Nvidia's Open-Sourced KAI-Scheduler vs. HAMi: An Analysis of Technical Paths to GPU Sharing and a Look at Future Synergy
Recently, with Nvidia's acquisition of Run:ai and the subsequent open-sourcing of its core scheduling component, KAI-Scheduler, both the AI and Kubernetes communities have been paying close attention. The GPU Sharing feature introduced by KAI-Scheduler, in particular, has caught the eye of many who focus on GPU resource virtualization.
This has naturally sparked some technical discussions: How do the GPU Sharing implementation methods of KAI-Scheduler and HAMi differ? What scenarios are each of these different approaches best suited for, and how will they collectively advance the community in the realm of GPU sharing and virtualization?
With these questions in mind, we have delved deep into the architecture and technical implementation of KAI-Scheduler's GPU Sharing, especially its innovative Reservation Pod mechanism. At the same time, we've had active exchanges with the Run:ai team recently, including in-depth discussions at KubeCon EU 2025 with Run:ai's CTO, Ronen Dar, and his colleagues on topics like KAI-Scheduler, HAMi, and open-source collaboration. Today, we're doing a technical deep dive to compare the implementation methods of KAI-Scheduler and HAMi, and to look ahead at the possibilities for future collaboration.
Article at a Glance
- Pain Point Analysis: Why is sharing GPUs in native K8s so difficult?
- Mechanism Explained: How does KAI cleverly achieve sharing with Reservation Pods?
- Solution Breakdown: The highlights and limitations of KAI's sharing solution.
- Path Comparison: How does it compare to HAMi, and what is the value of hard isolation?
- Collaboration Outlook: Active community dialogue and the potential for future synergy.
Pain Point Analysis
I. The "Pain Point" of Native K8s: Why Are GPUs Hard to Share?
Before diving into KAI, let's first review why implementing GPU sharing in Kubernetes is a challenge in itself:
- Integer Limitation: The native Kubernetes resource model (
nvidia.com/gpu) only recognizes integer GPUs. It cannot express a request like "I want 0.2 of a GPU." - Scheduler Ignorance: The standard
kube-schedulerdoesn't understand the concept of fractional GPUs. It might assign a GPU that should be shared to a Pod requesting a full card, causing conflicts. - "Black Box" State: How can the Kubernetes cluster know that a certain GPU is already partially occupied? There's no standard way to represent this.
- User Inconvenience: Developers need a simple and intuitive way to request and use fractional GPU resources.
Mechanism Explained
II. KAI's Ingenuity: Using a Reservation Pod as a Clever Workaround
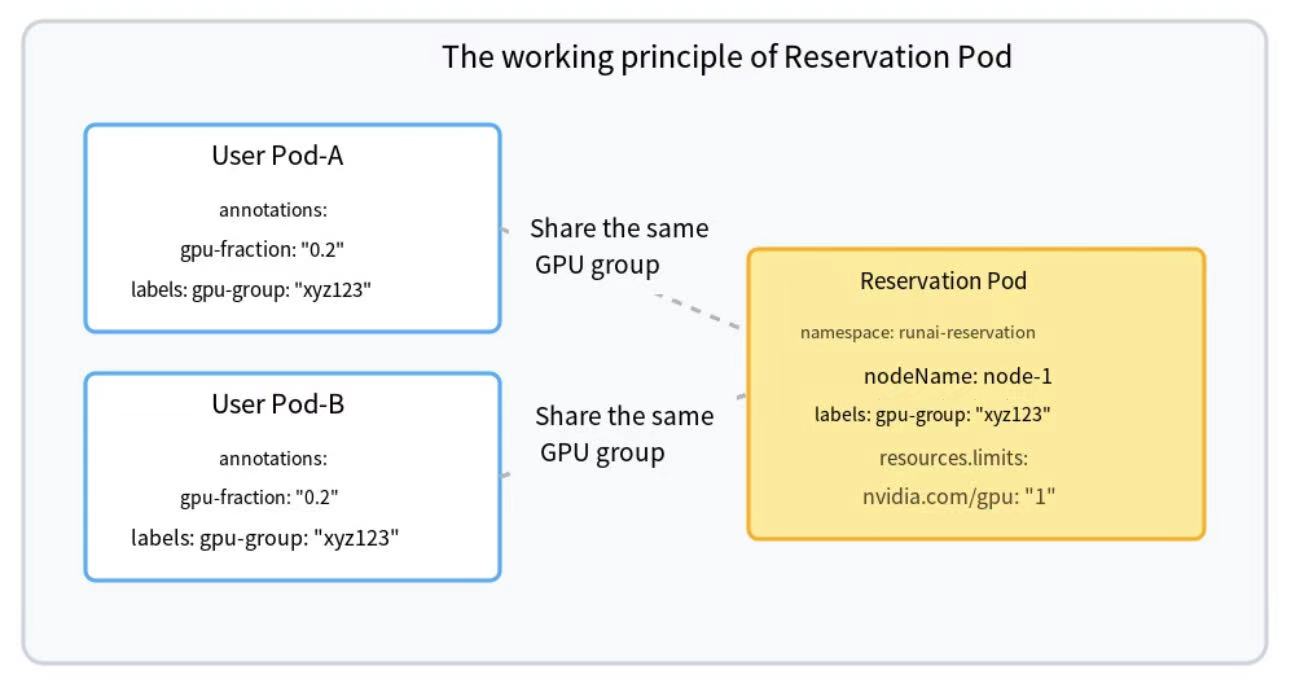
Facing these challenges, KAI-Scheduler has proposed a very clever solution: the Reservation Pod.
The core idea can be understood as a form of "logical deception":
- When a Pod requests a fractional GPU, KAI-Scheduler doesn't directly try to tell K8s, "This Pod wants 0.x of a GPU."
- Instead, it creates a special, low-resource-consuming Reservation Pod. This Pod properly requests a whole GPU (
nvidia.com/gpu: "1") from Kubernetes! - This way, Kubernetes thinks the GPU is fully allocated, so the
kube-schedulernaturally won't schedule any other Pods onto this GPU. - The actual fractional management and allocation logic is entirely maintained internally by KAI-Scheduler.
This Reservation Pod primarily serves the following functions:
- GPU Reservation: It "claims sovereignty" over the GPU in the eyes of K8s, occupying the entire resource.
- Resource Visibility: It makes the "partially used" state of the GPU indirectly visible within the K8s system (although K8s thinks it's fully occupied by the Reservation Pod).
- Conflict Prevention: It prevents the standard scheduler from touching this GPU that is being shared.
- Logical Grouping: By giving the Reservation Pod and the user Pods sharing it the same label (e.g.,
gpu-group: xyz123), it logically binds them together.
III. A Deeper Technical Look: How Does KAI GPU Sharing Work?
Now that we understand the core idea, let's take a closer look at the implementation:
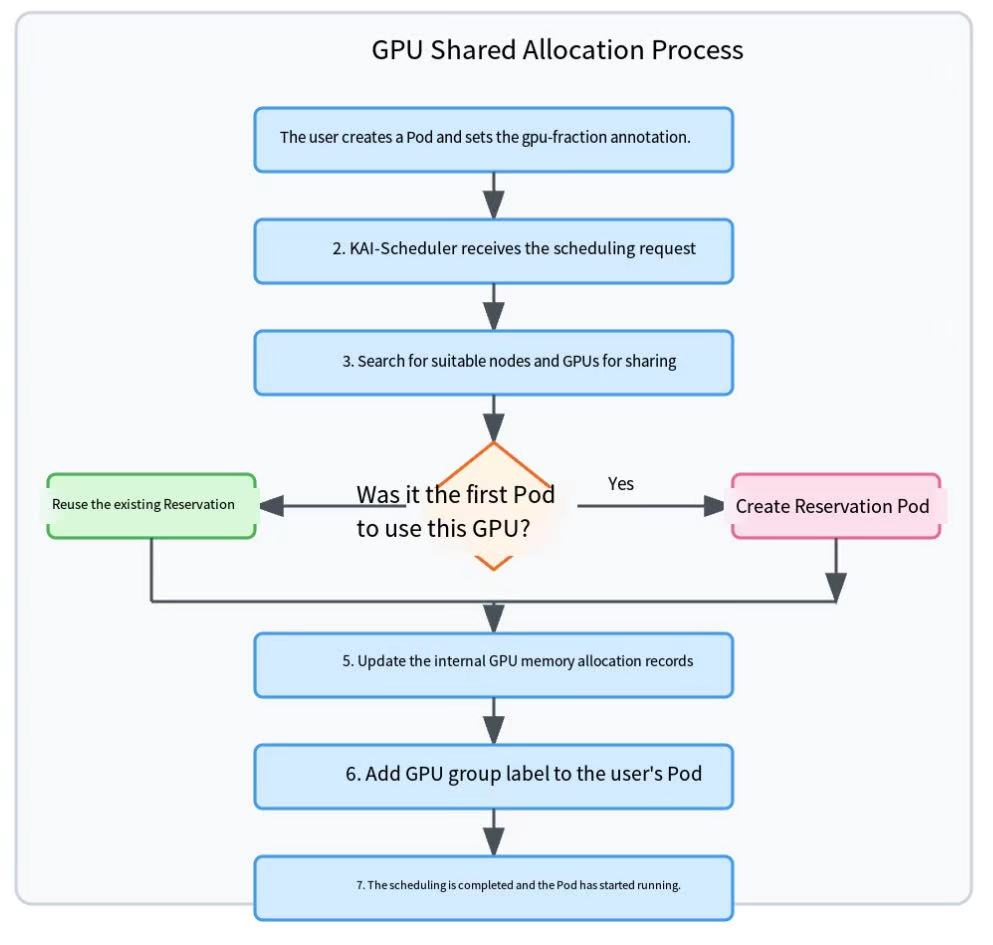
- User Request: The user Pod submits its fractional GPU requirement via
annotations, for example:
metadata:
annotations:
gpu-fraction: "0.2" # Request 20% of GPU resources
-
KAI Scheduling:
- KAI-Scheduler identifies the
gpu-fractionannotation. - It calculates the required resources (e.g., how much memory 20% corresponds to) and finds a suitable node and physical GPU.
The allocation logic is implemented in
pkg/scheduler/gpu_sharing/gpuSharing.go: - KAI-Scheduler identifies the
func AllocateFractionalGPUTaskToNode(
ssn *framework.Session,
stmt *framework.Statement,
pod *pod_info.PodInfo,
node *node_info.NodeInfo,
isPipelineOnly bool,
) bool {
fittingGPUs := ssn.FittingGPUs(node, pod)
gpuForSharing := getNodePreferableGpuForSharing(fittingGPUs, node, pod, isPipelineOnly)
if gpuForSharing == nil {
return false
}
pod.GPUGroups = gpuForSharing.Groups
isPipelineOnly = isPipelineOnly || gpuForSharing.IsReleasing
success := allocateSharedGPUTask(ssn, stmt, node, pod, isPipelineOnly)
if !success {
pod.GPUGroups = nil
}
return success
}
**Key Aspect: Reservation Pod Management**
- **First Allocation**: If this is the first Pod to request sharing of this GPU, KAI-Scheduler creates a Reservation Pod (by calling `createResourceReservationPod`), requests `nvidia.com/gpu: "1"`, and assigns it a unique `gpu-group` label.
- **Subsequent Allocations**: If it detects that a Pod is already sharing this GPU (i.e., a Reservation Pod with the corresponding `gpu-group` exists), it reuses this Reservation Pod instead of creating a new one.
- **Binding**: KAI-Scheduler will also apply the same `gpu-group` label to the current user Pod to establish the association.
The Reservation Pod creation logic is implemented in `pkg/binder/binding/resourcereservation/resource_reservation.go`:
// createResourceReservationPod creates a pod on a specified node for the sole purpose of resource reservation
func (rsc *service) createResourceReservationPod(
nodeName, gpuGroup, podName, appName string,
resources v1.ResourceRequirements,
) (*v1.Pod, error) {
podSpec := &v1.Pod{
ObjectMeta: metav1.ObjectMeta{
Name: podName,
Namespace: namespace, // runai-reservation
Labels: map[string]string{
constants.AppLabelName: appLabelValue,
constants.GPUGroup: gpuGroup,
runaiResourceReservationAppLabelName: appName,
},
},
Spec: v1.PodSpec{
NodeName: nodeName, // Pinned to a specific node
ServiceAccountName: serviceAccountName,
Containers: []v1.Container{
{
Name: resourceReservation,
Image: rsc.reservationPodImage, // Lightweight container image
Resources: resources, // Requests the entire GPU
// ...other configurations
},
},
},
}
return podSpec, rsc.kubeClient.Create(context.Background(), podSpec)
}
- **Internal Bookkeeping**: In KAI-Scheduler's internal state (the `GpuSharingNodeInfo` struct), it accurately records the allocated GPU memory for each `gpu-group`. The core structure for tracking GPU sharing status is defined in `pkg/scheduler/api/node_info/gpu_sharing_node_info.go`:
// GpuSharingNodeInfo tracks the real-time status of GPU sharing usage on a node
type GpuSharingNodeInfo struct {
// Shared GPUs that are being released (key is GPU ID)
ReleasingSharedGPUs map[string]bool
// Memory used on each GPU (in bytes)
UsedSharedGPUsMemory map[string]int64
// Amount of memory being released (in bytes)
ReleasingSharedGPUsMemory map[string]int64
// Amount of shared memory that has been allocated (in bytes)
AllocatedSharedGPUsMemory map[string]int64
}
- `UsedSharedGPUsMemory`
Records the total memory (in bytes) **actually used by Pods** on each GPU group.
- `ReleasingSharedGPUsMemory`
Records the total memory (in bytes) that is **currently in the process of being released** on each GPU group.
- `AllocatedSharedGPUsMemory`
Records the total memory (in bytes) that has been **allocated by the Scheduler** to Pods, but which the Pods may not have actually occupied yet.

-
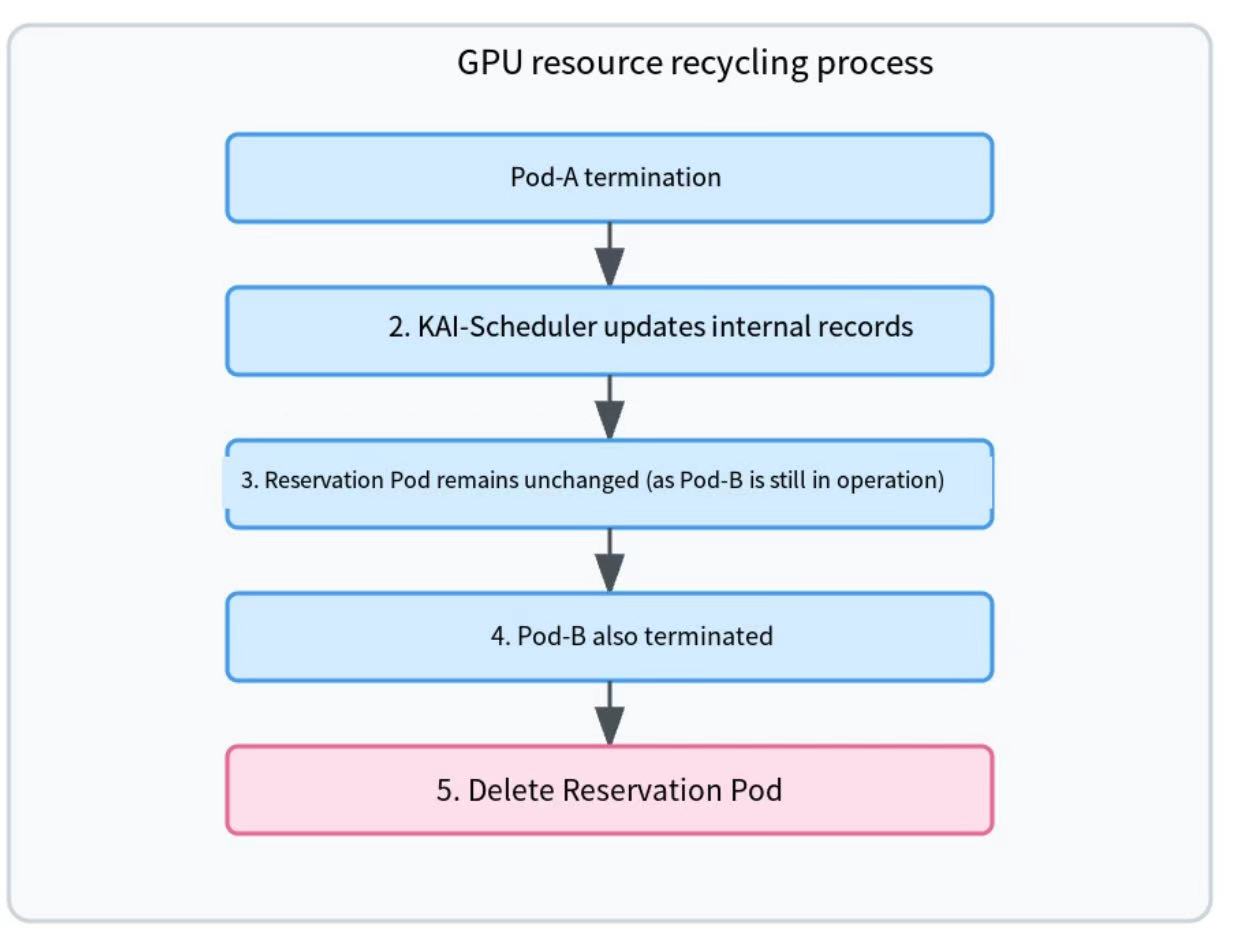
Resource Reclamation:
- When a user Pod sharing a GPU terminates, KAI updates its internal bookkeeping.
- When the last user Pod associated with a
gpu-groupends, KAI-Scheduler detects that thisgpu-groupno longer has active user Pods, and it then deletes the corresponding Reservation Pod (logic insyncForPods), thereby "returning" the GPU resource to K8s.
The resource reclamation logic is implemented in the `syncForPods` function:
// syncForPods separates pods on the current node into two categories: resource reservation pods and
// fractional pods that actually use the GPU, and cleans up legacy reservation pods when there are
// no corresponding fractional pods.
func (rsc *service) syncForPods(ctx context.Context, pods []*v1.Pod, gpuGroupToSync string) error {
logger := log.FromContext(ctx)
reservationPods := map[string]*v1.Pod{}
fractionPods := map[string][]*v1.Pod{}
// 1. Categorize pods into reservation pods and fractional pods by GPU group
for _, pod := range pods {
if pod.Namespace == namespace { // Reservation Pod
reservationPods[gpuGroupToSync] = pod
continue
}
if slices.Contains([]v1.PodPhase{v1.PodRunning, v1.PodPending}, pod.Status.Phase) {
fractionPods[gpuGroupToSync] = append(fractionPods[gpuGroupToSync], pod)
}
}
// 2. If a GPU group has no fractional pods, delete the corresponding reservation pod
for gpuGroup, reservationPod := range reservationPods {
if _, found := fractionPods[gpuGroup]; !found {
logger.Info("Did not find fraction pod for gpu group, deleting reservation pod",
"gpuGroup", gpuGroup)
if err := rsc.deleteReservationPod(ctx, reservationPod); err != nil {
return err
}
}
}
return nil
}
Key Insight: Control at the Scheduler Level, No Low-Level Intervention (Yet)
KAI-Scheduler's GPU Sharing implementation is accomplished solely at the scheduler level by creating/managing Pods, parsing Annotations, and maintaining internal state.
Therefore, KAI-Scheduler's implementation provides "soft isolation."
Solution Analysis
IV. Analysis of KAI's Solution: A Mix of Elegance and Practical Compromise
Let's objectively analyze the characteristics of KAI-Scheduler's GPU Sharing:
Highlights
- Elegant Integration: It exclusively uses standard K8s primitives (Pod, Annotation, Label), requiring zero modifications to core K8s components. This makes deployment and integration relatively simple.
- Good Compatibility: The Reservation Pod design cleverly avoids direct conflicts with other components like the
kube-scheduler. - High Flexibility: In theory, it supports fractional GPU allocation of any ratio, not limited by predefined tiers.
- Architectural Innovation: The "logical deception" design approach demonstrates a clever way to extend capabilities within the existing K8s framework.
Limitations
- Soft Isolation: This is the core characteristic of its design. KAI-Scheduler does not provide any mandatory resource isolation (neither memory nor compute units). It is only responsible for "logical" allocation and scheduling.
- Relies on a "Gentleman's Agreement": Actual resource usage is entirely dependent on the self-discipline of the application running inside the Pod. A Pod, even if it only requests
gpu-fraction: "0.2", could still attempt to use 80% or even 100% of the GPU's memory or compute power. KAI, at a pure scheduling level, cannot prevent this. - Potential for Interference: This means it cannot prevent a misbehaving application (whether intentionally or not) from overusing resources, thereby interfering with its "neighbor" Pods on the same physical GPU, leading to performance jitter or even Out-Of-Memory (OOM) errors.
- Requires Application Cooperation: To simulate an isolation effect as much as possible, users must manually set resource limits within their application code (e.g., using
torch.cuda.set_per_process_memory_fractionor similar configurations in TensorFlow). This adds complexity to usage and introduces potential points of error.
Path Comparison
V. A Comparison of Technical Paths: KAI's Lightweight Approach vs. HAMi's Hard Isolation
Now, let's compare KAI's solution with HAMi's technical path:
The core advantage of HAMi (and other GPU virtualization solutions that pursue strong isolation) is that it achieves Hard Isolation. This is typically accomplished through the following means:
- Custom HAMi Device Plugin: Not just for reporting resources, but for injecting isolation configurations during allocation.
- Integration with HAMi-Core: Leveraging interception at a lower level between the CUDA-Runtime and CUDA-Driver layers to enforce mandatory limits on each container's GPU memory resources.
The key advantages brought by hard isolation:
- Guaranteed Resources: Each container has a clear upper limit on the GPU resources it can use and cannot exceed its allocation.
- Strong Isolation: Effectively prevents the "noisy neighbor" problem, ensuring quality of service (QoS) in multi-tenant environments.
- Application Transparency: In most cases, user applications do not need to be modified or have extra configurations added.
The Choice Depends on the Scenario:
- KAI-Scheduler's Lightweight Approach: Its simple deployment and elegant integration with the K8s ecosystem are very attractive. It provides a lightweight GPU sharing and scheduling solution.
- HAMi's Hard Isolation: For scenarios with strict requirements for resource guarantees and performance stability.
Collaboration Outlook
VI. Community Dialogue and Future Outlook: Collaborative Development
KAI-Scheduler's GPU Sharing mechanism is undoubtedly an ingenious and commendable design. It demonstrates the ability to solve practical problems through scheduler innovation within the existing K8s system. Its clever use of K8s primitives provides the community with new ideas.
At the same time, we also see that for one of the core requirements of GPU sharing—reliable resource isolation and guarantees—KAI's "soft isolation" and HAMi's pursuit of "hard isolation" represent different technical paths and trade-offs.
Excitingly, we have already started active discussions with the Run:ai (Nvidia) team on these technical directions. At the recent KubeCon EU, we had productive discussions with the Run:ai CTO and his colleagues, particularly exchanging views on technical solutions for hard isolation, where HAMi shared our practices and thoughts. Both sides expressed enthusiasm for continued exploration in the field of GPU resource management and look forward to deeper technical exchanges and cooperation in the future.


A happy photo of the HAMi maintainer with Run:ai CTO Ronen Dar and his team at KubeCon EU.
We believe that the open-sourcing of KAI-Scheduler brings new vitality and choices to the community. It and the hard isolation solutions represented by HAMi are not mutually exclusive but can be seen as complementary, targeting different scenarios and needs. The scheduling innovations of KAI, combined with HAMi's exploration in hard isolation, may bring a more complete and flexible GPU virtualization solution to the community.
VII. Conclusion: Active Dialogue, Win-Win Cooperation, and a Shared Future
- KAI-Scheduler GPU Sharing: Elegantly designed, compatible with the K8s ecosystem, and cleverly implements scheduler-level fractional GPU management through Reservation Pods. However, it is essentially soft isolation and relies on application self-discipline.
- HAMi: Pursues hard isolation, providing mandatory resource limits and guarantees through the HAMi Device Plugin and HAMi-Core. It is better suited for production environments with high isolation requirements.
- Community and Collaboration: We applaud the technical innovation of the KAI team and welcome its open-sourcing. Through our active dialogue with the Run:ai (Nvidia) team at KubeCon EU, we see huge potential for community collaboration. The technical exchanges between us, especially the discussions on directions like hard isolation, signal the possibility of jointly advancing GPU resource management technology in the future.
The HAMi community will continue to follow the development of KAI-Scheduler and actively participate in community discussions. We look forward to working with partners, including Nvidia/Run:ai, to bring more powerful, flexible, and reliable GPU solutions to Kubernetes users.
Join the Discussion
What are your thoughts on KAI-Scheduler's GPU Sharing? In what scenarios do you think soft isolation and hard isolation are best suited? Feel free to leave your comments below or join our HAMi community to chat!
Thanks for reading! If you found this article helpful, please like, recommend, and share it with more friends!
HAMi, which stands for Heterogeneous AI Computing Virtualization Middleware, is a "one-stop" architecture designed to manage heterogeneous AI computing devices in a k8s cluster. It provides the ability to share heterogeneous AI devices and offers resource isolation between tasks. HAMi is dedicated to improving the utilization of heterogeneous computing devices in k8s clusters and providing a unified reuse interface for different types of heterogeneous devices. HAMi is currently a CNCF Sandbox project and has been included in the CNCF's CNAI technology landscape.
Community Website: https://project-hami.io
GitHub: https://github.com/Project-HAMi