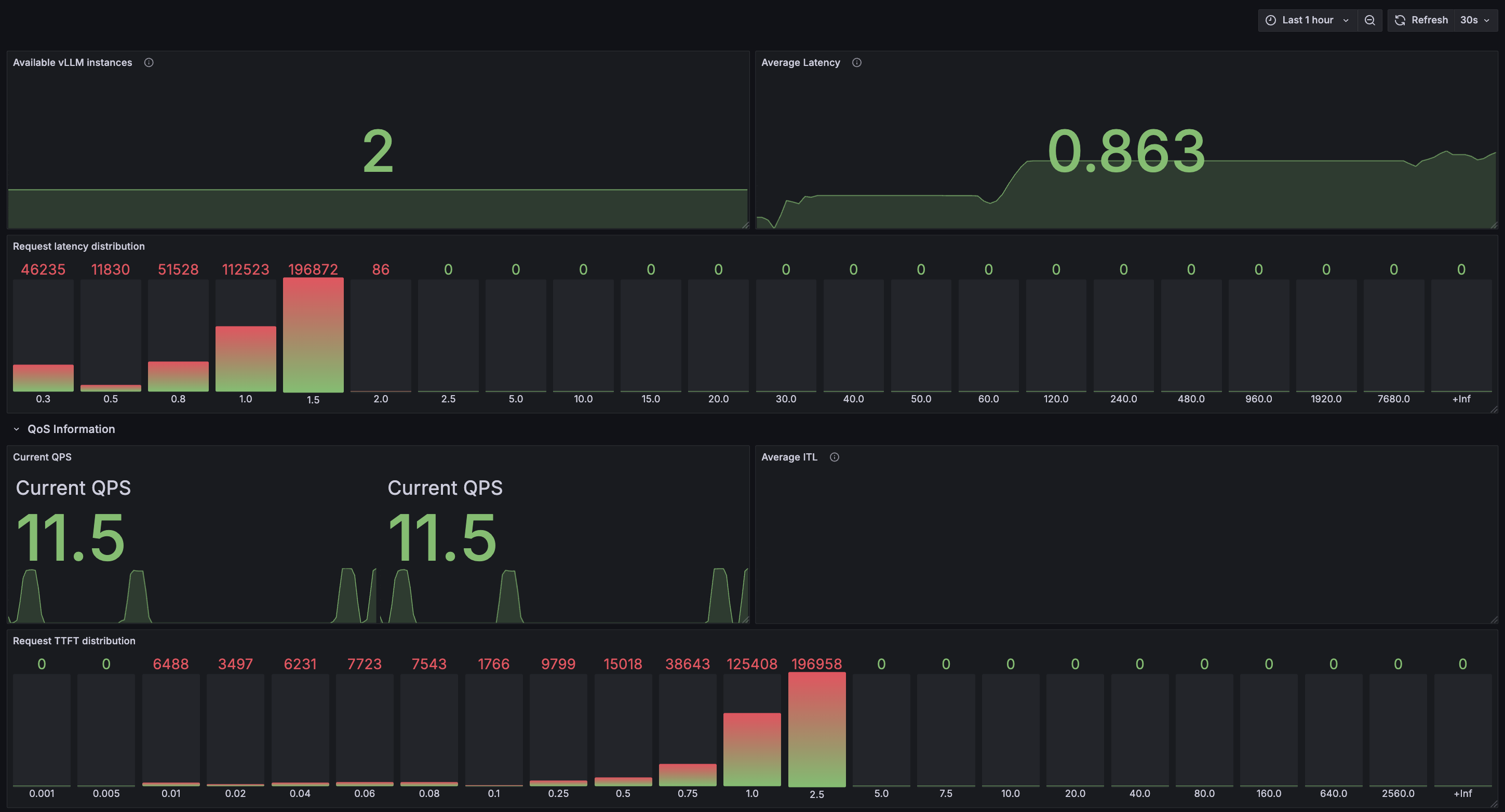
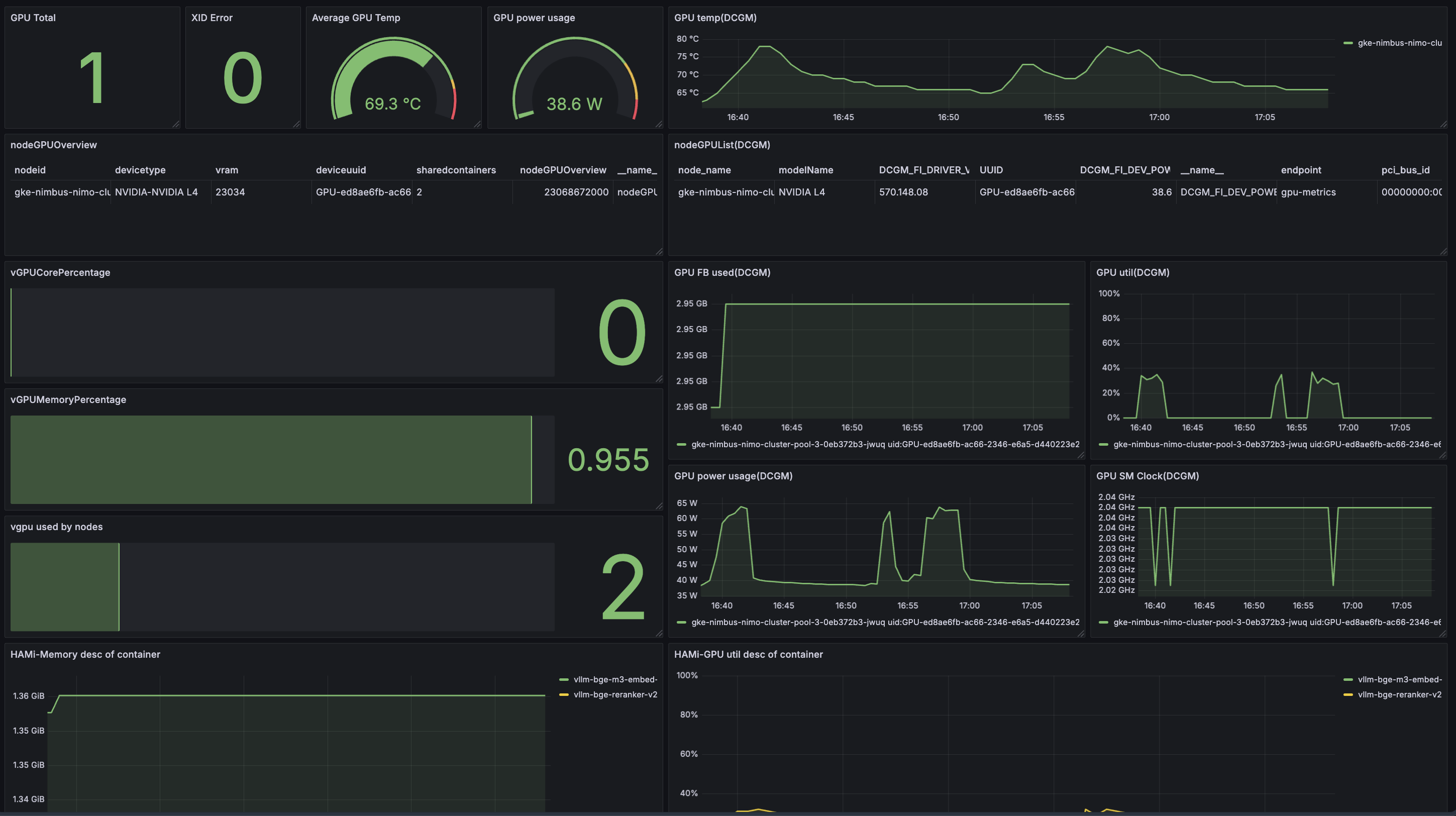
Summary and Outlook
The merging of PR #579 marks: HAMi has become the officially integrated and recognized GPU sharing solution of vLLM Production Stack. We look forward to more model inference deployment engineering solutions natively docking with HAMi in the future, thereby using GPU resources more flexibly and efficiently in production.
HAMi, short for Heterogeneous AI Computing Virtualization Middleware, is a “one-stop” architecture designed to manage heterogeneous AI computing devices in Kubernetes clusters, providing sharing capabilities and task-level resource isolation for heterogeneous AI devices. HAMi is committed to improving the utilization of heterogeneous computing devices in Kubernetes clusters, providing a unified reuse interface for different types of heterogeneous devices. Currently, it is a CNCF Sandbox project and has been included in the CNCF CNAI category technology landscape.

Dynamia focuses on CNCF HAMi as the core foundation, providing flexible, reliable, on-demand, and elastic GPU virtualization and heterogeneous computing scheduling, and unified management global solutions. It can be deployed in a plug-in, lightweight, non-intrusive way in any public cloud, private cloud, or hybrid cloud environment, and supports heterogeneous chips such as NVIDIA, Ascend, Muxi, Cambricon, Hygon, Moore Threads, and Biren.
Website: https://dynamia.ai
Email: info@dynamia.ai